

Java集合
Java的集合其实就是数据结构在Java中的实现,其实之前写了几篇文章介绍数据结构,只写了栈和队列。现在准备介绍一下
1.数组Array
2.栈Stack
3.队列Queue
4.链表Linked List
5.哈希表Hash
6.堆Heap
7.图Graph
8.树Tree
不想再去写数据结构的实现原理了,只写一下集合的使用得了。
Java里面有数组,那为什么还要使用集合呢?原因是数组有以下缺点:
数组的缺点:
1.数组长度不可变,一旦数组初始化,长度就固定了。
2.数组只能存储同类型的数据,除了Object数组,但是Object一般都带来了装箱和拆箱的问题。
在处理一个数据结构的实现,例如栈,堆,链表什么的,你得使用数组去自己实现。这样每次换个项目你就得去重写,很麻烦。这就出现了集合的概念,集合就是 数据结构的具体实现,直接使用就行了。
Java的集合都在Java的工具包里面,这个包叫 Java.util
开始介绍集合了
一、Vector数组 (这个Vector不使用,推荐使用ArrayList,下面介绍ArrayList时有介绍原因。这里还是了解一下)
Vector这个类,直接ctrl+鼠标左键,我们看一下他的源码,大致是这样的:

我们可以看到,他其实就是一个Object的一个数组而已,初始化数组默认是10,你也可以传入参数自己去定义初始的大小。
我们写一个Vector数组的代码:
package com.day16; import java.util.*; public class VectorDemo { public static void main(String[] args) { Vector vector=new Vector(5); vector.add("许嵩"); vector.add(new Date()); vector.add(123); System.out.println(vector.size()); } }
输出结果就是3.可以看到,我们添加了字符串,时间,数字这三种格式,因为Object是所有类型的基类。这里其实涉及到了装箱和拆箱的操作,这个是会损耗性能的。从Java5开始,Java就有了一个语法糖,就是我们上面写的,不用手动的去装箱了,其实语法糖的背后,Java帮我们装箱了而已。
其实,存储的都是对象,例如:
package com.day16; import java.util.*; public class VectorDemo { public static void main(String[] args) { Vector vector=new Vector(5); vector.add("许嵩"); vector.add(new Date()); vector.add(123); StringBuilder sb=new StringBuilder("许嵩"); vector.add(sb); System.out.println(vector); sb.append("最佳歌手"); System.out.println(vector); } }
输出结果就是:
[许嵩, Sun Nov 04 18:21:35 CST 2018, 123, 许嵩]
[许嵩, Sun Nov 04 18:21:35 CST 2018, 123, 许嵩最佳歌手]
Vector类存储的原理:
1.表明是Vector类的对象,实际底层还是Object数组
2.只能存储任意类型的对象
3.存储的对象都是对象的引用,而不是对象本身
Vector类的一些方法:
Vector vector=new Vector(5); Vector vae=new Vector(5); //增加 vector.add("许嵩"); vector.add(0,"许甜甜"); //增加元素,指定位置 vector.addAll(vae); //这个添加一个集合, 实现Collection接口的任意集合都可以 //这里说一下,add()和addAll()方法都可以去添加集合,但是添加的方式是不一样的,可见下图所示 //修改 vector.set(0,"Vae");//第一个指定元素位置,第二个参数为修改后的数据 //删除 vector.remove("许嵩");//移除指定的元素,如果有多个许嵩,只删除第一个找到的 vector.remove(0); //移除指定位置的元素 vector.removeAll(vae); //删除当前集合中的另一个集合的所有元素 vector.retainAll(vae); //删除两个集合中相同的元素,其实就是求交集 //查询 vector.size(); //返回集合的元素个数 vector.isEmpty(); //判断当前集合中元素是否为0 vector.get(0); //查询指定位置的元素 vector.toArray(); //把集合对象转化为Object数组,这个底层是copy了一份新的集合元素,集合本身元素不变
下面这两张图,第一张是add()和addAll()的区别。第二张是retainAll()的原理,其实就是交集。
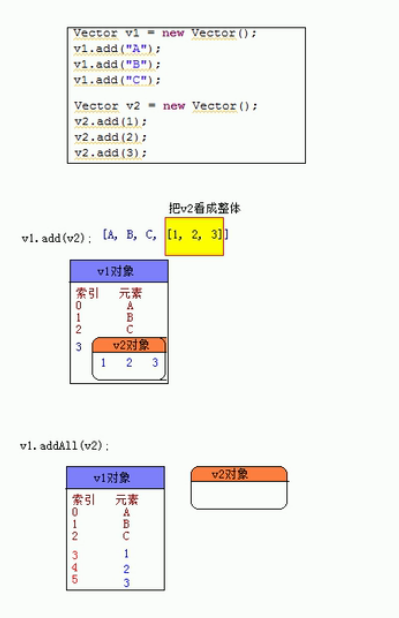

数组类这里,推荐使用ArrayList类,ArrayList类的操作和Vector是差不多的
Vector和ArrayList的关系:
1):底层算法都是基于数组.
