
Python爬虫笔记技术篇
前言
本篇为技术篇,,会讲解各种爬虫库的使用,至于库的安装在安装篇已经介绍了
requests出现中文乱码
这种情况是网页没有设置编码,获取不到,所以使用了默认的编码,这个时候中文就会出现乱码的情况
只需要多加一行代码即可
response.encoding='gb2312'
使用代理
免费的代理我试着不行,暂时不研究了,写一下付费的代理是怎么使用的
我购买的是讯代理,购买之后先在白名单里面添加自己的IP,然后点击生成API

选择订单,选择一个城市,然后生成json
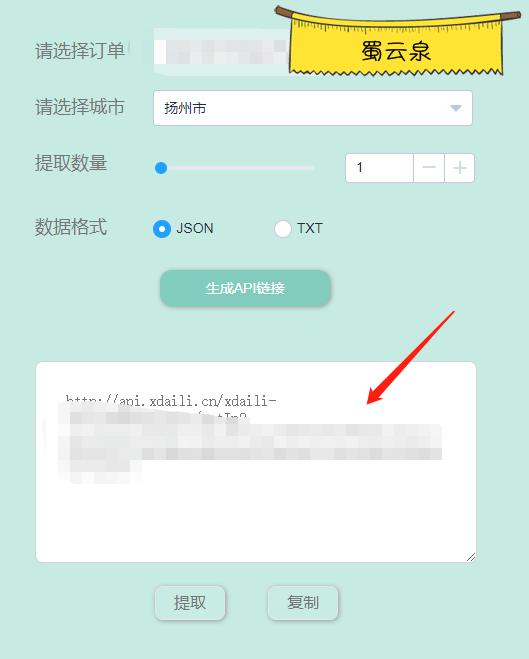
接下来使用Python获取代理IP,我是获取了之后存到数据库了
import pyodbc
import json
import requests
import sys
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac 0S X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
conn = pyodbc.connect('DRIVER={SQL Server};SERVER=192.168.3.8,1433;DATABASE=VaeDB;UID=sa;PWD=test123')
cursor = conn.cursor()
r = requests.get('http://apXXXXXXXXXXXXXXXXXXXXX40300', headers=headers)
print(r.text)
jsonobj = json.loads(str(r.text))
datetime=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
cursor.execute(
'update ProxyIP set IP=?,UpdateDate=? where Id=1', (jsonobj['RESULT'][0]['ip']+':'+jsonobj['RESULT'][0]['port'],datetime))
conn.commit()
sys.exit()
怎么使用代理,这个分为好几个情况,我使用的是Selenium,就写这个,requests的用到再补充
conn = pyodbc.connect(
'DRIVER={SQL Server};SERVER=111.108.8.2,1433;DATABASE=VaeDB;UID=sa;PWD=testxxxx')
cursor = conn.cursor()
cursor.execute("""
select IP from dbo.ProxyIP
"""
)
data = cursor.fetchone()
proxyip=str(data[0])
chrome_options=webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://'+ proxyip)
browser = webdriver.Chrome(chrome_options=chrome_options)
BeautifulSoup的使用
我使用BeautifulSoup爬取了好几万的数据了,对于普通的网站,BeautifulSoup真的很好用
#BeautifulSoup初始化可以自动更正HTML格式,补全没有闭合的元素
print (soup.prettify())#以标准的缩进格式输出
print(soup.title)#标题
print(soup.title.string)#标题里面的内容
print(soup.title.name)#title的节点名称,就是title
print(soup.p)#第一个p元素的内容
print(soup.p.attrs)#第一个p元素的所有属性和值
print(soup.p['class'])#第一个p元素class属性的值
print(soup.p['name'])#第一个p元素name属性的值
print(soup.p.b.string)#第一个p标签下的b标签的文本内容
print(soup.p.contents)#第一个p元素下的所有子节点,不包括孙子节点
#第一个p元素所有的子节点
print(soup.p.descendants)
for i,child in enumerate(soup.p.descendants):
print(i,child)
print(soup.p.parent)#第一个p元素的父节点
#第一个p元素所有的父节点
print(soup.p.parents)
print(list(enumerate(soup.p.parents)))
print(soup.p.next_sibling)#第一个p元素的下一个兄弟节点,注意有回车的时候要写两个next_sibling
print(list(enumerate(soup.p.next_siblings)))#第一个p元素后面的所有兄弟节点
print(soup.p.previous_sibling)#第一个p元素的上一个兄弟节点
print(list(enumerate(soup.p.previous_siblings)))#第一个p元素前面的所有兄弟节点
#########################################################
#下面这些是比较常用的,上面的了解一下即可
# 判断某个标签是否有属性,例如img标签有一个alt属性,有时候img没有alt属性,我就可以判断一下,否则出错
if img.attrs.get('alt'):
