

May 2022-Neighborhood Mixup Experience Replay: Local Convex Interpolation for Improved Sample Efficiency in Continuous Control Tasks
摘要:经验回放在提高深度强化学习智能体的样本效率方面起着至关重要的作用。经验回放的最新进展建议使用Mixup-2018,通过合成样本生成进一步提高样本效率。
在这种技术的基础上,提出了邻域混合经验回放(NMER),一种基于几何的回放缓冲区,用状态-动作空间中最近邻的转换进行插值。NMER仅通过混合转换与邻近状态-动作特征来保持转换流形的局部线性近似。在NMER下,给定transition的状态-动作邻居集是动态的和情节无关的,通过情节间插值鼓励更大的策略泛化性。将所提出方法与最近的非策略深度强化学习算法相结合,在连续控制环境下进行评估。NMER比基线重放缓冲区平均提高了94% (TD3)和29% (SAC)的样本效率,使智能体能够有效地重组以前的经验并从有限的数据中学习
1. Introduction
本文旨在将MF-DRL(model-free)中对真实环境交互的学习优势与MB-DRL(model-based)的样本效率优势结合起来。本文提出邻域混合经验重放(NMER),一种模块化的重放缓冲区,通过对从重放缓冲区中邻域过渡的凸线性组合中采样的经验进行训练,提高了off-policy、MF-DRL智能体的样本效率。
我们的贡献总结如下:
- 邻域混合经验重放(NMER):一种geometrically-grounded的重放缓冲,通过训练这些代理在邻近transition的线性组合上,提高了off-policy的MF-DRL代理的样本效率。
- 局部混合(Local Mixup): NMER的一种推广,该算法考虑了任意特征空间中邻域点之间的混合,用距离度量来定义邻近度。
- 在连续控制中提高样本效率:评估研究表明,NMER大大提高了跨几种连续控制环境的off-policy、MF-DRL算法的样本效率
2. Related work
经验回放、数据增强和插值方法已应用于强化学习和其他机器学习领域。NMER建立在这些技术的基础上,以提高样品效率
3. Preliminaries
邻域混淆经验重放(NMER)建立在非策略DRL的经验重放的基础上,Mixup和最近邻启发式(nearest neighbor heuristics),以鼓励近似流形插值。
Off-policy DRL for continuous control tasks
off-policy DRL已经成功地应用于连续控制任务,通过使用actor-critic方法,如软行为者批评(SAC),深度确定性策略梯度(DDPG)和双延迟DDPG (TD3)
Experience replay
它可以在很大程度上与智能体的训练算法解耦——当智能体寻求在给定观察到的训练样本的情况下学习最优的策略和值函数时,无论提供给它的样本是什么,经验回放缓冲区的任务是提供具有最大“可学习性”的智能体样本,以改进这些策略和值函数。
Mixup
Mixup是一种新的随机数据增强技术,通过在现有样本的凸线性组合上训练监督学习器,提高其泛化能力。
MixUp:使用两个现有的样本x1, x2∈rd来插值一个新的样本xinterpolated, Mixup按照以下方式进行插值:

On-manifold interpolation
为了衡量插值经验回放方法中的插值精度,考虑了插值转换相对于映射状态和动作到奖励和下一个状态的转换流形的"上流形"程度。

