

大数据基础工程技术团队4篇论文入选ICLR,ICDE,WWW
近日,由阿里云计算平台大数据基础工程技术团队主导的四篇时间序列相关论文分别被国际顶会ICLR2024、ICDE2024和WWW2024接收。
论文成果是阿里云与华东师范大学、浙江大学、南京大学等高校共同研发,涉及时间序列与智能运维结合的多个应用场景。包括基于Pathways架构的自适应多尺度时间序列预测模型Pathformer;基于扰动技术的时间序列解释框架ContraLSP;多正常模式感知的频域异常检测算法MACE;轻量数据依赖的异常检测重训练方法LARA。此次,时间序列相关模型等多篇论文的入选,表明阿里云在大数据基础技术领域的研究得到了国际学术界的认可,不仅展示了阿里云的技术竞争力,也创造了更多国际合作交流的可能性。
- ICLR(International Conference on Learning Representations)会议是机器学习和深度学习领域的顶级国际会议,与NeurIPS、ICML并称为机器学习三大顶级会议,在谷歌的全领域学术指标排行榜中位列前十,以展示人工智能、统计学和数据科学领域的深度学习各个方面的前沿研究以及机器视觉、计算生物学、语音识别、文本理解、游戏和机器人等重要应用领域而闻名全球。
- ICDE(IEEE International Conference on Data Engineering) 是数据库研究领域历史悠久的国际会议,与SIGMOD、VLDB并称为数据库三大顶级会议,会议聚焦于设计,构建,管理和评估高级数据密集型系统和应用等前沿研究问题。
- WWW(The Web Conference)是为交叉,新兴,综合领域的顶级会议,CCF-A类,会议关注万维网的未来发展,汇聚全世界相关的科研工作者、从业者和领域专家,共同讨论互联网的发展、相关技术的标准化以及这些技术对社会和文化的影响。
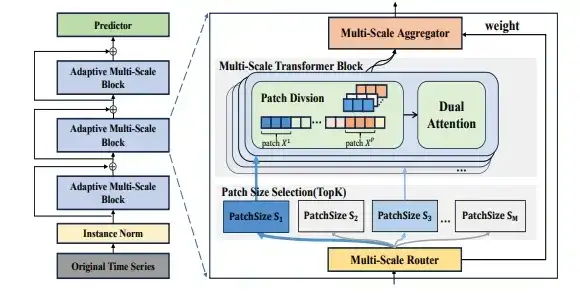
Pathformer:基于Pathways架构的自适应多尺度时间序列预测模型
现实场景中的时间序列在不同的时间尺度展现出不同的变化,如云计算场景中的CPU,GPU,内存等资源需求呈现出日、月、季节等独特尺度的时间模式。这为时间序列预测带来一定的困难。一个好的时间序列预测模型需要考虑完备的时序多尺度建模能力以及进一步自适应选择多尺度的能力。
基于Transformer模型的多尺度建模,主要有两个挑战。
1. 不完备的多尺度建模。只是针对时间分辨率不能有效地捕捉不同范围的时间依赖关系,相反,考虑时间距离虽然能提取不同范围的时间依赖,但全局和局部间隔受到数据划分的影响,单一的时间分辨率并不完备。
2. 固定地多尺度建模过程。对所有时序采用固定的多尺度建模阻碍了每个时序的重要特征捕捉,然而为每个数据集或每个时序手动调整最佳尺度非常耗时且难以处理。
针对这些问题,我们提出了一个基于Pathways架构的自适应多尺度Transformer模型 Pathformer,它整合了时间分辨率和时间距离提出了一个多尺度Transfomer模块,使用双重注意力机制建模局部和全局的时间依赖关系,使模型具备完备的多尺度建模能力。其次,我们提出自适应pathways,激活Transformer的多尺度间建模能力。它基于输入时序逐层地路由和聚合多尺度特征形成了自适应pathways的多尺度建模,可以提升模型的预测效果和泛化性。
ContraLSP:基于对比稀疏扰动技术的时间序列解释框架