soup.find(id='text-7').find_all(name='li')
#根据文本查找到该标签
# 例如下面的,根据Description查找含有Description的第一个p元素
test = soup.find(lambda e: e.name == 'p' and 'Description' in e.text)
# 其实如果是直接子元素的话,也可以使用parent,但是这个很少用,适用情况不多
test= soup.find(text=re.compile('Description')).parent
#查找某个属性为包含的标签
#标签的属性有很多值,例如img标签的alt属性,有item和img两个值,可以通过如下查找
noscript.find_all('img',attrs={'alt':re.compile('item')})
#判断属性里面是否有某个值
if 'Datasheet' in img['alt']:
#替换所有的br换行符号
html = get_one_page(url)
return html.replace('<br>', '').replace('<br />', '').replace('<br/>', '')
#去除最后一个逗号
datasheet_url.rstrip(',')
#去除关键字和空格,只要后面的内容
#例如 Function : Sensitive Gate Silicon Controlled Rectifiers
#得到的就是Sensitive Gate Silicon Controlled Rectifiers
return re.sub(keywords+'.*?[\s]:.*?[\s]', '', child.find(text=re.compile(keywords)).string)
#返回某个符号之前的字符
import re
text="K6X4008C1F-BF55 ( 32-SOP, 55ns, LL )"
b=re.search('^[^\(]*(?=\()',text,re.M)
if b:
print(b.group(0))
print(len(b.group(0)))
else:
print('没有')
#关键地方是,这里是匹配的( 括号需要\来转义一下
^[^\(]*(?=\()
#如果是逗号,可以写
^[^,]*(?=,)
#如果是单词,比如我想匹配Vae这个单词,如下
text='XuSong Vae hahaha'
text2='VV Vae hahaha'
b=re.search('^[^Vae]*(?=Vae)',text,re.M)
#这个例子很重要,text是可以正则出XuSong的,但是下面的VV就正则不出来了,因为^是后面的Vae的任意一个单词,只要前面包含就不行,VV包含了V,所以就不行了,我尝试着给Vae加括号,也不行.然后我就想了一个办法,把Vae替换成逗号之类的符号不就可以了,只要是一个字符就行,如下
text='XuSong Vae hahaha'
text2='VV Vae hahaha'
b=re.search('^[^,]*(?=,)',text.replace('Vae',','),re.M)
#一段HTML元素中去除a标签,但是保留a标签的值
return re.sub('(<\/?a.*?>)', '', description_element)
#有时候想获取一段HTML元素内容,因为有的排版在,比如ul和li元素,排版是在的,如果使用text就是一串文本,换行都没了,可以这样
str(child.find(class_='ul2')) #获取到这段HTML元素之后,使用str函数变成字符串即可
#下一个兄弟元素最好使用find_next_sibling()
#等待验证,和next_sibling比较一下再说
验证完毕,我来讲一下find_next_sibling()和next_sibling的区别
如果想要后面的元素的话,写find_next_sibling()
如果想要后面的内容的话,写next_sibling
例如
<a>111</a><p>222</p> 想要获取p元素应该使用find_next_sibling()
<a>111</a>我是文本 想要获取 我是文本 应该使用next_sibling
#Python爬虫数据插入到MongoDB
import pymongo
client = pymongo.MongoClient("mongodb://admin:test123@192.168.3.80:27017/")
db = client.datasheetcafe
collection = db.datasheetcafe
collection.insert_one(message)
Selenium的使用
在爬取一个新网站的时候,我发现网站上的网页数据全都是动态加载的,浏览器加载之后数据才会显示,这个时候BeautifulSoup就没用了,完全获取不到HTML节点
这种情况,可以使用Selenium进行动态加载,我使用这个已经爬取了近200万的数据
基础使用
#有不显示浏览器的,但是我选择了Chrome浏览器
browser = webdriver.Chrome()
#先获取url,再选择元素
browser.get(url)
div = browser.find_element_by_css_selector('.information')
#find_element_by_css_selector这个东西是css选择器,如果选择一个就使用这个,想要选择一堆就加个s,使用find_elements_by_css_selector
#后面的类就是. id就是# 标签名就直接写,如下