2):ArrayList是集合框架里提供的新的变长数组.Vector是ArrayList的前身.
3):Vector相对于ArrayList来说,线程更安全,但是性能较低.
二、Stack 栈
栈的特点是后进先出。这个我在数据结构的文章里面介绍的很详细 数据结构之栈
栈在生活中的体现例子有这些:
1.聊天软件发来的消息,后发的消息在最上面,想想你的QQ,微信,后面发的人的消息在最上面
2.子弹弹夹,先装的子弹都在最下面,最后一个装的在第一个,也是最先打出的子弹
直接写出几个方法吧
package com.StadyJava.day16; import java.util.*; public class StackDemo{ public static void main(String[] args) { Deque stack=new ArrayDeque(); stack.push("许嵩"); stack.push("许甜甜");//push()是进栈 System.out.println(stack); System.out.println(stack.isEmpty());//判断栈是否为空 System.out.println(stack.peek());//取出栈顶的元素,但不删除 System.out.println(stack.pop());//取出栈顶的元素,并且删了它 System.out.println(stack); } }
输出结果:
[许甜甜, 许嵩] false 许甜甜 许甜甜 [许嵩]
之所以使用
Deque stack=new ArrayDeque();
而不使用
Stack stack=new Stack();
的原因是,Java提倡第一种写法,而且栈顶的元素是在第一位的。下面讲队列的时候也会使用这个,就是一接口
三、ArrayList 数组
这个和Vector类的数组是一样的,方法都是差不多,内部也是Object数组。所以方法就不介绍了,一模一样。但是他们的区别很重要,看
这个是Vector的add方法:
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }
这个是ArrayList的add方法:
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
最大最大的区别在于Vector的方法有synchronized关键字,这个是线程安全里面的同步方法!
所以这里我对比一下Vector和ArrayList的区别:
1.Vector所有的方法都使用了synchronized修饰符 多线程安全,但是性能比较低
2.ArrayList所有的方法都没有使用synchronized修饰符 性能快但是多线程不安全
3.及时在多线程的情况下,也不要使用Vector,因为Java推出了一个方法是 List Arraylist=Collections.synchronizedList(new ArrayList()); 你只需要把你的ArrayList数组放到这个方法里面,就不用担心多线程下不安全的事情了,所以,不要使用可怜的Vector
4.如果查询某个元素木有查询到,java7之前,ArrayList会返回一个Null 但是Java7之后,ArrayList会返回一个空的数组,return Collections.emptyList();
5.在创建数组初始化的时候,Vector上来就分配了10个空间,而ArrayList在创建的时候创建了一个空数组,大小是0,只有你在存进去第一个数的时候ArrayList才会扩充大小为10,这样性能高,也不会浪费空间
四、LinkedList
LinkedList类:底层使用的单链表操作/双向链表/单向队列/双向队列.
