Jan 2022-Model-augmented Prioritized Experience Replay
摘要:经验回放是非策略无模型强化学习(MfRL)的一个重要组成部分。由于抽样的有效性,人们提出了各种计算经验优先级得分的方法。由于critic网络对策略学习至关重要,与q值直接相关的TD-error是计算分数最常用的特征之一。
然而,critic网络经常低估或高估q值,因此通过严重依赖TD-error的采样经验来学习预测q值往往是无效的。因此,寻找能够支持TD-error的辅助特征来计算得分对于提高采样效率具有重要意义。
本文提出一种新的体验回放方法,称为模型增强的优先体验回放(MaPER),利用基于模型的强化学习(MbRL)中组件驱动的新可学习特征来计算经验得分。提出的MaPER通过critic网络更好地预测q值,实现了课程学习的效果。
与传统的PER相比,其内存和计算开销可以忽略不计。事实上,在不同任务上的实验结果表明,MaPER能够显著提高当前最先进的离线MfRL和包含离线MfRL算法的MbRL的策略优化性能。
1 INTRODUCTION
由于训练有素的critic网络会导致有效的政策学习,最流行的方法之一是利用预先定义的指标,根据时间差异误差(TD-error)对经验进行优先排序,这与critic网络的损失直接相关。基于TD-error (PER)的优先体验重放在q学习中确实证明了它的有效性
然而,测量q值需要预测回报的期望,而回报的期望可以通过多个步骤获得,因此学习预测q值通常需要与环境进行大量的交互。由于多步估计的难度,与均匀采样相比,仅基于高误差的采样可能往往是无效的,甚至会降低强化学习框架在某些任务上的采样效率
为了克服这个问题,一些工作试图设计基于学习的优先策略利用各种特征,包括由批评网络驱动的过渡元素和数量。本文的激励性观察是,现有方案中使用的所有可学习特征都来自批评网络。例如,尽管Zha等人(2019)利用了多种特征,例如奖励、TD-error和时间步长,但TD-error只能从批评网络中学习。
本文旨在通过利用critic网络之外的可学习辅助特征,开发一种新的优先策略,但可以支持TD-errors,以进行有效的critic训练。在基于模型的强化学习(MbRL)中考虑组件。
- 我们首先通过使用共享权重来预测奖励和transition来修改评论家网络,称之为模型增强评论家网络(MaCN)。
- 提出了一种改进的经验回放方案,即模型增强优先经验回放(MaPER),对既有高模型估计误差又有td -error的过去经验进行优先排序。也就是说,MaPER鼓励MaCN同时很好地预测q值和模型(即奖励和transition)。
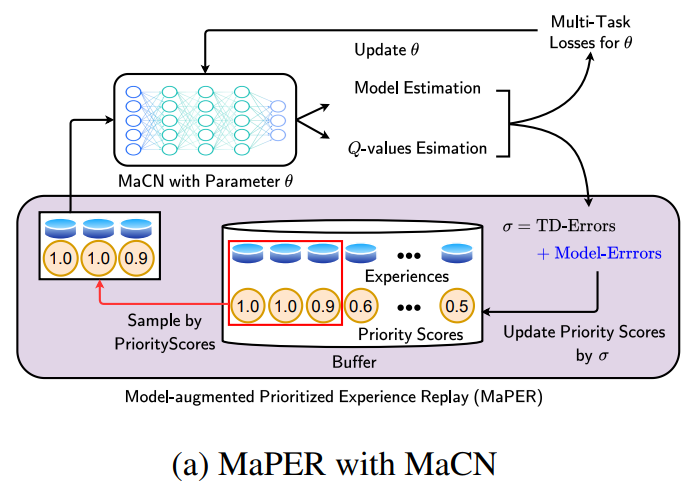
模型增强优先体验重放(MaPER)与模型增强批评器网络(MaCN)的高层示意图。MaCN通过MaPER在q值估计器和模型估计器之间获得更准确的q值估计
在这里,我们的 intuition是双重的:
- 我们预计,即使MaCN对q值的估计很差,对模型估计误差高的样本进行额外的优先级排序也有助于减少训练早期的模型误差。
- 当MaCN的模型误差较小时,MaPER倾向于选择td误差较大的样本。在这里,学习到的表征可以很好地预测模型,也可以用来预测q值,因为q值是由模型决定的
综上所述,我们的贡献如下:
- 本文提出了模型增强的优先经验回放(MaPER),在考虑模型估计误差的同时计算过去经验的优先分数。与单独学习q值相比,MaPER有助于更快地减少td -error。在与原始critic网络的参数数量相当的情况下,它导致了回报的大幅提高
- MaPER可以通过critic网络无缝集成到任何现代非策略RL框架中,包括MfRL(例如SAC、TD3和Rainbow)和MbRL(例如MBPO)方法,内存或计算开销可以忽略不计
据我们所知,现有方法中没有一种通过使用模型学习来改善强化学习的经验回放,尽管存在一些针对不同目的的相关工作,例如增加改进探索的奖励或增强基于像素的观察的表示学习
2 METHOD
2.1 PRELIMINARY
虽然所提出方法一般适用于具有q网络(即critic)的非策略强化学习方法,但在本节中,我们重点介绍非策略的actor-critic强化学习算法,该算法由策略(即actor) πΘ(a|s)和批评者网络Qθ(s, a)和经验回放缓冲区B组成,其中Θ和θ分别是它们的参数。
最常用的Qθ(s, a)的损失:

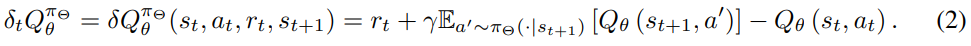
2.2 MODEL-AUGMENTED PRIORITIZED EXPERIENCE REPLAY (MAPER)
Model-augmented Critic Network (MaCN).
环境被描述为reward and transition分布,R(s,a)和T(s,a)。我们观察到reward and transition分布和Qθ(s,a)具有相同的输入域,即s×a,状态空间和行动空间的乘积
受其启发,我们将Qθ(s,a)略微修改为Cθ(s,a),通过参数共享并行地通过奖励模型Rθ(s,a)和transition模型Tθ(s,a)来预测环境。我们将Cθ(s,a)称为模型增强评论家网络(MaCN),使得Cθ = (Qθ,Rθ,Tθ)
在这里,Qθ用奖励估计Rθ测量q值来刺激探索。换句话说,我们使用估计的奖励来表述Qθ的损失,这类似于等式(1):
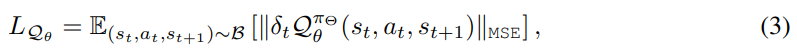
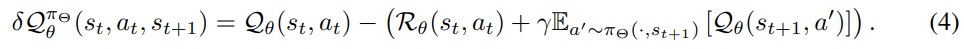
Rθ在损耗LQθ的反向传播中被分离:
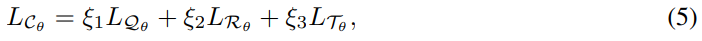
假设环境是确定性的,我们对Rθ和Tθ采用以下损失:
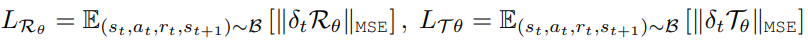
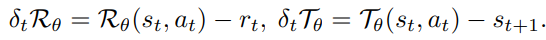
Formulation of MaPER
我们首先解释PER的概念,因为我们将使用基于模型的组件对其进行扩展。
在不丧失一般性的前提下,我们可以假设重播缓冲区B存储了以下信息作为它的第i次转移:
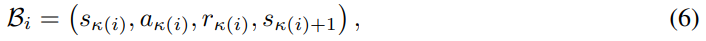
PER计算每个Bi的优先级σi作为自己最近计算的TD-error,并收集一组优先级分数:
每次为训练演员和评论家网络采样相应的转换时,每个优先级σi都会更新。

PER的采样策略是从优先级集定义的第i次转移的概率pi中确定[|B|]中的索引集I:

最后,我们计算重要抽样权值如下:

我们用MaCN设计了一个新的优先级分数方程。由于我们的方法使用Cθ(s, a)而不是原始的critic网络,因此我们相应地修改了公式(7)中获取缓冲区B中经验的优先级集的规则。将每个转换的优先级计算为td误差和模型误差,用(8)-(9)方程计算相应转移的概率和权值。如下:
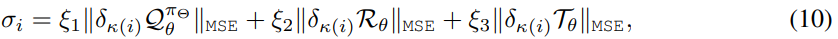
缓冲区可以从长期和短期的角度对MaCN有用的各种经验进行采样。框架MaPER的详细描述在算法1中提供

最后,与基本的PER相比,MaPER的计算开销可以忽略不计。
假设评论网络有一个线性层,其中N个隐藏单元作为最后一层。然后,我们可以计算MaCN和原始批评网络之间参数数量的差异:N(1 +|S|),其中S是批评网络中的(嵌入式)状态空间。请注意,额外参数的数量仅取决于评价网络中的最终隐藏单元。因此,与所有网络中的总参数和优先经验采样的计算成本相比,额外参数的计算成本较小
3 EXPERIMENT
在本节中,我们通过实验来回答以下问题:
•所提出的方法能否在各种环境中增强具有Q-networks的各种离线强化学习算法的性能?
•我们的方法成功的最大原因是什么?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号