table = browser.find_element_by_css_selector('#part-specs')
table.find_elements_by_css_selector('tr')
# 获取属性的值
tr.get_attribute('class')
#对了,下面这个获取的可不是HTML元素,是一个WebElement元素
table = browser.find_element_by_css_selector('#part-specs')
#所以如果你想要HTML元素这样写
table = browser.find_element_by_css_selector('#part-specs').get_attribute('outerHTML')
#获取里面的文本值就这样写
browser.find_element_by_css_selector('.part-number').text
#有一个a标签,我使用a.get_attribute('href')获取href属性值是完全没问题的,但是我获取文本值a.text就获取不到,原因应该是元素隐藏了,可以换一种方式
a.get_attribute('innerText') #获取本文值
#至于怎么判断元素是否存在的,我写了if但是没有,所以我利用try catch帮助解决
try:
button=browser.find_element_by_css_selector('#show-secondary-part-list')
button.click()
except Exception as e:
print('没有这个元素')
#Selenium进行iframe切换
#网页中有iframe的时候,是拿不到里面的HTML数据的,只能通过切换iframe
# 里面的可以是iframe的name或者id
browser.switch_to_frame('popup_frame')
# 再切换回主界面可以使用
browser.switch_to.default_content()
#selenium选择下拉框
这个首先要引入一个Select的包
from selenium.webdriver.support.select import Select
然后执行的时候如此
Select(browser.find_element_by_css_selector ('.form-control')).select_by_value('all')
我是根据Value进行选择的,也可以通过下标或者内容值
#通过name查找
<input name="username" type="text" />
username = driver.find_element_by_name('username')
# 通过超链接文本查找
<a href="continue.html">Continue</a>
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
# 兄弟节点,如果是上一个元素或者父元素,对于selenium来说,使用XPath可能会方便很多
<div id="D"></div>
<div>brother 2</div>
driver.find_element_by_css_selector('div#D + div').text
# 找到直接子元素或者所有子孙元素
使用css的方法是,直接子元素:
browser.find_elements_by_css_selector('#ptp-overview > div')
所有子元素
browser.find_elements_by_css_selector('#ptp-overview div')
使用xpath的方法是,直接子元素
content.find_elements_by_xpath('div')
所有子元素
content.find_elements_by_xpath('//div')
Selenium执行js
有时候还是需要执行js的,特别是有的网页仅仅执行一个js方法就可以获取数据,太爽了
browser.execute_script('window.stop()') #同步方法
browser.execute_async_script('window.stop()') #异步方法
Selenium获取网页动态数据赋值给BeautifulSoup
单纯的使用selenium进行爬虫是真的不好用,虽然selenium有一些css选择器,也可以使用XPath,但是还是不好用,还是BeautifulSoup使用起来顺手,所以遇到那种必须浏览器加载才能出来数据的网站,可以使用Selenium获取到整个网页的源代码数据,然后赋值给BeautifulSoup即可
soup = BeautifulSoup(browser.page_source, 'lxml')
就这么简单,直接selenium的browser.page_source,给soup就ok了
Selenium加载时间过长
有时候Selenium加载一个网页时间过长了,所以必须设定一个超时时间
browser = webdriver.Chrome()
browser.set_page_load_timeout(20)
browser.set_script_timeout(20)
try:
browser.get(address)
except TimeoutException:
browser.execute_script('window.stop()')
div = browser.find_element_by_css_selector('.information')
....
