Pandas是什么
Pandas是一个十分强大的python数据分析工具,也是各种数据建模的标准工具。Pandas擅长处理数字型数据和时间序列数据。Pandas的第一大优势在于,封装了一些复杂的代码实现过程,只需要调用接口就行了,避免了编写大量的代码。Pandas的第二大优势在于灵活性,可以实现自动化批量化处理复杂的逻辑,这些工作是Excel等工具是无法完成的。因而Pandas介于Excel和自主编写程序之间,兼具灵活性和简洁性的数据分析工具。
在输入上,Pandas支持读取多种格式的文件,包括csv、orc、xml、json,也支持读取分布式文件系统HDFS,此外还支持通过jdbc协议读取mysql或兼容mysql协议的数仓。输入的数据会转换成内存中的数据结构DataFrame,之后的数据分析就是围绕着DataFrame进行。
在输出上,pandas可以实现非常震撼的可视化效果,对接众多赏心悦目的可视化库,可以实现动态数据交互效果。
pandas毕竟是一种python脚本语言,性能上一般,只能处理少量数据,跟现代化的数仓的计算能力差别是比较大的。但是如此灵活的pandas分析,能否和数仓相结合,赋予数仓更灵活的数据分析能力,同时获得大规模数据的分析能力呢?
SQL语言的优势和缺点
SQL是目前使用最为广泛的数据分析语言,SQL自从1980年代在IBM研发出来之后,立即成为各种数据分析系统的标准语言。究其原因,SQL是一种声明式语法,用户只需要声明想要的结果,不必指定获取结果的过程。这种方式有两个好处,一方面,如何以最高性能最小代价获得计算结果,需要编写复杂的算法,乃至了解机器的硬件特性,这需要专门的数据库内核工程师才能做到;对于数据分析师而言,这个要求有点过于复杂。因而声明式语法,解放了数据分析师的工作量,降低了数据分析门槛,扩大了SQL的受众。另一方面,没有指定运行过程,则给了数据库内核工程师们更大的自由度去生成最佳的执行计划。这是SQL的优势。
SQL的理论基础来自于关系代数,任何一个操作的对象都是关系,任何操作的结果也是一个关系。关系+操作生成一个新的关系。任何时刻,用户都可以看到一个关系实体。这套极强的理论基础,可以让一个SQL语句无限扩展,在任意时刻都能获得一个关系,再附加一个操作,变成另外一个关系。
由于SQL是基于关系代数和关系模型,关系模型中的关系这个实体,我们可以把它想象成一个二维的表格包含多行多列,行数无限制,而列数则是有限制的。行数是动态的,可以是0行,也可以是无限行。列数则是静态的,不可变更的,不管有无数据,都是固定的列数输出。静态列的这种方法,也限制了SQL在一些场景的应用。两个典型的场景是矩阵转置或者生成透视表(交叉表)。这两种场景下,列的个数都是动态的。因而SQL需要部分借助于编程才能实现完整的数据分析。
SLS SQL的优势
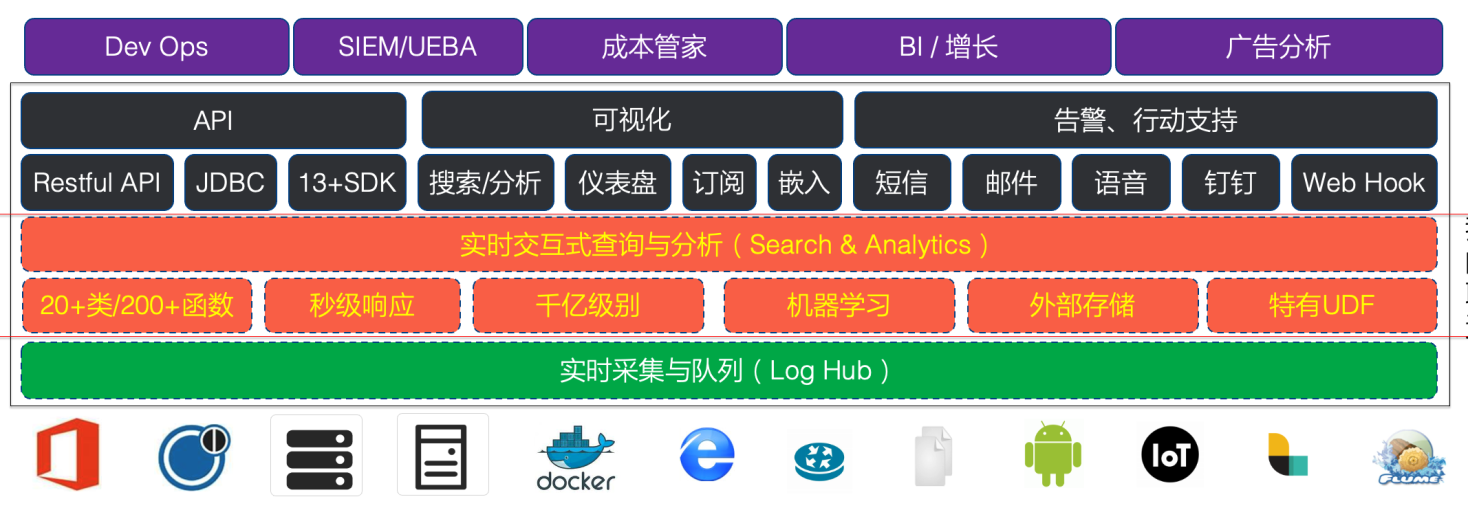