LinkedList多线程不安全,需要Collections.synchronizedList()方法
LinkedList有get()方法,但是没有索引,只有数组才有索引,链表没有,Java2开始,有一个变量充当索引,所以也可以使用get()方法,但是要少用,LinkedList不擅长做查询操作,最擅长做添加和删除操作。
讲到这里,讲了好几个集合了,区别呢,共同点呢?是时候放出这张图了。我们上面讲的4个集合,都是实现了List接口的,都有元素可以重复,记录添加顺序的特点。
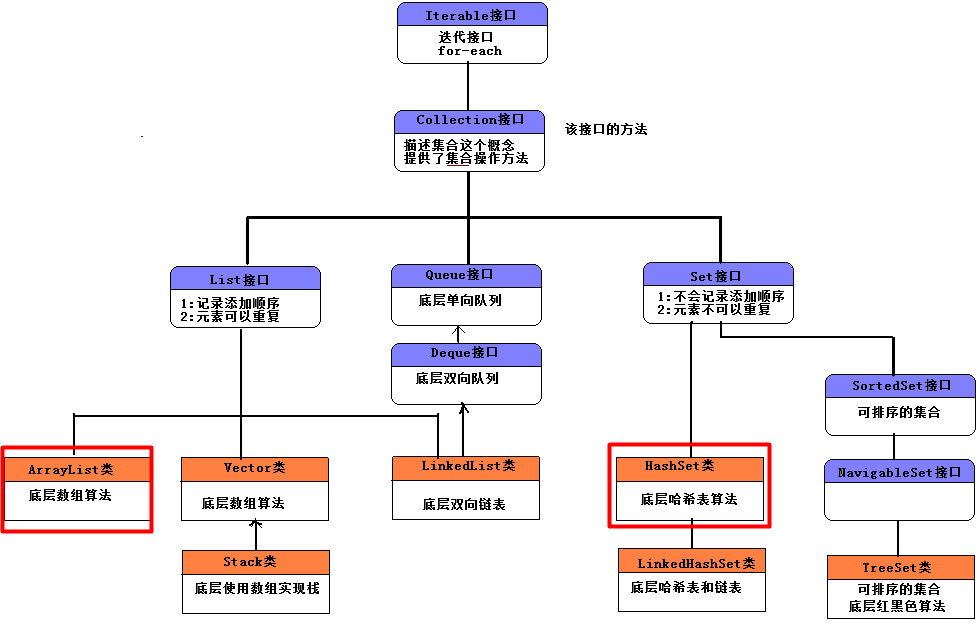
ArrayList和Vector和LinkedList三个什么时候用:
Vector打死不用
添加和删除操作频繁使用LinkedList
查询频繁使用ArrayList
一般来说,还是查询频繁的情况多一些,所以ArrayList还是比较常用的。
集合的迭代
已经讲了4个集合了,现在讲一下集合的迭代,迭代就是遍历集合内的所有的元素,取出来,有以下方法:
package com.StadyJava.day16; import org.hibernate.validator.constraints.NotEmpty; import java.util.*; public class SetDemo { public static void main(String[] args) { List list=new ArrayList(); list.add("A"); list.add("B"); list.add("C"); //迭代方法1,for循环 for (int i = 0; i < list.size(); i++) { Object object=list.get(i); System.out.println(object); } //迭代方法2,foreach循环 for (Object object:list) { System.out.println(object); } //迭代方法3,迭代器 Iterator it=list.iterator(); while (it.hasNext()){ System.out.println(it.next()); } } }
这里要讲一下foreach循环
foreach循环在操作数组的时候,其底层就是for循环,有一个索引去获取数组的元素。
foreach循环在操作集合的时候,其底层其实是iterator迭代器,在foreach循环的时候,如果调用了集合的remove删除方法,会引发并发修改异常的报错
原因如图所示:
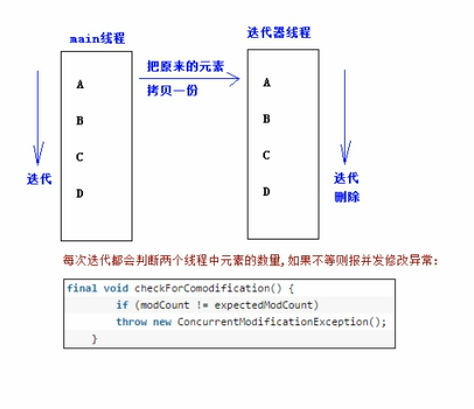
你如果调用集合的remove()方法去删除左边的元素,但是右边的迭代器线程的元素木有删除啊,所以就引发了并发修改异常的错误。那么意思就是说,使用foreach迭代集合的时候,不能删除了???