先设定加载时间为20秒,如果20都没加载出来,就算了,直接停止加载,爬取网页内容吧,如果一个HTML元素都没抓取到,空白页面,那就try catch跳过这个网页
Selenium使用Chrome,隐藏Chrome
默认使用Chrome是加载出来的,也可以隐藏Chrome浏览器,那个无界面PhantomJS已经被淘汰了
chrome_options=webdriver.ChromeOptions()
# chrome_options.add_argument('--headless') 如果想不弹出chrome浏览器就开启这两行,那个PantomJS啥的已经过期了
# chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--proxy-server=http://'+ proxyip)
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) #这一行是为了防止网站识别出我是selenium,参考:https://zhuanlan.zhihu.com/p/65077940
browser = webdriver.Chrome(chrome_options=chrome_options)
多进程下无法退出exe
我的爬虫爬了一段时间就停止了,selenium控制的浏览器要么变成了空白页,要么访问失败,最可怕的是页面卡着不动了,这个时候只能重启爬虫程序了,所以我把爬虫发布成exe了,我使用Windows自带的计划任务,隔一段时间就启动exe爬虫,然后问题来了
我必须关闭exe的弹窗,不然加载越来越多的exe,内存会崩的,于是我采用了Python多进程
一个进程去爬虫,一个进程去计时,如果计时10分钟,就退出exe
但是没有执行,无论我使用sys.exit()还是os._exit()都无法退出exe,至今不知道为什么
没办法只好采取了另外一种方法,杀进程
import os
os.system('taskkill /im conhost.exe /F')
# 这两个不能同时执行,我写了两个py,发布两个exe执行
os.system('taskkill /im chromedriver.exe /F')
os.system('taskkill /im chrome.exe /F')
我把控制台和Chrome全杀了.......这样Windows计划任务会重启exe,然后过10分钟我再全杀了.....
对了,Win10的计划任务也搞了我好久,就是不成功,详情见Windows计划任务
scrapy
暂留......
scrapy startproject tutorial
scrapy genspider quotes quotes.toscrape.com
