Sep 2022-Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
摘要:对网络规模的数据进行训练可能需要数月时间。但大多数计算和时间都浪费在已经学习或无法学习的冗余和噪声点上。为加速训练,本文提出了Reducible Holdout Loss Selection (RHOLOSS),一种简单但有原则的技术,近似地选择那些最能减少模型泛化损失的点进行训练。因此,rho损失缓解了现有数据选择方法的弱点:来自优化文献的技术通常选择“硬”(例如高损失)点,但这些点往往是有噪声的(不可学习)或与任务相关性较低。相反,课程学习优先考虑“容易”的点,但这些点一旦学习就无需再进行训练。相反,RHO-LOSS选择的是可学习的、值得学习的、尚未学习的点。RHO-LOSS的训练步骤比现有技术少得多,提高了准确性,并加快了在广泛的数据集、超参数和架构(mlp、cnn和BERT)上的训练。在大型网络抓取的图像数据集Clothing-1M上,ro - loss训练的步骤减少了18倍,并达到了比均匀数据洗濯高2%的最终精度
1. Introduction
许多网络抓取的样本是有噪声的,即它们的标签不正确或本质上是模糊的。例如,与网络抓取的图像相关联的文本很少能准确地描述图像。其他样本被快速学习,然后变得冗余。
对于哪些数据点是最有用的,还没有达成共识。包括课程学习在内的一些工作建议,在对所有点进行同等训练之前,优先考虑具有低标签噪声的容易的点。虽然这种方法可能提高收敛性和泛化性,但它缺乏一种跳过已经学习的点(冗余)的机制。其他工作则建议在模型难以训练的点上进行训练,从而避免无法进一步减少损失的冗余点。在线批量选择方法通过选择具有高损失或高梯度范数的点来实现这一点。
展示了两种优先处理困难例子的失败模式。
- 首先,在现实世界的噪声数据集中,高损失样本可能被错误标记或模糊。实际上,在控制实验中,高损失或梯度范数选择的点绝大多数是那些具有噪声污染标签的点。我们的结果表明,这种失效模式严重降低了性能。
- 更微妙的是,我们表明一些样本是困难的,因为它们是异常值,即具有不寻常特征的点,在测试时不太可能出现。以减少测试损失为目的,这些点不太值得学习。
为克服这些限制,本文提出了可减少的拒绝损失选择(RHO-LOSS)。本文提出一种基于概率建模的选择函数,通过在不进行实际训练的情况下对每个点减少泛化损失的程度进行量化。减少抵制损失的最佳点是无噪声、无冗余且与任务相关的。为了近似最优选择,我们推导了一个高效且易于实现的选择函数:可降低的holdout loss
2. Background: Online Batch Selection
考虑一个模型p(y|x;θ)使用参数θ对数据D = {(xi, yi)}n i =1使用随机梯度下降法(SGD)进行训练。在每个训练步骤t,我们从D加载大小为nb的批次bt。
在在线批量选择中,我们均匀预采样大小为nB(>nb)的更大批次Bt。然后,构建一个较小的批量bt,由Bt中排名靠前的nb点组成,并通过标签感知选择函数S(xi,yi)进行排序。我们执行梯度步骤以最小化小批量损失L(yi, p(yi|xi;θ))对i∈bt求和。然后从D中预采样下一批Bt+1,D不替换之前的采样点(即随机洗牌:在下一个epoch开始时进行替换)
3. Reducible Holdout Loss Selection
之前的在线批量选择方法,如损失或梯度范数选择,旨在选择一些点,如果我们要对它们进行训练,则将训练集损失最小化。相反,我们的目标是选择在a holdout set上损失最小的点。单纯地对每个候选点进行训练并每次评估holdout-loss,代价太大。在本节中,我们将展示如何(近似地)找到在不进行实际训练的情况下,在这些点上训练当前模型的情况下,最能减少holdout-loss的点。
为简单起见,我们首先假设在每个时间步t只选择一个点(x, y)∈Bt进行训练(我们在下面讨论多个点的选择)。P(y'|x';Dt)是当前的预测分布模型,其中Dt是在训练步骤t之前训练序列的数据模型。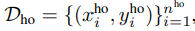 ,写成x ho和y ho简洁,是一组holdout来自相同的数据生成分布ptrue(x', y')作为训练集D。我们的目标是获得点(x, y)∈Bt,如果我们要用它来训练,将在holdout set上最小化负对数似然/交叉熵损失:
,写成x ho和y ho简洁,是一组holdout来自相同的数据生成分布ptrue(x', y')作为训练集D。我们的目标是获得点(x, y)∈Bt,如果我们要用它来训练,将在holdout set上最小化负对数似然/交叉熵损失:
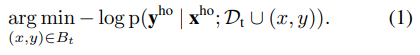
holdout损失因子分解,并(直到一个常数因子)形成在ptrue下预期损失的蒙特卡罗近似:

