
模拟IDC spark读写MaxCompute实践
一、背景
1、背景信息
现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。
2、基本架构

二、搭建开发环境
1、EMR环境准备
(1)购买
① 登录阿里云控制台 - 点击右上角控制台选项 https://www.aliyun.com/accounttraceid=bc277aa7c0c64023b459dd695ac328b1jncu

② 进入到导航页 - 点击云产品 - E-MapReduce(也可以搜索)
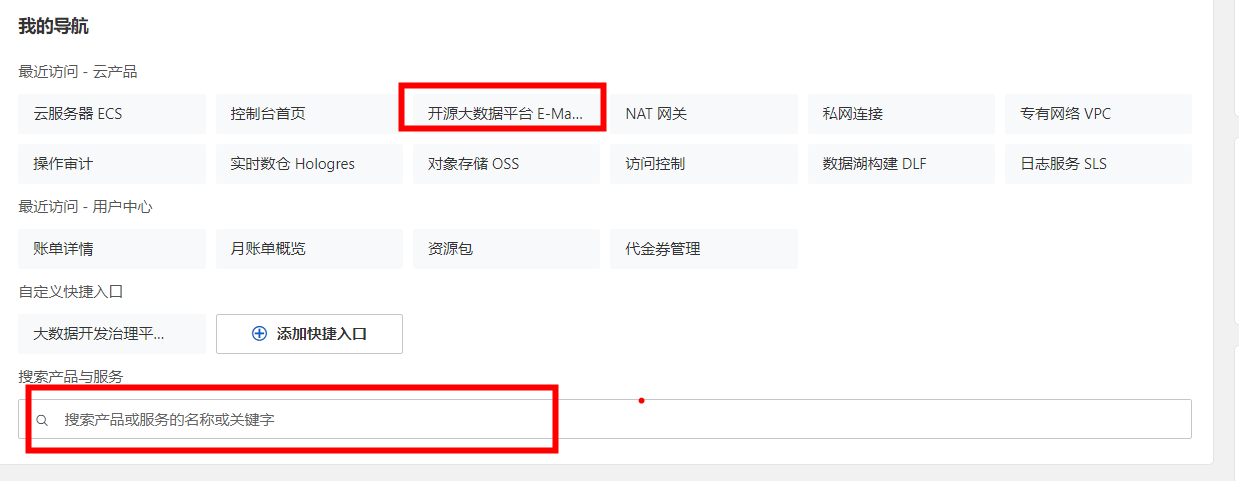
③ 进入至 E-MapReduce 首页,点击 EMR on ECS - 创建集群
-- 具体购买细节参考官方文档 https://help.aliyun.com/document_detail/176795.html#section-55q-jmm-3ts
④ 点击集群ID 可查看集群的基础信息、集群服务以及节点管理等模块
(2)登录
-- 详细登录集群方式可参考官方文档 https://help.aliyun.com/document_detail/169150.html
-- 本文以登录ECS实例操作
① 点击阿里云首页控制台 - 云服务器ECS
https://www.aliyun.com/product/ecs?spm=5176.19720258.J_3207526240.92.542b2c4aSz6c39
② 点击实例名称 - 远程连接 - Workbench远程连接
2、本地IDEA准备
(1)安装maven
-- 可参考文档 https://blog.csdn.net/l32273/article/details/123684435
(2)创建Scala项目
① 下载Scala插件
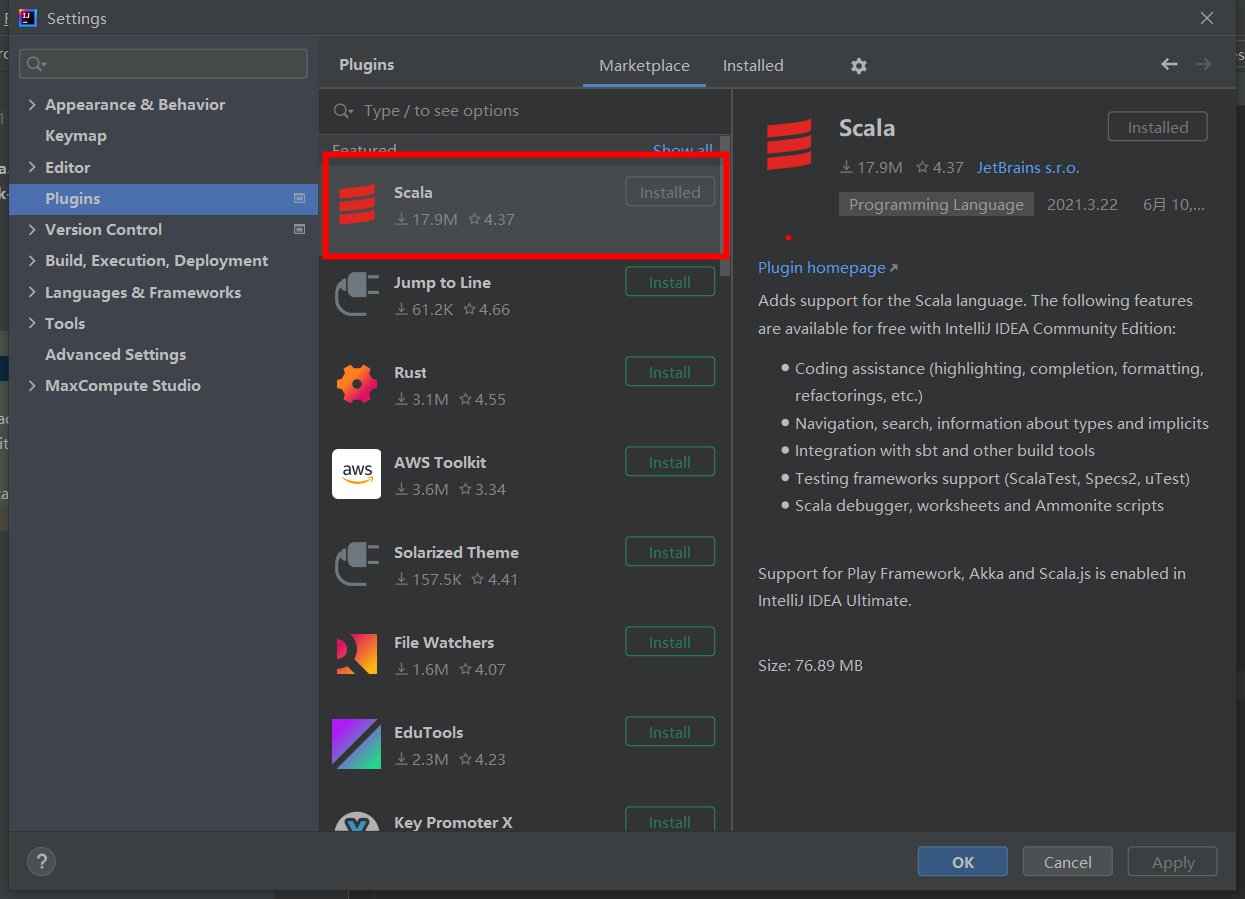
② 安装 Scala JDK
-- 建议下载 *.zip 文件
-- 配置 Scala 环境变量
-- 通过 Win + R 打开 cmd 测试是否出现 Scala版本
-- 可参考文档: https://blog.csdn.net/m0_59617823/article/details/124310663
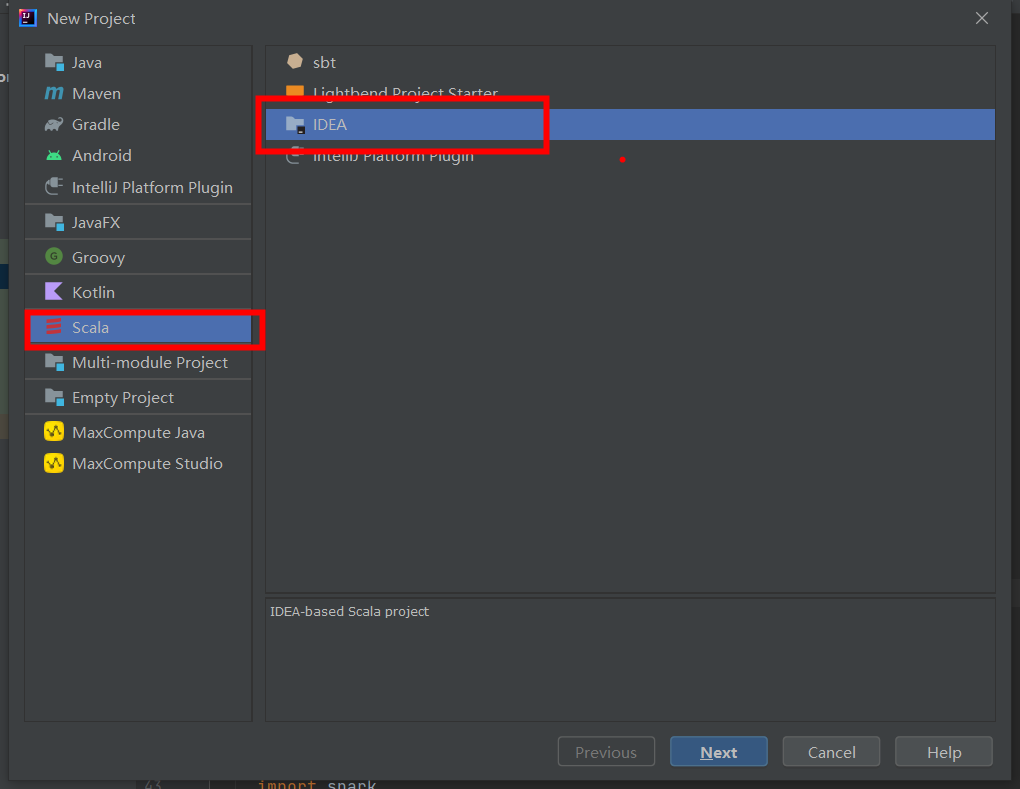
