
May 2022-Composite Experience Replay-Based Deep Reinforcement Learning With Application in Wind Farm Control
摘要:本文提出了一种基于深度强化学习(RL)的控制方法,以提高学习效率和效果来解决风电场控制问题。具体地,设计了一种新的复合体验重放(CER)策略,并将其嵌入到深度确定性策略梯度(DDPG)算法中。CER提供了一种新的采样方案,通过在奖励和时间差异(TD)误差之间进行权衡,可以深入挖掘存储变迁的信息。在神经网络的训练过程中引入修正的重要性-采样权重,以解决CER导致的分布不匹配问题。然后,将CER-DDPG方法应用于风电场总发电量优化。
I. INTRODUCTION
A. Deep Reinforcement Learning-Based Control
与原始DDPG相比,直接移植PER到DDPG可能不会获得太多(甚至会导致性能下降)。这是因为PER最初是为DQN设计的,其中只有动作状态值函数(即Q函数)是近似的。TD误差直接用于驱动这个近似过程,使其完美地满足优先级的目的。然而,与DQN相比,DDPG有一个额外的actor来生成连续的控制策略。因此,DDPG转换的优先级需要重新设计因为TD误差对actor的重要性是值得怀疑的。
B. Control of Wind Farm
【略去;不在我的研究范围内】
C. Our Contributions
在DDPG框架中引入了一种新的采样策略。我们将其命名为复合经验回放(CER),因为它不仅利用了TD误差的信息,还利用了奖励来对训练批次进行采样,在这里,奖励被用来衡量转换相对于执行器网络的优先级。这种设计基于这样的观察,即执行器网络的更新是由策略梯度算法中的奖励隐式驱动的。
策略梯度算法的早期版本【REINFORCE】直接使用奖励进行训练。CER有能力平衡两组优先级(即TD错误和奖励),在critic和actor的学习之间进行权衡。此外,采用基于复合优先级的修正重要性采样权重(modified importancesampling weights, ISWs)来修正CER中由于分布不匹配引起的偏差。
II. DESIGN OF DEEP DETERMINISTIC POLICY GRADIENT WITH COMPOSITE EXPERIENCE REPLAY
A. Algorithm Overview
它包括几部分: DDPG, CER, reward regularization, and the
wind farm

B. Deep Deterministic Policy Gradient
main critic network的更新是由以下损失函数驱动的:

n表示每个训练步骤所选样本的批大小
ωi是第i个样本的重要权值,在CER设计中给出了它的具体表达式
δi为第i个样本的TD误差:
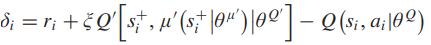
main actor的更新通过policy gradient策略:

C. Composite Experience Replay
需要定义transition的采样优先级。
一方面,TD误差直接参与了critic的损失构建。即可以衡量相应的transition对于critic来说有多“surprise”。
另一方面,行动者受到rewards的隐性驱动。rewards是transition优先级目的的适当选择。
基于以上,在CER中存储了两组优先级:
- 第一组优先级是基于TD-error的:
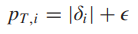
- 另一组优先级是基于rewards:
为了确保PR中的所有优先级都是有效的概率,我们需要将奖励空间从R投影到R+;实现这一目标的一个简单方法是设置:
R可能需要被投影到一个有界的区间:
即,基于projected的奖励,我们将PR中的优先级设计为:
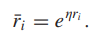
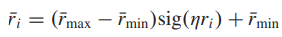

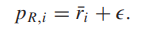
由于transition由两组优先级采样,因此需要解决重复问题。
其中,在小批量B中,li = 1,表示transition只进行PT采样;li = 2表示仅用PR对transition进行采样;最后,li = 3表示同时对transition进行PT和PR采样
基于这些标签,CER确保B中所有的transition都是不同的,无论它们是否在采样过程中重复
偏差修正:期望值的估计依赖于与期望相同的分布对应的更新。CER和其他优先级抽样策略(例如PER)改变了这种分布
ISWs可用于CER中,以缓解因分布不匹配而导致的潜在估计偏差。与PER不同,CER中的ISWs与相应transition的重复条件有关。
CER实质上通过PT和PR构建了两组平行的transition,即T组和R组,在组T和组R中都没有内部重复。因此,对于只在组T或组R中的transition,它们的isw直接由它们的采样概率决定:
对于T组和R,它们的isw是原始isw的线性组合:
无论在两个组中重复多少次transition,CER都确保最终的minibatch B始终具有固定的大小,并且B中的transition都彼此不同。



Algorithm 1 CER

对于每次采样:初始化参数为0
采样BT batch:从BT中根据TD-error优先采样[1-a]n个transition,并设置它们的l=1;和w
采样BR batch:进入while循环:直到采样transition的个数满足于B minibatch结束
从buffer里根据rewards采样一个transition:
- 如果这个transition的l=0【说明没有被采样过】,设置其l=2,w,并把它放入BR batch中,其数量+1
- 如果这个transition的l=1【说明被BT采样过】,设置其l=3,调整ISW:w
- 如果这个transition的l=2、3【说明被BR采集过或者BR和BT共享的】,忽略并重新采样
总数量到达采样N,连接BT和BR成为B minibatch

