

python教程1:Python基础之数据类型和变量、字符串和编码
视频链接:http://www.bilibili.com/video/av10730372/
我是在Linux下玩python的,Linux下默认安装python,直接打个pyhon3就好了,python大小写敏感
我们来写第一个简单的python程序
#!/usr/bin/env python3 print("Hello World")
怎么运行呢?有人说是./运行,然而我试了试并不可以....这样才行.....
python name.py
print里面也可以输出多个字符串,用 , 进行分隔,显示的内容是空格
#!/usr/bin/python print('1', '2', '3')
结果是
1 2 3
也能来计算数字
#!/usr/bin/python print('100 + 200 =', 100 + 200)
在Python里面单引号和双引号是一样的,所以单引号里面的还是字符串,结果是
100 + 200 = 300
输入和输出
name=input('please enter you name:') print('hello',name) #变量可以print出来也可以直接打个变量名
缩进
a = 100 if a >= 0: #以:结尾说明下面的缩进的语句是代码块 print(a) #注意!缩进最好是4个空格 else: print(-a)
数据类型
1.整型 int
2.浮点型 float
3.字符串 以单引号或双引号括起来的任意文本,\可以转义字符
4.布尔值 要么是True要么是False 注意大小写!!! 与或非
5.空值 用None表示
转义字符\
print('\\\t\\') \ \ print(r'\\\t\\') #前面加一个r就是不转义 \\\t\\
变量
变量名必须是大小写英文、数字和_的组合,且不能用数字开头
a=1 #变量a是一个整数 t_001='T007' #变量t_007是一个字符串 Answer=True #变量Answer是一个布尔值
在python中,变量分为动态语言和静态语言
#动态语言,就是变量本身类型不确定 a = 123 # a是整数 print(a) a = 'ABC' # a变为字符串 print(a)
#静态语言,变量类型已被指定 int a = 123; // a是整数类型变量 a = "ABC"; // 错误:不能把字符串赋给整型变量
我们来做个练习
a = 'ABC' #创建了字符串'ABC'和变量a,并把a指向'ABC' b = a #创建变量b,并把b指向'ABC' a = 'XYZ' print(b)
问:b的值是什么?
答案是'ABC'
除法
python中有两种除法
/除法计算结果是浮点数
>>> 9 / 3 3.0
//地板除,计算结果是整数
>>> 10 // 3 3
%求余运算
>>> 10 % 3 1
字符串和编码
ASCII码仅仅支持英文
GB2312支持中文
....支持.....
全球上百种语言这么乱怎么办?Unicode编码标准应运而生,支持所有语言,但是也有缺点用,Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以就有了UTF-8编码
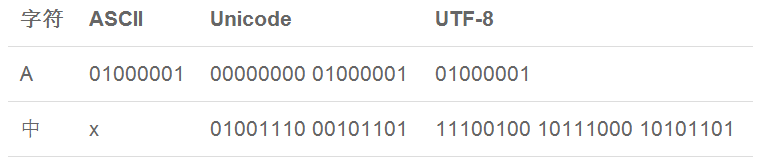
Python的字符串
在Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言
>>> print('包含中文的str') 包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符
>>> ord('A') 65 >>> ord('中') 20013 >>> chr(66) 'B' >>> chr(25991) '文'
Python对bytes类型的数据用带b前缀的单引号或双引号表示要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节
x = b'ABC'
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
#纯英文字符串可以使用ASCII编码为bytes >>> 'ABC'.encode('ascii') b'ABC' #中文字符串可以使用utf-8编码为bytes >>> '中文'.encode('utf-8') b'\xe4\xb8\xad\xe6\x96\x87' #中文字符串使用ASCII编码就会报错,因为不支持 >>> '中文'.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii') 'ABC' >>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') '中文'
len() 函数
#计算字符串包含多少个字符 >>> len('ABC') 3 >>> len('中文') 2 #计算bytes的字节数 >>> len(b'ABC') 3 >>> len(b'\xe4\xb8\xad\xe6\x96\x87') 6 >>> len('中文'.encode('utf-8')) 6
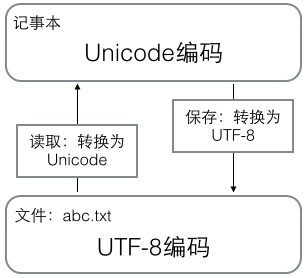
由于python源代码也是一个文本文件,所以当包含中文的时候,在进行编码时务必使用utf-8编码,为了如此,我们通常在文件开头写上两行
#!/usr/bin/env python3 # -*- coding: utf-8 -*-
这里还需要注意的是在你写python的文本编辑器里面最好把编码改成utf-8才可以
格式化
>>> 'Hello, %s' % 'world' 'Hello, world' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.'
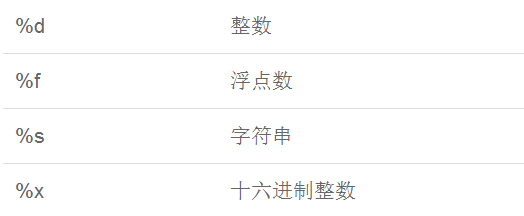
>>> '%2d-%02d' % (3, 1) ' 3-01' >>> '%.2f' % 3.1415926 '3.14'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%
>>> 'growth rate: %d %%' % 7 'growth rate: 7 %'