在智能运维等领域,为机器学习模型所做的预测提供可靠的解释具有极高的重要性。现有的解释方法涉及使用显著性方法,这些方法的解释区分取决于它们与任意模型的交互方式。一些工作建立了显著图,例如,结合梯度或构造注意力机制,以更好地处理时间序列特征,而它们难以发现时间序列模式。其他替代方法,包括Shapley值或LIME,通过加权线性回归在局部近似模型预测,为我们提供解释。这些方法主要提供实例级别的显著图,但特征间的互相关常常导致显著的泛化误差。在时间序列中最常见的基于扰动的方法通常通过基线、生成模型或使数据无信息的特征来修改数据,但这些扰动的非显著区域并不总是无意义的并且存在不在数据分布内的样本,导致解释模型存在偏差。
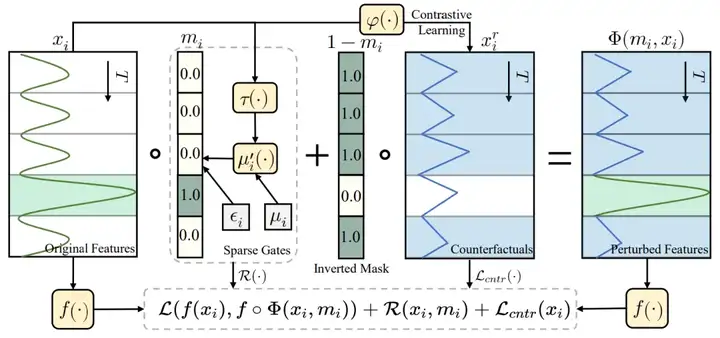
基于此,本文提出了ContraLSP框架,该框架如图所示。这是一个局部稀疏解释模型,它通过引入反事实样本来构建无信息扰动同时保持样本分布。此外,我们融入了特定于样本的稀疏门控机制来生成更倾向于二值化且平滑的掩码,这有助于简洁地整合时间趋势并精选显著特征。在保证标签的一致性条件下,其整体优化目标为:
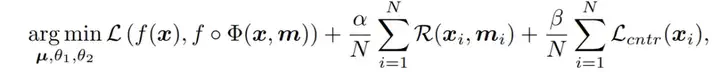
论文在白盒时序预测,黑盒时序分类等仿真数据,和真实时序数据集分类任务中进行了实验,ContraLSP在解释性能上超越了SOTA模型,显著提升了时间序列数据解释的质量。
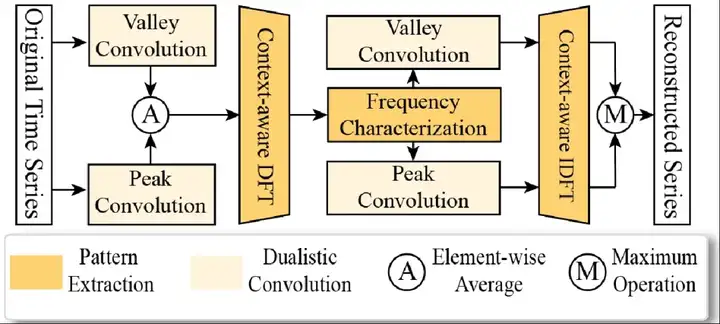
MACE:多正常模式感知的频域异常检测算法
异常检测是智能运维领域的重要研究方向。近来,基于重构类方法的异常检测模型独占鳌头,在无监督异常检测中达到了很高的准确度,涌现了大量优秀的神经网络模型,例如:基于RNN类的神经网络OmniAnomaly, MSCRED; 基于transformer类的神经网络AnomalyTransformer, DCdetector等,但这类方法一个模型只能较好地捕捉一种或少数几种正常模式。因此,涌现出了一批以元学习为辅助,快速适应不同正常模式的异常检测模型,例如PUAD, TranAD等。但这些方法依然要求对不同的正常模式定制不同的模型,当存在十万级不同正常模式的服务时,很难维护这么多神经网络模型。
与其他神经网络直接从数据样本中判断当前样本是否为异常不同,MACE从数据样本与该数据样本对应的正常模式的关系中提取异常。在MACE中,我们首先提出使用频域表征机制提取出正常模式的频域子空间,并使用频域表征技术把当前数据样本映射到该频域子空间中。若该数据样本离这个正常模式的频域子空间越远则在映射后,映射点与原始样本距离越远,重构误差越大。若该数据样本离这个频域子空间的频域子空间越近,则在映射后,映射点与原始样本距离越近,重构误差越小。因此,我们可以根据当前数据样本与其对应的正常模式频域子空间的关系,令对于当前正常模式而言的正常数据重构误差远小于异常数据的重构误差,以此检测异常。更进一步,我们提出上下文感知的傅里叶变换和反变换机制,有效利用频域的稀疏性提升计算效率,在频域上不存在时序依赖,可以对该模型进行细粒度的高并发实现,进一步减少异常检测的时间开销。另外,我们提出Peak Convolution与Valley Convolution机制对短期异常进行增强使其更容易被检测到。
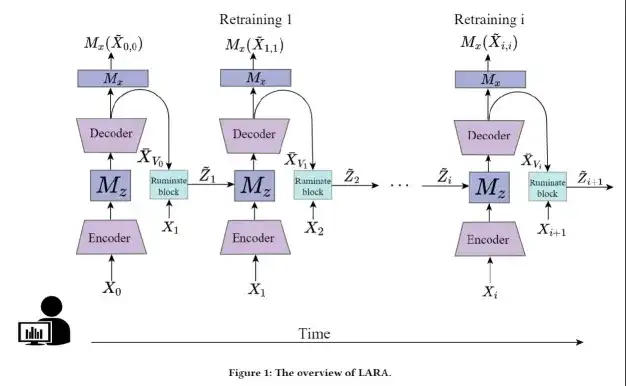
LARA:轻量数据依赖的异常检测重训练方法
在云服务的监控场景中,经常出现正常模式随时间不断变化,且在变化初期观测数据数量不足以支撑模型训练的问题。目前,可以解决正常模式更替变化的方法主要有迁移学习、元学习、基于信号处理的方法。但同时他们也存在一些弊端,并不完全适配当前问题。例如迁移学习未考虑本问题中多个历史正常模式之间存在的时序关系。元学习同样未考虑历史正常模式之间的时序关系,同时,需要存储大量的历史数据。基于信号处理的方法,这类方法推理阶段时间开销太大,无法在流量峰值处进行实时异常检测。
