
ICML 2017-Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Key
Gradient Descent+TRPO+policy Gradient
训练模型的初始参数,模型在新任务上只需参数通过一个或多个用新任务的少量数据计算的梯度步骤更新后,就可以最大的性能。而不是通过大量的新任务重新学习,而是调整学习。
解决的主要问题
- 想要让系统能够快速学习,尽快适应新任务
文章内容
-
Introduction
人工智能需要快速学习,才更像人类的智力。之前元学习方法:学习更新功能或学习规则;本文提出的算法不会扩展学习参数的数量,也不会对模型架构施加约束(通过要求循环模型或Siamese网络)
两种理解方式:- 特征学习角度:通过梯度训练参数,其实是在构建一个广泛适用于许多任务的内部表示。如果内部表示适合许多任务,简单地微调参数(例如,主要修改前馈模型的顶层权重)可以产生良好的结果。
- 动态系统角度:本文的学习过程可以被视为最大化新任务的损失函数相对于参数的灵敏度:当灵敏度很高时,对参数的小的局部变化可以导致任务损失的大幅度改善
-
Model-Agnostic Meta-Learning
-
set-up
aim:model f(观测x到输出a的映射)
每个任务由四部分表示(由损失函数,初始观测分布,过渡分布,和episode长度)
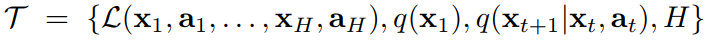
- 训练:从任务分布中采样task,交互k次,计算task下的loss梯度,更新当前task的参数。batch tasks分别计算和更新完后,即完成了第一次梯度更新。
最后根据累计loss的梯度来更新model参数。注意:此处是根据第一次梯度更新得到的参数来计算each task的loss,从而计算第二次梯度更新。
文章中解释为:采样任务上的测试误差充当元学习过程的训练误差。即第二次梯度计算利用的loss为每个task的test error,并利用该损失进一步更新参数θ
理解:即θ'为task更新后的参数,想要测试该θ'的效果,需要测试,即在new task上用θ'的loss来作为测试误差。
注意:训练objective:使得采样tasks的累计loss的梯度minimize - 测试:从任务分布中采样新任务,在K个样本中学习后的model表现来衡量模型的性能
- 训练:从任务分布中采样task,交互k次,计算task下的loss梯度,更新当前task的参数。batch tasks分别计算和更新完后,即完成了第一次梯度更新。
-
MAML Algorithm

-
-
Species of MAML
分别讲述了小样本学习和强化学习。
这里主要讲述RL:
f为状态xt在each t对应的at概率分布,设置each task的loss:
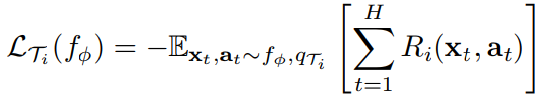
注意:由于政策梯度是一种on-policy算法,在fθ适应过程中,每一个额外的梯度步骤都需要来自当前政策fθi'的新样本。

-
Experimental evaluation
-
problem:
是否能够快速学习适应新任务
是否适用于不同的领域domains
用MAML学习的模型可以通过额外的梯度更新 和/或 示例继续改进吗 -
文章实验分别在回归、分类、RL领域进行了实验。
RL:- 在2D Navigation和Locomotion环境中进行实验,利用vanilla策略梯度(REINFORCE)进行梯度更新的计算;使用信任区域策略优化(TRPO)作为元优化器
- 为了避免TRPO三次导数,使用有限差分计算TRPO的Hessian-vector
- 对于learning和meta-learning更新,使用标准线性特征基线,在批次中每个采样任务的每个迭代中分别拟合。并且与三个基线进行比较(pretraining one policy,andomly initialized weights,oracle policy)
-
-
Discussion and Future Work
使大容量可伸缩模型(如深度神经网络)能够通过小数据集快速训练的关键因素是 重用来自过去任务的知识。
未来:进行使多任务初始化成为深度学习和强化学习的标准成分
文章方法的优缺点
- 优点
- 加速了使用神经网络策略的策略梯度强化学习的微调
- 只需最小的修改,就可以轻松地处理不同的架构和不同的问题设置,包括分类、回归和策略梯度强化学习。
- 没有引入任何学习参数,不会扩展学习参数的数量,也不会对模型架构施加约束
- 缺点
- 在MAML用于RL中,由于PG是on-policy,每次task训练需要根据更新前后的参数分别进行两次样本采样。
- 需要知道任务分布,才能进行采样。
Summary
该文章不再像之前基于RNN的meta-RL思想,按照该文章的理解,那是在给模型架构施加约束条件。然而,此次的方法不需要任何架构和参数的改变,只是调整了参数更新的方式。
通过利用采样到的每个task根据loss更新到的单个task的参数,来再次计算新参数下的task loss。最后根据累计的新参数loss总和进行model参数的更新。
我理解是最后使得model参数让每个任务的loss最小,这样就能快速适应新任务。因为任务分布内的task是相近的,即有共同特点,model参数是融合了tasks相似的特点。利用训练模型的参数,在适应新任务的时候,就可以只需要少量的梯度更新。
论文链接
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权
本文作者:Lee_ing
本文链接:https://www.cnblogs.com/yunshalee/p/16244893.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步