③ 创建 Scala 项目
3、MaxCompute数据准备
(1)Project
-- MaxCompute 创建 project 可参考官方文档: https://help.aliyun.com/document_detail/27815.html
(2)AccessKey
-- 简称AK,包括AccessKey ID和AccessKey Secret,是访问阿里云API的密钥。在阿里云官网注册云账号后,可以在AccessKey管理页面生成该信息,用于标识用户,为访问MaxCompute、其他阿里云产品或连接第三方工具做签名验证。请妥善保管AccessKey Secret,必须保密,如果存在泄露风险,请及时禁用或更新AccessKey。
-- 查找 ak 可参考官方文档
https://ram.console.aliyun.com/manage/ak?spm=a2c4g.11186623.0.0.24704213IXakh3
(3)Endpoint
-- MaxCompute服务:连接地址为Endpoint,取值由地域及网络连接方式决定
-- 各地域 endpoint 可参考官方文档:https://help.aliyun.com/document_detail/34951.html
(4)table
-- MaxCompute 创建表可参考官方文档 https://help.aliyun.com/document_detail/73768.html
-- 本文需准备分区表和非分区表,供测试使用
三、代码测试
1、前提条件
(1)准备 MaxCompute 上的project、ak信息以及表数据
(2)准备 E-MapReduce集群
(3)终端连接 E-MapReduce节点(即 ECS 实例)
(4)本地 IDEA 需配置 Scala 环境变量、maven 环境变量 并下载 Scala 插件
2、代码示例
3、打包上传
(1)本地写好代码后,maven 打包
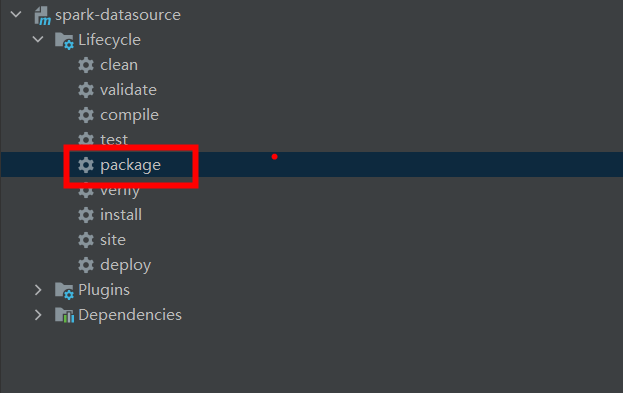
(2)本地编译jar包
① 进入project目录
cd ${project.dir}/spark-datasource-v3.1
② 执行mvn命令构建spark-datasource
mvn clean package jar:test-jar