因此,我们提出方法LARA解决上述问题。为了解决重训练新观测数据不足的问题,我们提出反刍模块,该模块使用老模型恢复历史分布中与新观测数据相似的数据,并使用历史数据与新观测数据一起估计每一个新观测数据的隐藏状态z。为了解决重训练计算开销大的问题,我们使用映射函数M_z和M_x分别把老模型输出的隐藏状态和重构数据映射为当前分布的隐藏状态估计值与新观测数据,并数学证明了映射函数令映射误差最小的最优形式为线性,极大降低了重训练开销。更进一步,我们根据M_z 与M_x的形式,提出一种相应的损失函数设计范式,可以保证重训练问题是一个凸问题,具有唯一全局最优解,从而保证较快的收敛速率,降低重训练计算开销,避免陷入过拟合。
论文链接
1.论文标题:Pathformer: Multi-Scale Transformers With Adaptive Pathways For Time Series Forecasting
- 论文作者:陈鹏, 张颖莹, 程云爻, 树扬, 王益杭, 文青松, 杨彬, 郭晨娟
- 论文链接:https://openreview.net/pdf?id=lJkOCMP2aW
- 代码链接:https://github.com/alibaba/sreworks-ext/tree/main/aiops/Pathformer_ICLR2024
2.论文标题:Explaining Time Series via Contrastive and Locally Sparse Perturbations
- 论文作者:刘子川,张颖莹,王天纯,王泽凡,骆东升,杜梦楠,吴敏,王毅,陈春林,范伦挺,文青松
- 论文链接:https://openreview.net/pdf?id=qDdSRaOiyb
- 代码链接:
https://github.com/alibaba/sreworks-ext/tree/main/aiops/ContraLSP
3.论文标题:Learning Multi-Pattern Normalities in the Frequency Domain for Efficient Time Series Anomaly Detection
- 论文作者:陈飞佚,张颖莹,秦臻,范伦挺,姜仁河,梁宇轩,文青松,邓水光
- 论文链接:https://arxiv.org/abs/2311.16191
4.论文标题:LARA: ALight and Anti-overfitting Retraining Approach for Unsupervised Time Series Anomaly Detection
- 论文作者:陈飞佚,秦臻,周孟初,张颖莹,邓水光,范伦挺,庞观
- 论文链接:https://arxiv.org/abs/2310.05668
本文为阿里云原创内容,未经允许不得转载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2022-05-20 重磅发布 | Serverless 应用中心:Serverless 应用全生命周期管理平台
2022-05-20 浅析微服务全链路灰度解决方案
2022-05-20 作业帮在线业务 Kubernetes Serverless 虚拟节点大规模应用实践
2022-05-20 企业实践|分布式系统可观测性之应用业务指标监控
2022-05-20 MAE 自监督算法介绍和基于 EasyCV 的复现
2021-05-20 参与 Apache 顶级开源项目的 N 种方式,Apache Dubbo Samples SIG 成立!
2021-05-20 Serverless:这真的是未来吗?(二)