
Jan 2022-Actor-critic with familiarity-based trajectory experience replay
摘要:
深度强化学习通过智能体与环境进行交互获取原始输入信息,从而学习动作策略,通过不断地试错逐步形成具有强大学习能力的智能体。本文旨在解决深度强化学习中著名的异步优势行动者评论家算法A3C样本效率低下的问题。首先,设计了一种新的离策略actor-critic算法,该算法在在策略actor-critic算法中加入了经验池,并采用离策略和在策略相结合的更新机制提高样本效率。其次,研究了轨迹经验的经验回放方法,提出了一种以经验回放次数作为采样概率权重的基于熟悉度的回放机制FRM(familiarity-based replay mechanism)。最后,还使用了GAE-V方法纠正离策略学习造成的偏差。在Atari和MuJoCo基准任务上的实验结果表明:本文提出的每项改进均有助于提高算法的样本效率和最终性能,同时本方法保持了与A3C相同的快速收敛和并行特性,具有更好的探索能力。
1. Introduction
本文的主要贡献如下:
- 我们提出了一种off-policy actor-critic算法,该算法使用经验回放来提高数据效率,并使用GAE-V来纠正非政策经验带来的偏见
- 我们提出了可以与轨迹经验相结合的FRM,以提高数据效率
- 我们在Atari和MuJoCo上对算法进行了评估[13],结果表明我们的算法比A3C和Advantage Actor-Critic (A2C)算法具有更高的数据效率和更好的性能。同时,我们的算法保留了A3C的并行特性、低硬件要求和更快的收敛速度等优点
2. Related Works
提高强化学习算法的样本效率是近年来研究工作的重点之一
结合经验回放的Actor-Critic (ACER)将政策内的Actor-Critic和经验回放相结合,同时利用政策内和政策外的经验,这些经验将同时用于学习中。
深度确定性脱策略梯度(DD-OPG)是一种确定性策略梯度算法,它利用重要性采样的惩罚来纠正非策略样本的偏差,以提高数据效率,但其优先重放机制仅依赖于累积奖励且仅在一系列简单的连续控制任务上进行评估
我们提出的方法与上述几种方法不同,主要体现在以下几个方面:
我们的方法只估计一个值函数,而不学习q函数
该方法可以对轨迹经验进行采样,而不是对单次跃迁进行采样。
我们的方法仅使用GAE-V方法和剪切重要抽样方法来纠正非政策样本的偏差,而不涉及任何其他代理模型。
我们的方法对离散任务和连续任务都能很好地工作。
3. Background
强化学习基本理论公式
4. Off-policy Actor-Critic
4.1. Familiarity-based Trajectory Experience Replay
4.1.1. Shared Trajectory Experience Replay Buffer
经验回放机制优点:算法不仅可以利用最近的经验来更新神经网络,而且可以重用一些有价值的经验。同时,变迁之间的相关性也会被打破。
DQN将此过渡视为单个体验并将其存储在重播缓冲区中。但与DQN不同的是,A3C需要使用轨迹的连续样本来更新网络,所以我们不能使用与DQN相同的经验形式。
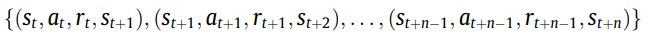
我们在线程之间使用共享的经验回放缓冲区,而不是单独的经验回放缓冲区
4.1.2. Familiarity-based Replay Mechanism (FRM)
回放缓冲区中存储的经验形式是轨迹,这是不可能得到每个经验的TD-error,如DQN。因此,我们只能得到整个轨迹的TD-error的最大值、最小值和平均值。我们使用这些值作为每个轨迹的重要性表示。我们还将这些值以不同的形式结合起来作为经验优先级,但这种方法并不能使算法得到明显的改进。
本文提出了一种更简单、更直接的采样机制。认为采样次数少的经验应该有更高的机会被再次采样。即试图帮助agent “熟悉”那些“不熟悉”的经验。在本文中,我们使用一个变量作为熟悉度来记录每次体验的采样次数。当经验被采样时,相应的变量会自我增加;
随着经验采样次数的增加,下一次经验的采样概率会降低。这种思路类似于上置信度界方法。使用上述方法,每个体验的优先级是:

4.1.3. Off-policy Update

在A3C中,当智能体与环境进行固定步数的交互后,智能体会使用 the multi-step trajectory 更新网络的参数。我们还使用on-policy trajectory来更新网络,如A3C,并且此轨迹不会立即保存在replay buffer中作为体验。
在使用replay buffer中的历史轨迹更新网络后,当前轨迹将被存储到replay buffer中。当使用的on-policy trajectory经验更新网络时,由于这些经验是由current behavior policy生成的,因此不需要使用重要性采样。当经验从回放缓冲区中采样时,我们只使用重要性采样率和裁剪机制。
4.2. GAE and V-trace
GAE可以看作是一个重塑的回报函数,它是一个带有折现因子ck的折现累积回报函数。因此,GAE在actor-critic中的方差和偏差之间提供了很好的平衡,使用GAE来估计优势函数可以更有效。