③ 查看 target 目录下是否有 dependencies.jar 和 tests.jar
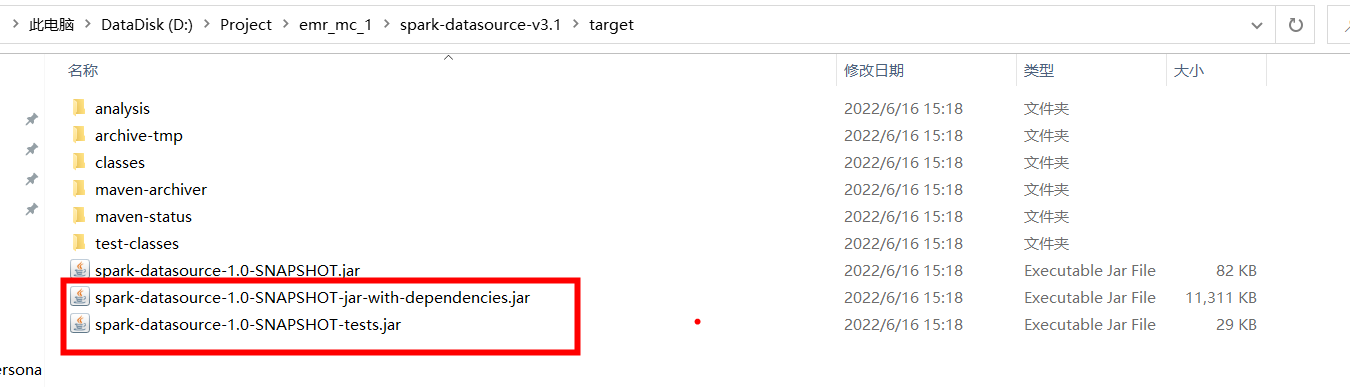
(3)打好的 jar 包上传至服务器
① scp 命令上传
scp [本地jar包路径] root@[ecs实例公网IP]:[服务器存放jar包路径]