答案是可以删除,但是需要使用迭代器自己的remove()方法,如下:
package com.StadyJava.day16; import java.util.*; public class VectorDemo{ public static void main(String[] args) { List list=new ArrayList(); list.add("A"); list.add("B"); list.add("C"); Iterator it=list.iterator(); while(it.hasNext()){ if ("B".equals(it.next())) { it.remove(); } } System.out.println(list); } }
讲完了集合的迭代,再讲一下什么是泛型。
泛型

为什么要使用泛型?
1.Object类型需要装箱和拆箱,需要我们手动的去强转
2.有的时候需要集合中的元素类型都得一样,Object集合不能满足
3.如果需要多类型的集合,就得多写几种集合,违背单一原则
怎么写泛型?
package com.StadyJava.day16; //泛型的使用就是在类后面加一个<T> 然后里面的元素使用T来修饰就完事了 class Point<T>{ private T x; private T y; public T getX() { return x; } public void setX(T x) { this.x = x; } public T getY() { return y; } public void setY(T y) { this.y = y; } } public class SetDemo { public static void main(String[] args) { // Point point=new Point(); //如果泛型类不指定类型的话,默认是Object类型,这样又会涉及装箱拆箱,还要我们自己去强转,所以还是指定类型吧 Point<String> point=new Point<String>(); point.setX("许嵩"); } }
通过反编译,我们可以发现,泛型其实也是一种语法糖,让我们开发人员写的简单一点,其实底层还是Object类型在强转。所以泛型也涉及到装箱拆箱,也会消耗性能,但是不用我们手动去强转了
泛型方法,由于泛型类只适用于非静态方法,静态方法就得自己写
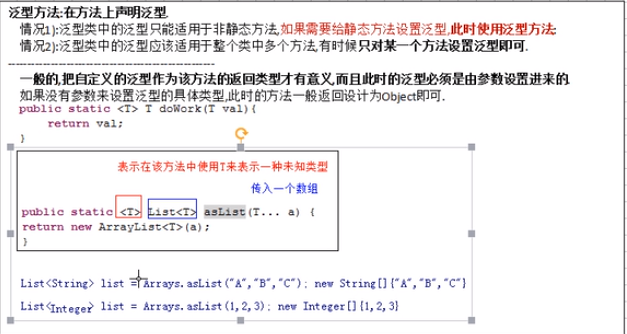
泛型类在被使用的时候,要明确类型的,例如子类继承泛型类,就要声明泛型类的类型。
泛型的通配符和上限、下限
package com.StadyJava.day16; import java.util.ArrayList; import java.util.List; public class SetDemo { public static void main(String[] args) { List<Integer> list1=new ArrayList<>(); List<String> list2=new ArrayList<>(); dowork1(list1); dowork1(list2); } //这个就是通配符,只能作为参数 private static void dowork1(List<?> list){} //这个就是通配符的下限,必须是Number或者Number的子类类型的 private static void dowork2(List<? extends Number> list){} //这个就是通配符的上限,必须是Number或者Number的父类类型的 private static void dowork3(List<? super Number> list){} }
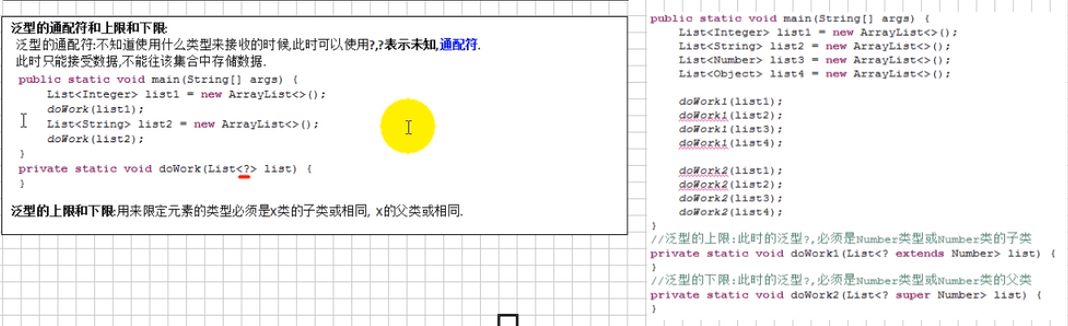
泛型的擦除和转换
泛型的擦除有两种:
1.代码编译之后泛型就消失了,擦除了。这个可以去反编译一下Java代码(泛型的自动擦除)
2.当带有泛型的集合赋给不带泛型的集合之后,泛型就会被擦除(泛型的手动擦除)
第一种没什么好讲的,来讲讲第二种,看代码:
package com.StadyJava.day16; import java.util.*; public class VectorDemo{ public static void main(String[] args) { //泛型的擦除 List<Integer> list1=new ArrayList<>(); list1.add(123); //我定义了一个Integer类型的数组,现在赋给String类型的数组试试 List<String> list2=null; //list2=list1; 报错,不同类型的肯定不能赋予 //试试泛型的擦除 List list3=null; list3=list1; //这个时候list3就已经没有类型了,就可以泛型擦除了 list2=list3;//这个时候,我们把擦除泛型的list3赋给list2,居然成功了!我们绕过了Java的检查 String num1=list2.get(0); //报错,本质和下面的一样 String num2=123; //报错 } }
虽然我们使用了泛型的擦除让Integer类型的数组赋给了String类型的数组,但是这样是不安全的,所以不要这样做。
堆污染:当一个方法即使用泛型的时候也使用可变参数,此时容易导致堆污染问题。
这个了解一下就可以了,Arrays类里面有一个方法就是堆污染的,就是下面的这个方法,@SafeVarargs就是一个注解,作用是掩盖住堆污染的错误,就是 一种掩耳盗铃的作用。
@SafeVarargs public static <T> List<T> asList(T... a) { return new ArrayList<>(a); }
List接口已经写完了,改Set接口了,上面神图里面说了,Set接口的特点就是元素不允许重复,元素插入没有顺序。
一、HashSet
来看一个元素没有顺序的例子
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { Set<String> set=new HashSet<>() ; set.add("X"); set.add("1"); set.add("V"); set.add("e"); set.add("V"); //Set不允许重复,所以这个V没保存 System.out.println(set); } }
输出的结果却是:


上图就是说,最好哈希表中的HashCode和Equals都相同,如果我们自己写了一个类,希望这个类的对象存储到HashSet里面,那么我们需要重写HashCode和Equals方法
package com.StadyJava.day16; import java.util.*; class Student{ private String name; private Integer xuehao; private Integer age; public Student(String name, Integer xuehao, Integer age) { this.name = name; this.xuehao = xuehao; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return Objects.equals(name, student.name) && Objects.equals(xuehao, student.xuehao); } @Override public int hashCode() { return Objects.hash(name, xuehao); } } public class SetDemo { public static void main(String[] args) { Set<Student> set=new HashSet<>() ; set.add(new Student("许嵩",1,32)); set.add(new Student("许嵩",1,33)); set.add(new Student("蜀云泉",3,23)); System.out.println(set.size()); System.out.println(set); } }
我规定的name和xuehao一样的时候才算重复,所以上面代码的输出结果是2.