推导一个可处理的选择函数
利用Bayes准则和条件独立性p(yi|xi, xj;= p(yi | xi;Dt),我们可以从等式(1)推导出一个易于处理的选择函数。为了可读性,我们切换选择函数的符号,稍后将最小化更改为最大化。
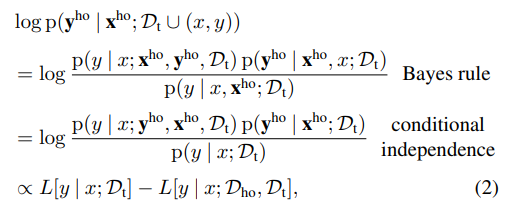
近似1:
由于神经网络中很难进行精确的贝叶斯推理(以Dt或Dho为条件),因此我们用SGD拟合模型。(在4.1节中研究这种近似的影响)。
第一项,L[y|x;Dt],则是使用在Dt上训练的当前模型在点(x, y)上的训练损失。
第二项,L[y|x;Dho,Dt]是在Dt和Dho上训练的模型的损失
近似2
尽管Eq.(2)中的选择函数是可处理的,但计算起来仍然有些昂贵,因为在每次获取新点后,两个项都必须更新。然而,我们可以用只在holdout数据集上训练的模型来近似第二项,L[y|x;Dho, Dt]≈ L[y|x;Dho]。这种近似节省了大量计算:现在在第一阶段训练之前计算一次术语就足够了。根据经验,这种近似不会影响任何测试数据集的性能,甚至具有一些所需的属性
我们将L[y|x;Dho]不可减少的抵抗损失(IL),因为它是在抵抗集合Dho上训练后在点(x, y)∈D上的剩余损失;在Dho很大的限制下,这将是模型在不训练(x, y)的情况下可以达到的最低损失
我们将等式(2)的近似称reducible holdout loss-训练损失和irreducible holdout loss(IL)(不可减少的抵抗损失)之间的差异
近似3
本文方法仍然需要我们在holdout set上训练模型,但最终的近似大大降低了成本。我们可以使用“不可减少损失模型”(IL模型)有效地计算IL,该模型比目标模型小且精度低(近似为3)。
综上所述,对于在Dt上训练的模型,在Eq.(1)中选择一个最小化holdout loss的点,可近似为以下易于计算的目标:

虽然我们需要额外的数据Dho,但对于大型(第4.0节)或小型(第4.2节)数据集来说,这不是必需的
Understanding reducible loss
本文对为什么可减少的hold loss选择(RHOLOSS)可以避免冗余、噪声和不太相关的点提供了直观的认识。
i)冗余点。
当模型已经学习过一个训练点时,我们称它为冗余,即它的训练损失无法进一步减少。由于冗余点具有较低的训练损失,且reducing loss总是小于training loss(式(3)),因此这些点具有较低的reducing loss,因此不被选择。如果模型忘记了它们,它们会在下一个epoch中被重新访问。
ii)噪声点
虽然之前的方法是基于高训练损失(或梯度范数)进行选择的,但并非所有高损失的点都是有信息的——有些可能具有模糊或不正确(即噪声)的标签。使用保留集无法预测这些点的标签。这些点有高的IL,因此,降低损失。与噪声较小的等效点相比,这些噪声点不太可能被选中
iii)相关点较少
基于损失的选择还有一个额外的陷阱。在ptrue(x)下的低输入密度区域中,对于输入空间中的离群点x(值x远离大多数训练数据),训练损失可能更高。在其他条件相同的情况下,ptrue(x)较低的点不应该被优先排序。
考虑一个“异常值”(x, y)和一个非异常值(x',y'), ptrue(x) <ptrue(x'),但训练损失相等L[y|x;Dt] = L[y'|x';Dt]。由于holdout集Dho也来自ptrue,因此与x'附近的区域相比,Dho将包含来自输入空间中x附近区域的更少的点。因此,在(x, y)上训练可能会更少地减少holdout loss(等式(1)),因此我们更喜欢在非异常值(x', y')上训练。在描述的特定意义上,(x,y)因此与holdout set具有低相关性。正如所期望的那样,RHO-LOSS会降低(x, y)的优先级:由于Dho包含来自x周围区域的少量点,因此(x,y)的IL会很大
Selecting multiple points concurrently
当选择单个点(x, y)时,我们展示了哪个点是最优的。当选择整个批bt时,我们从随机预采样集Bt中选择具有top-nb分数的点。当假设每个点对其他点的分数几乎没有影响时,这几乎是最优的,这通常用于主动学习中的简化假设。在我们的例子中,这个假设比主动学习更合理,因为在一个小批量上,模型预测不会被一个梯度步骤改变太多。
Simple parallelized selection
随着更多的works以同步或异步梯度下降的方式添加,回报减少到一个点,即增加更多的工人并不能进一步改善时钟时间。我们可以通过增加一个新的并行化维度来规避这些收益递减问题,即数据选择
由于并行前向传递不会受到这种收益递减的影响,因此可以使用额外的work来并行评估训练损失。理论上的运行时加速比可以理解为:在Bt上计算选择函数的每个训练步骤的成本是在bt上训练前向后传球所需成本的nB/3nb倍,因为前向传球所需的计算量至少比前向后传球少3倍。人们可以通过添加更多的worker来几乎任意地减少选择阶段的时间,这些worker使用正在训练的模型的副本来计算训练损失。当选择的时间被参数更新与work的通信所支配时,就达到了极限。更复杂的并行化策略可以进一步减少时间开销(第5节)。
Algorithm


 浙公网安备 33010602011771号
浙公网安备 33010602011771号