


lec-6-Actor-Critic Algorithms
从PG→Policy evaluation
- 更多样本的均值+Causality+Baseline 减少variance
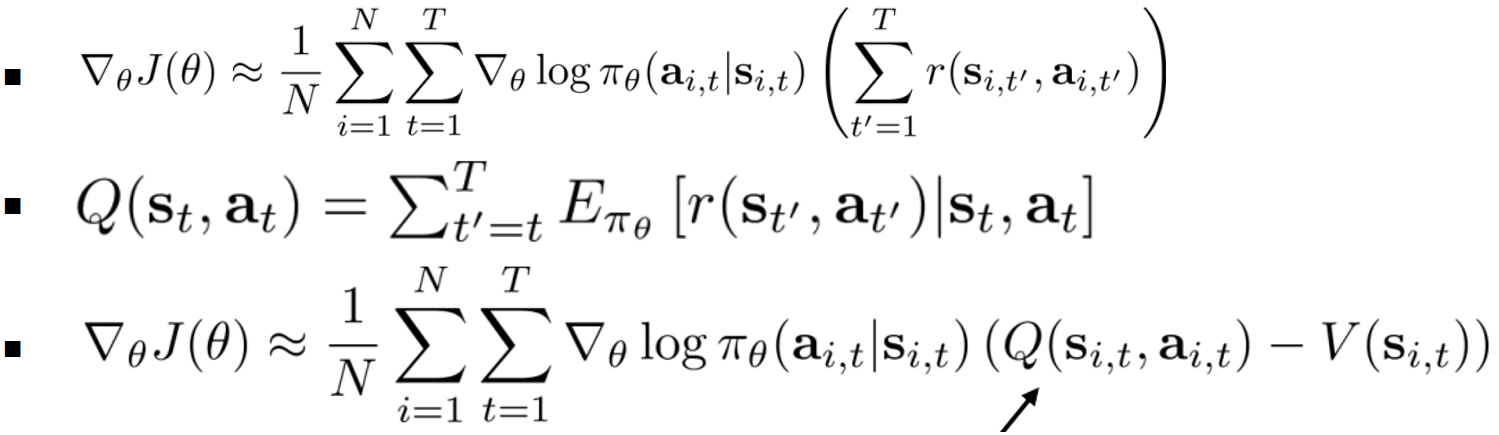
- 只要拟合估计Q、V:这需要两个网络
- Value function fitting(即策略评估)
近似: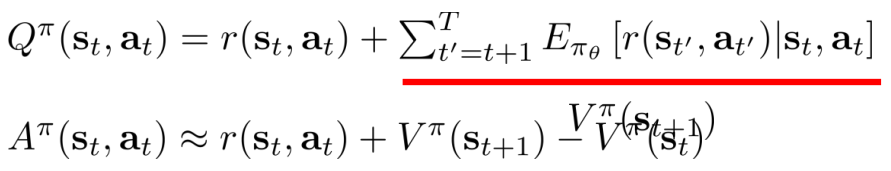
- MC evaluation
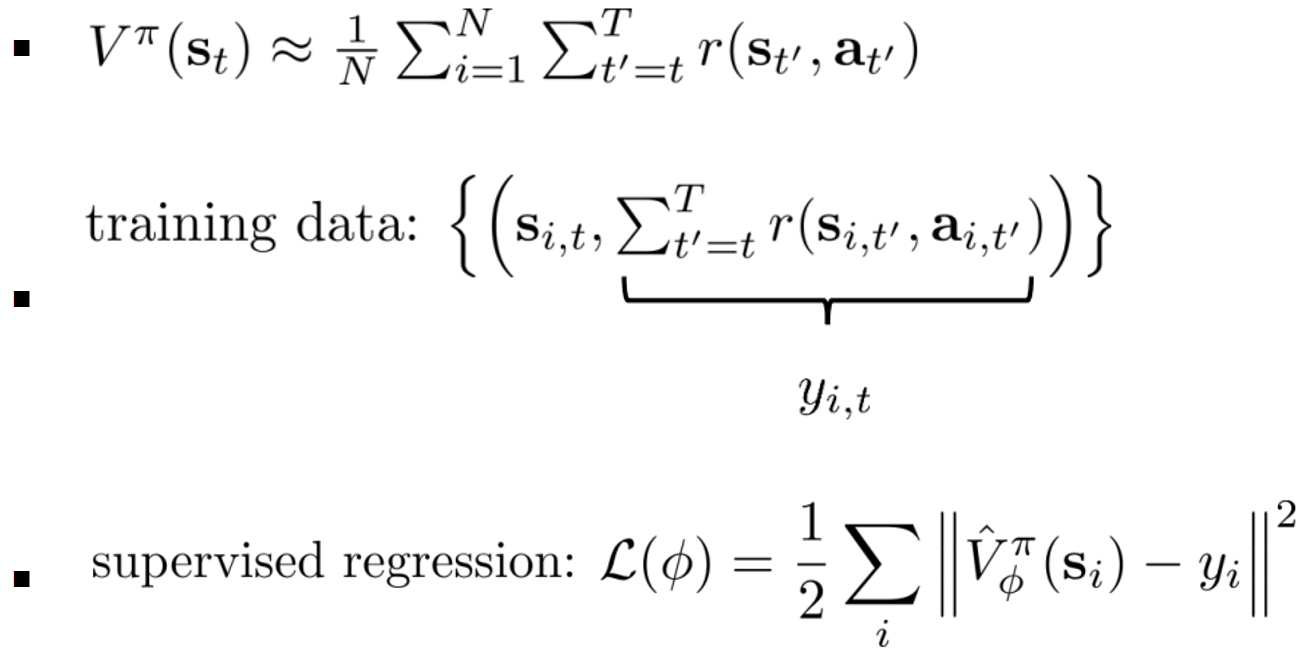
一种更好的方法:自举
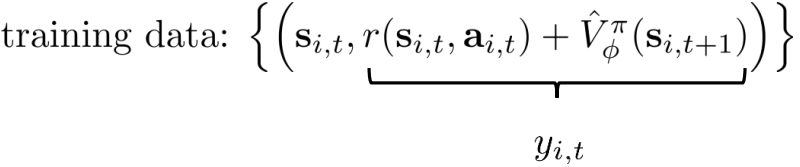
从evaluation→AC
-
拟合V进行评估,提升policy

- V网络的更新:
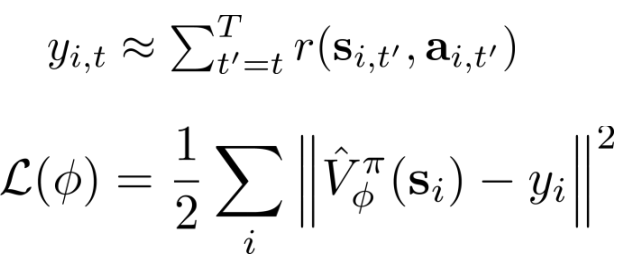