这里说一下,Idea里面创建构造器和HashSet、Equals的方法,单机鼠标右键,选择

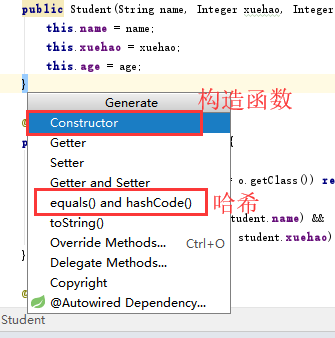
选中自己需要的字段就可以了,代码不需要自己写
二、LinkedHashSet
我们都知道了Set接口经典的实现类HashSet,Set接口都是不允许元素重复,不记录元素添加顺序的。但是,我现在想要一个元素不允许重复,但是可以记录元素添加顺序的集合。当然有了
LinkedHashSet类是HashSet类的一个子类,里面有哈希算法,也有链表。
LinkedHashSet特点:
1.元素不允许重复
2.元素添加有顺序
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { Set<String> set=new LinkedHashSet<>() ; set.add("V"); set.add("a"); set.add("e"); System.out.println(set); } }

由于比HashSet多了一个链表来记录顺序,所以效率是低点的,了解一下
三、TreeSet
TreeSet集合底层使用的是红黑树算法,会对元素进行一个默认的自然排序。这就要求,TreeSet集合中的元素必须类型相同,否则你怎么排序?
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { TreeSet set=new TreeSet() ; set.add("c"); set.add("a"); set.add("e"); System.out.println(set); } }
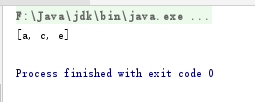
果然是默认排序的
总结一下Set集合的这三个实现类


最后来讲一下Map,Map其实并不算是集合,他只是两个集合之间的一种映射关系。Map本身就是最高接口,并没有继承于Collection接口,只有继承Collection接口的才算是集合
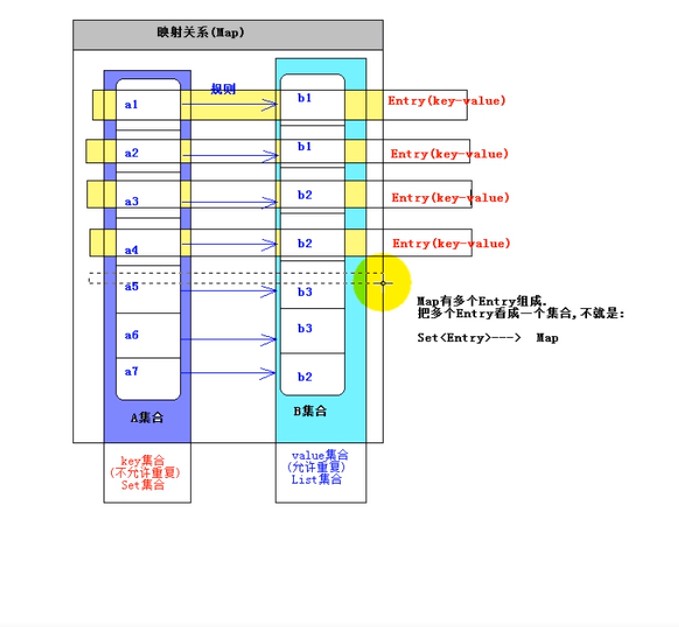
Map就是两个集合之间的映射关系,由key-value组成,也称之为键值对Entry ,所以Map也可以理解为由一个个Entry组成的,是不是有点 Set<Entry>的意思,由于Map没有继承Collection接口和Iterable接口,所以Map是不能使用foreach迭代的,但是别急,还有其他方法可以实现Map的迭代,有3种方法,看一下Map的主要方法:
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { Map<String,Object> map=new HashMap<>(); map.put("key1","许嵩"); map.put("key2","林俊杰"); map.put("key3","蜀云泉"); map.put("key4",1); //我的第二个集合是Object类型的,所以我可以存汉字和数字 System.out.println(map); //Map的key是不允许重复的,value可以重复 System.out.println(map.containsKey("key1")); //看看当前Map中有没有这个key System.out.println(map.containsValue("许嵩")); //看看当前Map中有没有这个value System.out.println(map.get("key3")); //根据key获取value System.out.println(map.size()); //键值对的个数 System.out.println(map.remove("key4")); //删除这个键值对 //Map不能使用foreach循环,但是可以通过其他方法,有3个方法迭代Map // 方法1:Map的key,因为key不能重复,所以相当于Set: Set<String> keys=map.keySet(); //获取所有的key //获取了所有的key,又通过key了value for (String key:keys) { System.out.println(key+"->"+map.get(key)); } //方法2:Map的Value Collection<Object> values=map.values(); System.out.println(values); //方法3:键值对方式 EntrySet Set<Map.Entry<String,Object>> entrys=map.entrySet(); for (Map.Entry<String,Object> entry:entrys) { System.out.println(entry.getKey()+"->"+entry.getValue()); } } }
总结,Set和Map的关系

Map的图
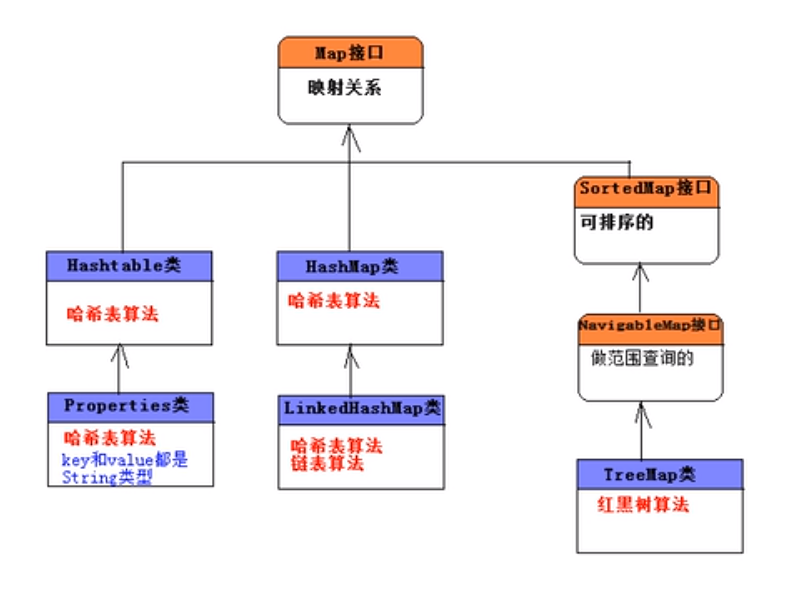

HashMap没有排序,无序的
LinkedHashMap会根据你添加元素的顺序存储
TreeMap会有一个排序
下面我们来通过一个例子,来讲解一下Map的使用
随意输入一个字符串,输出该字符串中每个字符所有的个数
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { String msg="asdhgsdhgasdkjhsa"; //Map<Character,Integer> map=new HashMap<>(); 没有顺序 //Map<Character,Integer> map=new LinkedHashMap<>(); 按照字符顺序 Map<Character,Integer> map=new TreeMap<>(); //按照自然排序 //先获取字符串的所有字符,转为char数组,字符串的底层就是char数组 char[] chars=msg.toCharArray(); for (char ch:chars) { if (map.containsKey(ch)) { //如果有这个字符了,就把value取出来,加1,再填进去 Integer oldnum=map.get(ch); map.put(ch,oldnum+1); } else{ map.put(ch,1); } } System.out.println(map); } }
List和Set和Map的选用

List和Array数组和Map之间的转换

Arrays转List得到的是一个固定长度的List,不能删除,可以更改
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { List<String> list=Arrays.asList("A","B","C"); //list.remove(0); 报错 UnsupportedOperationException 因为Arrays.asList方法是把数组转化为一个固定长度的List list.set(0,"许嵩"); System.out.println(list); } }
看看这个
package com.StadyJava.day16; import java.util.*; public class SetDemo { public static void main(String[] args) { List<Integer> list=Arrays.asList(1,2,3); int [] arr={1,2,3}; List<int[]> list2=Arrays.asList(arr); System.out.println(list); System.out.println(list2); } }
输出结果是
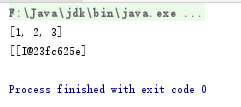
这个是因为asList方法后面是泛型,跟着的就是一个对象,例如Integer的就是1,2,3,这三个数字都是对象。但是下面那个int[]数组,数组也是一个对象。所以就出现了这种情况。