使用Mixup的on and off-transition流形插值示例。流形或近似流形插值是连续控制任务中成功训练DRL智能体的关键。
4. Neighborhood Mixup Experience Replay (NMER)
NMER使用智能体现有的近端经验的凸线性组合来训练off-policy MF-DRL智能体,有效地创建以重放缓冲区的每个transition为中心的局部线性模型。通过仅插值相邻的transition,其中邻近性由回放缓冲区的状态-动作空间中的标准化欧氏距离衡量,NMER插值具有相似状态和动作输入,但潜在不同奖励和下一个状态输出的转换。在考虑这些最近邻时,NMER通过允许邻近transition之间的inter-episode插值来正则化其训练的off-policy MF-DRL智能体。此外,在转换流形中存在随机性的情况下,NMER可以通过为几乎相同的(状态,动作)输入插值不同的(奖励,下一个状态)结果,防止这些智能体过拟合特定的(奖励,下一个状态)结果。
NMER由两个步骤组成:
-
更新步骤:当一个新的环境交互被添加到回放缓冲区时,重新标准化回放缓冲区中存储的转换的状态和动作,并使用Z-score标准化的欧氏距离更新最近邻数据结构,连接回放缓冲区的状态-动作特征。因此,在输入状态和动作空间上进行相似性搜索;NMER也可以允许其他距离函数和相似性表示。
-
采样步骤:首先,从replay buffer中均匀采样一批“sample transitions”。接下来,查询采样批次中每个transitions的最近邻居。接下来,对于训练批次中的每组邻居,从这组邻居中均匀采样一个邻居transition,并应用Mixup对所选的每对样本和邻居(分别为xsample,i和xneighbor,i)进行线性插值:
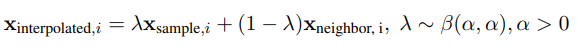
与标准体验回放相比,NMER引入了最小的计算开销,只需要矢量化标准化、最近邻查询和本地Mixup操作。这将NMER定位为高维连续控制任务的可行经验回放缓冲区。
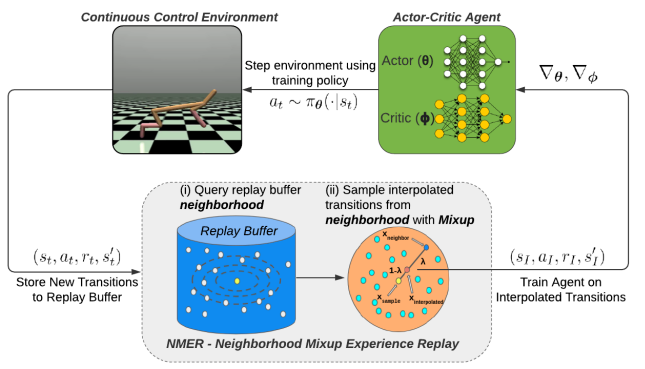
使用NMER,在采样transition与其相邻transition之间进行凸插值,提高了off-policy, MF-DRL代理应用于连续控制任务的泛化性和鲁棒性。
Algorithm 1:

对于每一步:
均匀采样到一个transition ss,标准化状态和动作、标准化局部邻居
从局部邻居set中采样一个transition sn
提取ss和sn的特征xs、xn,进行mixup生成xi插值,添加到B训练集
通过线性插值实现Agent正则化:
NMER通过调用状态-动作对的线性组合会导致相应的奖励-下一个状态对的相同线性组合的先验知识,提高了off-policy、MF-DRL智能体的策略和值函数近似器的泛化能力。这种先验提高了在近似满足线性假设的任务中的泛化能力。
由于连续控制任务中的智能体空间是连续的,因此需要进行插值连续的,线性的transition组合仍然可以产生靠近underlying transition流形T的插值样本。如果transition流形T是凸的,则NMER保证流形内插,因为该技术生成严格的凸过渡组合。在这种情况下,合成生成的流形转换与使用底层环境动力学在同一点生成的转换是无法区分的。然而,对于许多应用,特别是高维的、现实世界的连续控制任务,底层的转换流形通常是非凸的。
邻域混淆作为鼓励流形上插值的启发式方法:
连续控制环境中的非凸性和非线性为基于邻域的插值机制提供了动力,该机制通过仅考虑同一"邻域"中transition之间的插值来解决transition流形的非凸性问题,即具有相似状态-动作对的tranaition。如果transition流形是局部欧氏的,线性插值两个过渡是一个合适的,近似在流形上的机制,用于在空间近端transition之间进行插值。