scrapy crawl quotes
爬虫小Demo
爬虫小Demo应该不会再更新了,我爬取的东西不可能写出来了,仅仅介绍技术,授人以渔吧
爬取知乎发现页面的今日最热
import requests
import re
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac 0S X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
r =requests.get("https://www.zhihu.com/explore", headers=headers)
pattern = re.compile('explore-feed.*?question_link.*?>(.*?)</a>', re.S)
titles = re.findall(pattern,r.text)
print(titles)
讲解:headers里面有浏览器标识,不加这个知乎会禁止抓取
爬取某张图片
import requests
import re
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac 0S X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
r =requests.get("https://avatars0.githubusercontent.com/u/13572737?s=460&v=4", headers=headers)
with open('Vae.jpg','wb') as f:
f.write(r.content)
这个不仅可以爬取图片,爬取视频,音频,也是这样的
注意:爬取图片的时候,不写headers会报错,找不到源
下面是把图片保存到制定位置的代码,多了一个判断文件夹是否存在,不存在就创建文件夹的操作,我是根据图片的链接截取作为文件夹的名称的,使用创建文件夹的os需要导入os
import os
def get_allpath(imgurl):
info=imgurl[imgurl.index('uploads'):]
infos=info.split('/')
return infos[0]+"\\"+infos[1]+infos[2]+"\\"+infos[3]
def get_path(imgurl):
info=imgurl[imgurl.index('uploads'):]
infos=info.split('/')
return infos[0]+"\\"+infos[1]+infos[2]
def create_makedirs(dirpath):