SQL只是一个语法表现成,是用户和数仓系统交互的语言。而数仓的真正强大之处在于它的内核。SLS日志数仓,采用SQL为语法接口,借助于云原生的分布式架构,可以实现query级别的弹性分析能力,可以实现单次分析千亿条数据的能力。
Pandas具备分析灵活性,SLS具备强大的SQL分析能力。两者融合,既能享受SLS强大的SQL分析能力,又能借助Pandas的灵活的数据分析和分析库。那么两者怎么结合呢?
Pandas连接SLS 做融合分析
Pandas支持jdbc接口读取数据,SLS也支持jdbc协议。因而Pandas可以通过jdbc协议连接SLS。对于分析任务中的比较重的计算,通过SQL传递给SLS计算;对于比较灵活的分析、SQL完成不了的分析,则在Pandas上做二次分析和可视化。例如构建透视表或者交叉表:先通过SQ L完成两个维度的交叉计算,这个过程往往计算量比较大;再通过Pandas完成行列转换,展示成二维表。
一个例子:
import numpy as np
import pandas as pd
import pymysql
# sql 命令
slshost=""
username=""
password=""
dbname="" # project is database
sql_cmd = "select method,status ,count(1) as pv from access_log group by method, status limit 1000"
con = pymysql.connect(host=slshost, port=10005,user=username, password=password, database=dbname, charset='utf8', use_unicode=True)
data = pd.read_sql(sql_cmd, con)
tab=pd.pivot_table(data,values="pv",index="status",columns="method" )
print(tab)
例子中的SQL,分析nginx访问日志,计算method和status两个维度的pv。再调用pandas的pivot_table函数构建透视表。
执行结果如下图:





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2021-08-17 “不服跑个分?” 是噱头还是实力?
2021-08-17 JVM性能提升50%,聊一聊背后的秘密武器Alibaba Dragonwell
2021-08-17 ARMv9刷屏 —— 号称十年最大变革,Realm机密计算技术有什么亮点?
2021-08-17 Forrester云原生开发者洞察白皮书,低代码概念缔造者又提出新的开发范式
2021-08-17 揭秘阿里云 RTS SDK 是如何实现直播降低延迟和卡顿
2020-08-17 我们为什么要做 SoloPi