- 策略网络policy的更新:
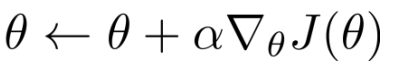
- V网络的更新:
-
在RL基本流程图中:
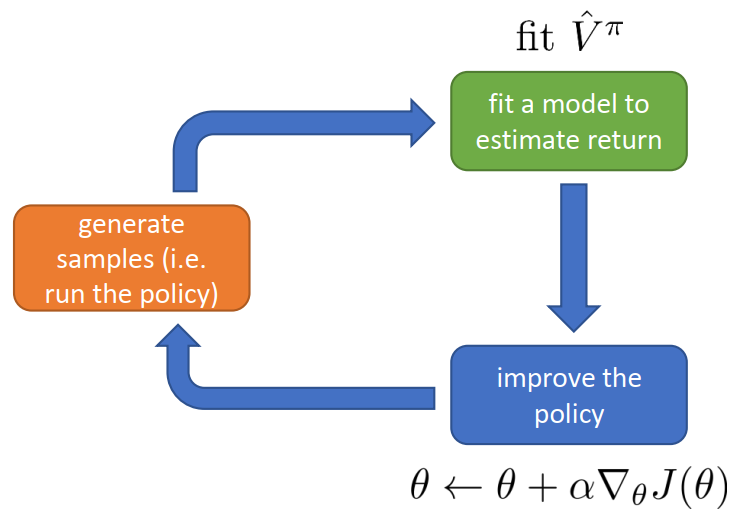
-
改进方法
- 折扣因子:对近期回报的偏好程度
- 折扣因子(MC方法)的分配:
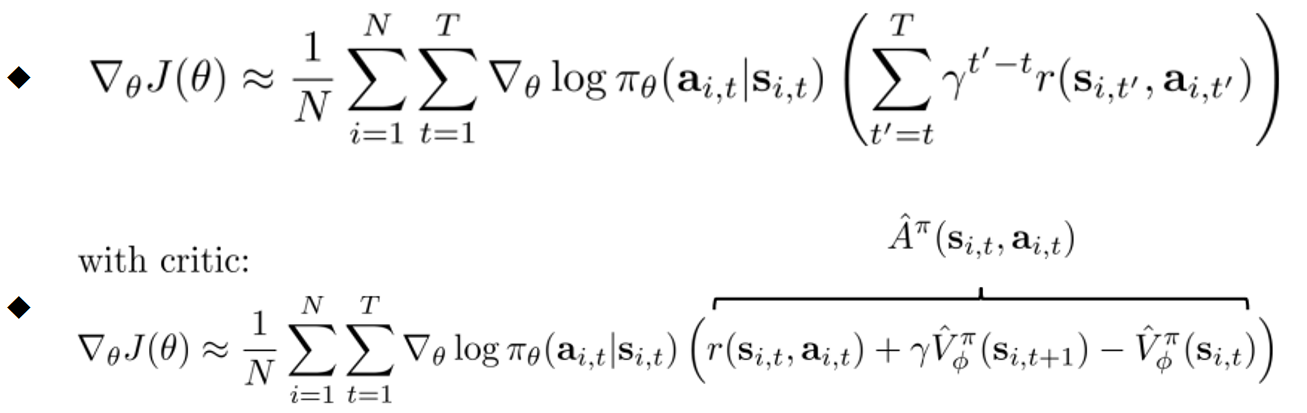
-
改进设计
- 网络架构设计:两个独立网络变成共享网络(共享内部信息来加快训练速度)
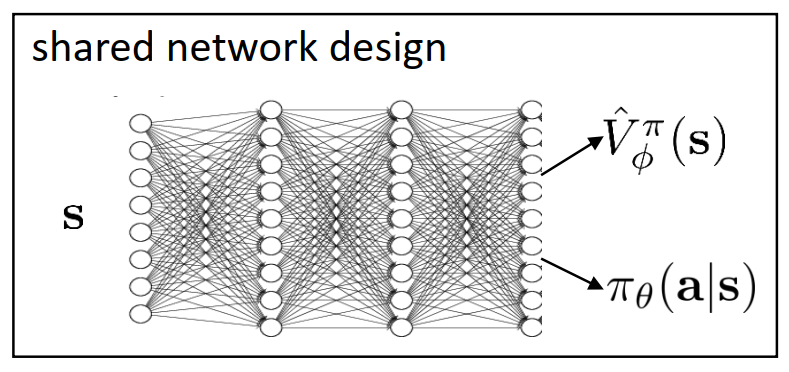
- Online
- 同步并行A2C
- 异步并行A3C
- Offline
- Replay buffer
- 网络架构设计:两个独立网络变成共享网络(共享内部信息来加快训练速度)
-
Critics(V) as baselines