if not os.path.exists(dirpath):
os.makedirs(dirpath)
def get_image(child, path):
for img in child.find_all(name='img'):
imgurl = img.attrs.get('data-lazy-src')
if imgurl:
if 'gif' in imgurl:
create_makedirs(path+get_path(imgurl))
r = requests.get(imgurl,headers=headers)
with open(path+get_allpath(imgurl), 'wb') as f:
f.write(r.content)
#最后我在调用的时候,直接输入放到哪里的路径即可
path = 'D:\\datasheetcafe\\'
get_image(child, path)
爬取视频
其实和爬取图片是一样的,只不过换了url而已,这里以爬取我的哔哩哔哩视频为例
如图是我的哔哩哔哩发的一个视频,点击F12,然后在NetWork里面找到视频的那个请求,一般是最大Size的那个
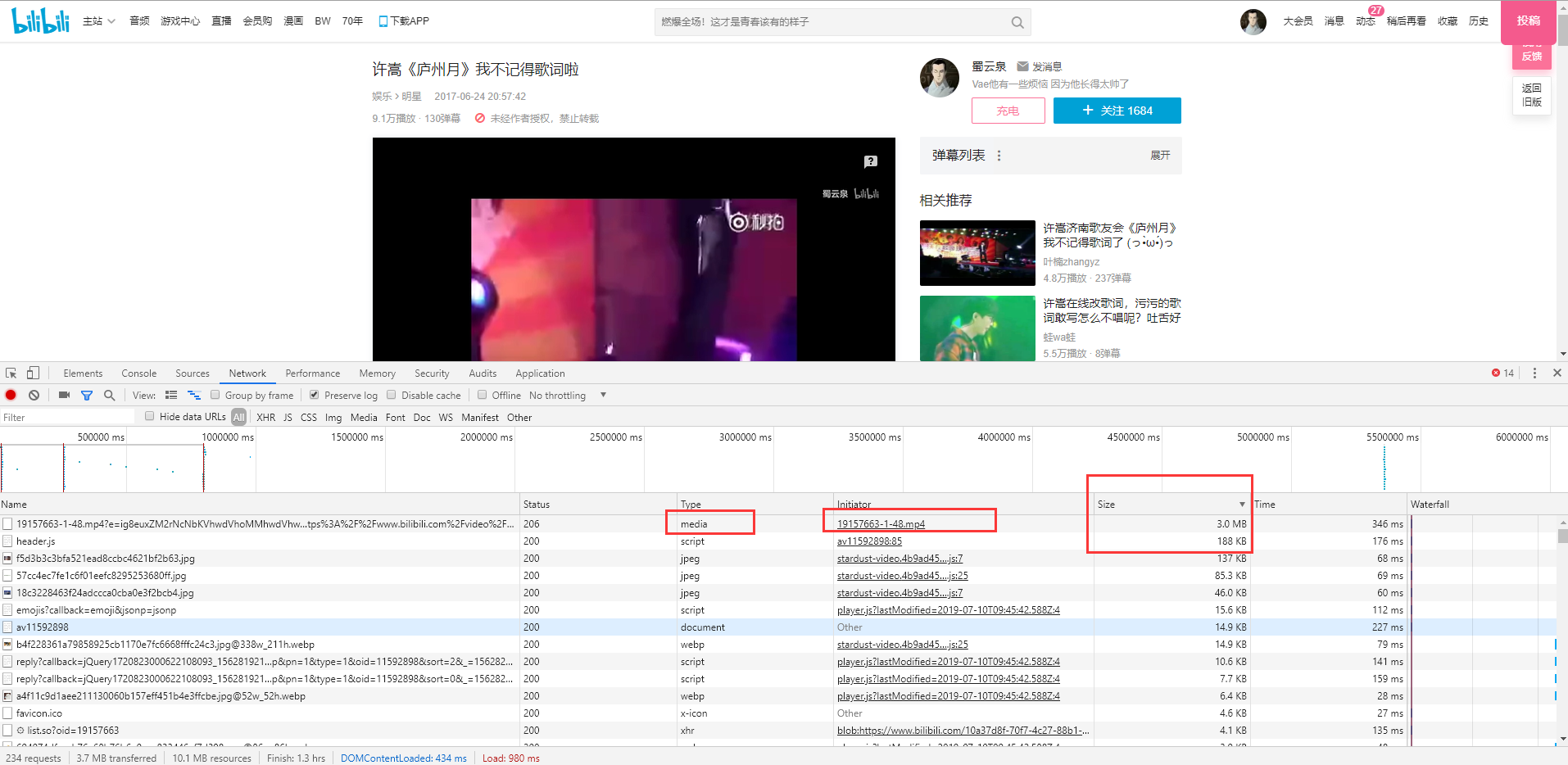
点进去,看到的那一串就是视频地址
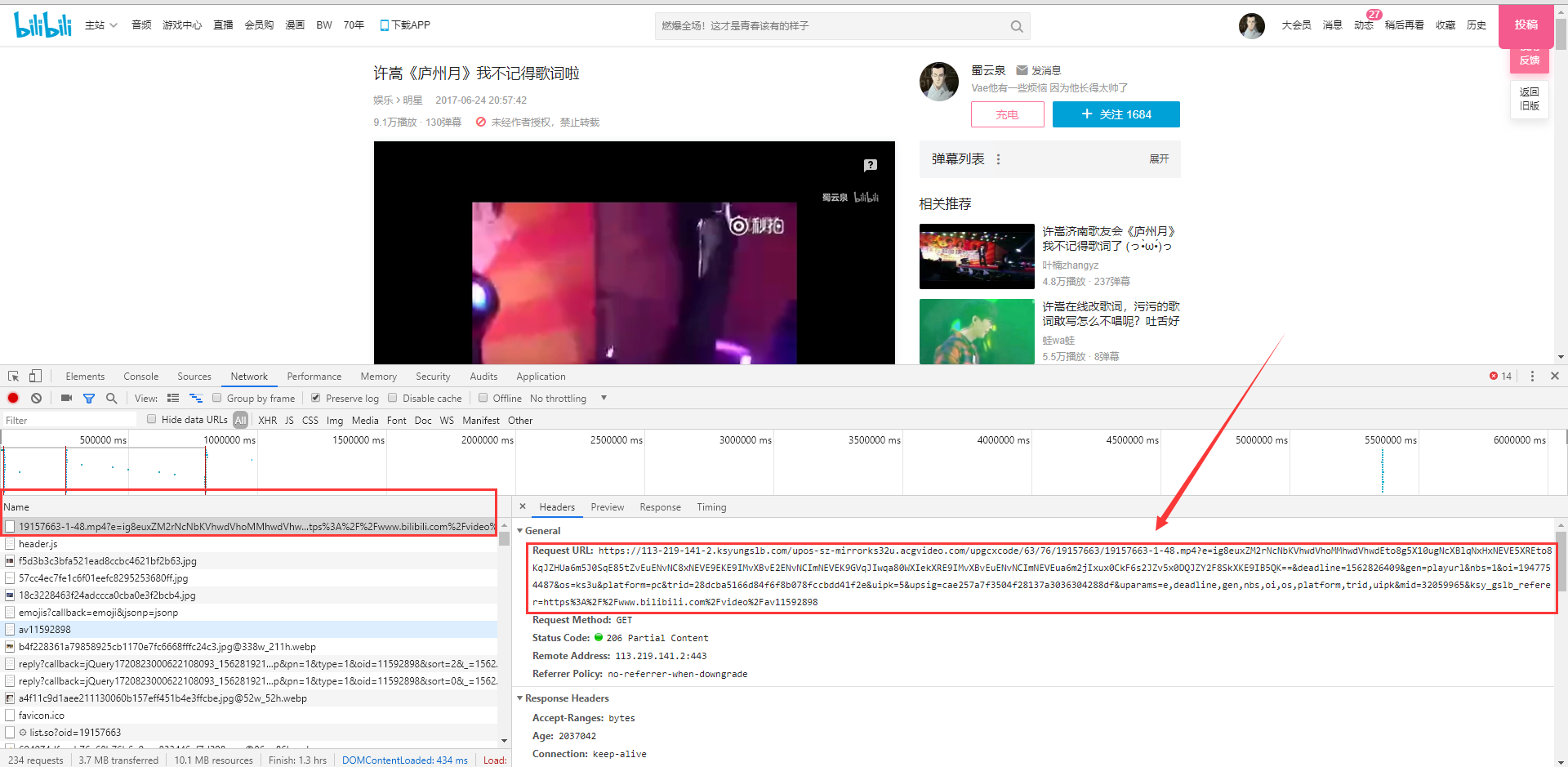
复制视频地址到python爬虫里面,改一下存储为.mp4
import requests
import re
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac 0S X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/52.0.2743.116 Safari/537.36'}
r =requests.get("https://113-219-141-2.ksyungslb.com/upos-sz-mirrorks32u.acgvideo.com/upgcxcode/63/76/19157663/19157663-1-48.mp4?e=ig8euxZM2rNcNbKVhwdVhoMMhwdVhwdEto8g5X10ugNcXBlqNxHxNEVE5XREto8KqJZHUa6m5J0SqE85tZvEuENvNC8xNEVE9EKE9IMvXBvE2ENvNCImNEVEK9GVqJIwqa80WXIekXRE9IMvXBvEuENvNCImNEVEua6m2jIxux0CkF6s2JZv5x0DQJZY2F8SkXKE9IB5QK==&deadline=1562826409&gen=playurl&nbs=1&oi=1947754487&os=ks3u&platform=pc&trid=28dcba5166d84f6f8b078fccbdd41f2e&uipk=5&upsig=cae257a7f3504f28137a3036304288df&uparams=e,deadline,gen,nbs,oi,os,platform,trid,uipk&mid=32059965&ksy_gslb_referer=https%3A%2F%2Fwww.bilibili.com%2Fvideo%2Fav11592898", headers=headers)
with open('Vae.mp4','wb') as f:
f.write(r.content)
网页数量少的动态网站的爬虫
网站介绍
这个网站是这样的,他的信息是js动态加上去的,而且必须登录之后才能看到数据
所以我使用BeautifulSoup在线爬不行,我不会
使用了Selenium登录了,也动态加载页面了,数据也出来了,但是这个网站特别的不规则,
都没有class,我不好找规律,也是不会写......
解决办法
大佬给我提出个办法,因为这个网站的页面不多,也就20几个,让我直接保存到本地,然后读取本地的html爬虫,这样就可以使用BeautifulSoup了,不错哦
我的智障做法
我直接在网页上按下了ctrl+s,保存到了本地.........
注意啊!! ctrl+s保存的网页还是没有数据的啊,还是需要js加载的啊......我忙活了半天,白忙活了
正确的做法
大佬得知此事之后,痛心疾首,说我早就和你说了,复制DOM就可以了,你不听 🐷
对此我只能说,我是🐷,我是🐷,我是🐷
正确的做法是,选择这该死的DOM,右键,复制HTML,这样他的数据啥的,全都有
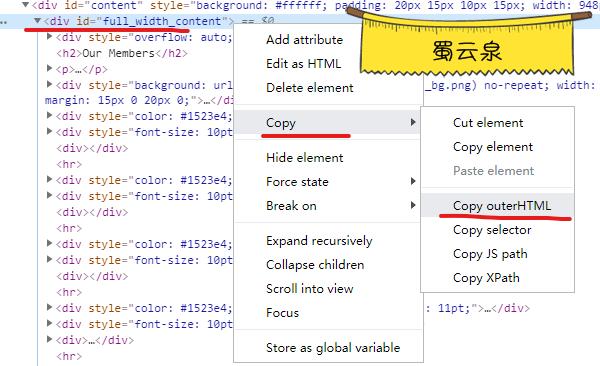
我是一个一个复制了,然后保存到我的本地html了
如果是很多的话,成百上千的网页,这样就不适合手动了,可以使用Selenium加载之后保存到本地
python爬虫代码
我不会放出所有的,写写重点
爬虫爬本地HTML
首先要安装一个爬本地HTML的包
pip install requests-file
from requests_file import FileAdapter
def get_one_page(file_name):
s = requests.Session()
s.mount('file://', FileAdapter())
html = s.get(f'file:///D:/'+file_name+'.html')
soup = BeautifulSoup(html, 'lxml')
...省略...

