lec-4-Introduction to Reinforcement Learning
模仿学习imitation learning与RL的不同
- 模仿学习中需要有专家指导的信息
- RL不需要访问专家信息
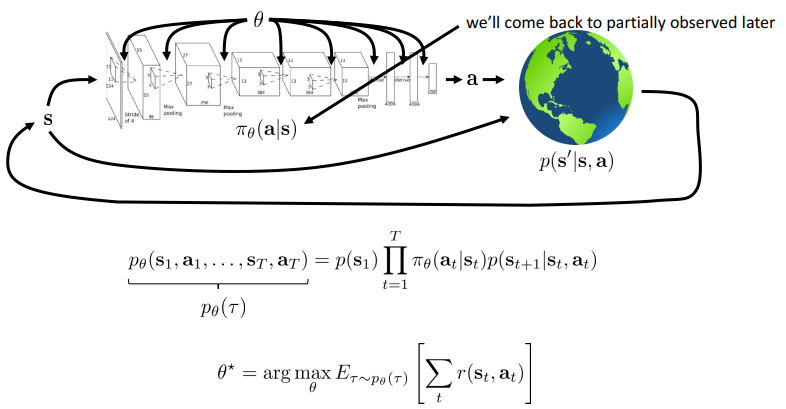
RL Definitions
- 奖励函数
- 马尔科夫决策链
- 只与上一个状态有关
- 目的
- 空间
- 有限
- 可找到最优参数
- 无限
- 证明p的概率分布是个平稳分布stationary distribution
- 有限
- 期望
- 由于奖励函数是不平滑的
- 转换: 但是可以优化 看似不平滑甚至稀疏的奖励功能(不平滑or不可微的期望) 在可微且平稳的概率下的函数
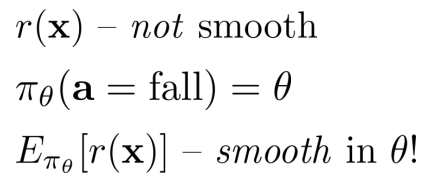
- 转换: 但是可以优化 看似不平滑甚至稀疏的奖励功能(不平滑or不可微的期望) 在可微且平稳的概率下的函数
- 由于奖励函数是不平滑的
算法
-
基本过程:
- 生成样本→调整模型/估计回报(评估policy)→提升策略policy→生成样本
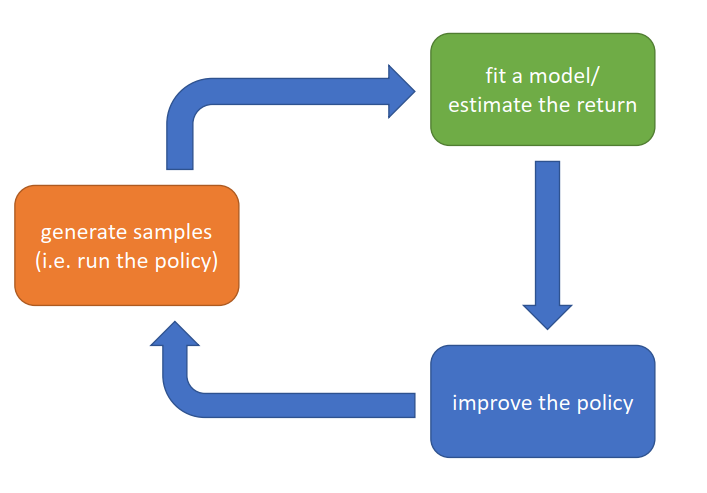
- 各部分代价
- 生成样本
Expensive:真实环境进行一次,也许代价会很高,机器人、车、电网等
cheap:模拟环境 - 评估policy
expensive:学习神经网络大量参数
cheap:MC等求均值等 - 提升policy
expensive:反向传播大量参数求导
cheap:回报均值梯度求导更新
- 生成样本
- 生成样本→调整模型/估计回报(评估policy)→提升策略policy→生成样本
-
Value Functions(基于值的)
- 核心:第二步(评估policy)使用Q-function or value function
- 定义
- 期望:
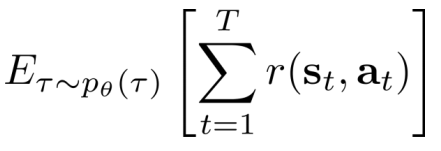
- Q-function:
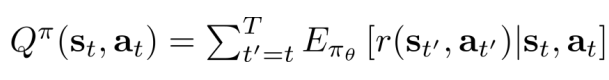
- Value function:
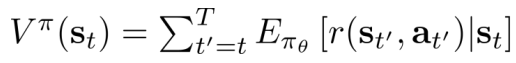
- 关系:
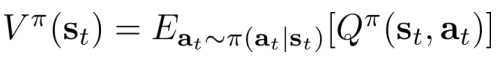
- Idea:
Policy iteration:Policy+Q-function → improve policy
比较QandV,if Q>V, 计算梯度增加动作概率
- 期望:
-
算法类型
- Policy gradients
- Value-based:拟合/评估Q、V
- Actor-critic
- Model-based RL:重点在提升policy上
-
算法的tradeoffs(权衡)→以至于出现如此多算法

-
Sample efficiency
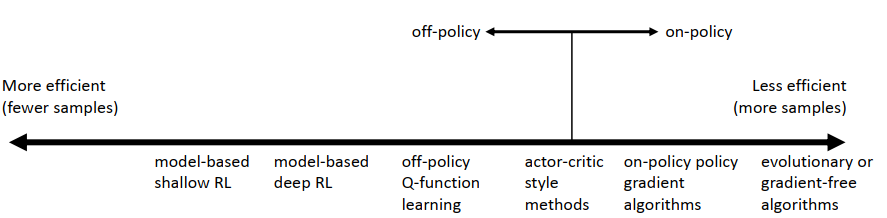
-
Stability and ease of use
- 值函数拟合:定点迭代
- 深度网络不能保证收敛性
- 基于模型的
- 收敛but不能保证model=better policy
- 策略梯度
- 只有一个在真正的目标上执行梯度下降(上升)的
- 值函数拟合:定点迭代
-
各类算法

-
Resource:CS285官网资料
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权:转载或者引用本文内容请注明来源及原作者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号