- 状态独立baselines(单个样本的期望估计-V):无偏,低variance
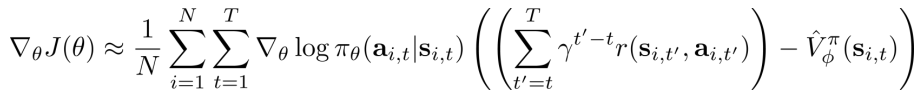
- AC:低variance,有偏(目标值和估计值都由V影响)
- PG:高variance(单样本估计),无偏
- 动作独立的baselines: 会出现不正确的
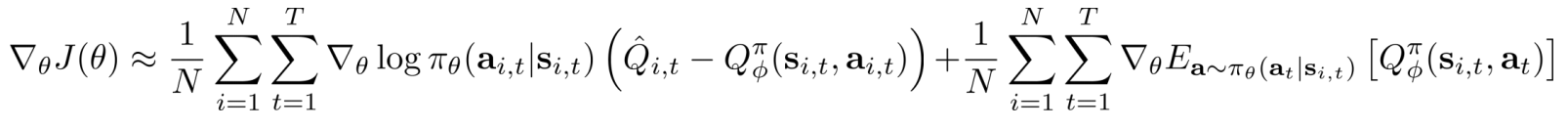
- n-step returns
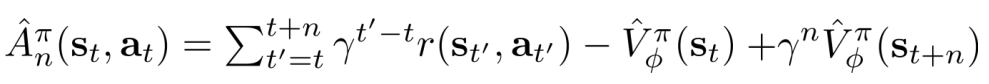
- n越大,偏差越小,方差越高
- GAE

- 状态独立baselines(单个样本的期望估计-V):无偏,低variance
Resource:CS285官网资料
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权;转载或者引用本文内容请注明来源及原作者