② 服务器查看

③ 各节点之间上传 jar 包
scp -r [本服务器存放jar包路径] root@ecs实例私网IP:[接收的服务器存放jar包地址]

4、测试
(1)运行模式
① Local 模式:指定 master 参数为 local
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② yarn 模式:指定master 参数为 yarn、代码中 endpoint 选择以 -inc 结尾
代码:val ODPS_ENDPOINT = "http://service.cn-beijing.maxcompute.aliyun-inc.com/api"
./bin/spark-submit \
--master yarn \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
(2)读非分区表表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果

(2)读分区表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行界面

③ 执行结果

(3)写非分区表表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果
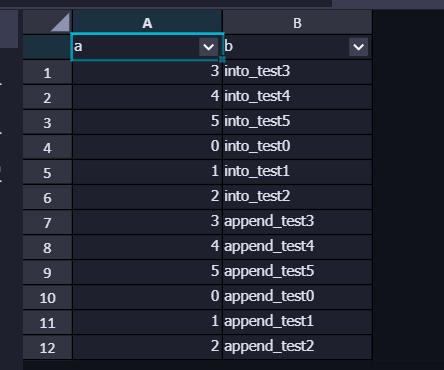
(4)写分区表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行过程

③ 执行结果

5、性能测试
-- 由于实验环境是 EMR 和 MC ,属于云上互联,如果 IDC 网络与云上相连取决于 tunnel 资源或者专线带宽
(1)大表读测试
-- size:4829258484 byte
-- partitions : 593个
-- 读取分区 20170422
-- 耗时: 0.850871 s

(2)大表写测试
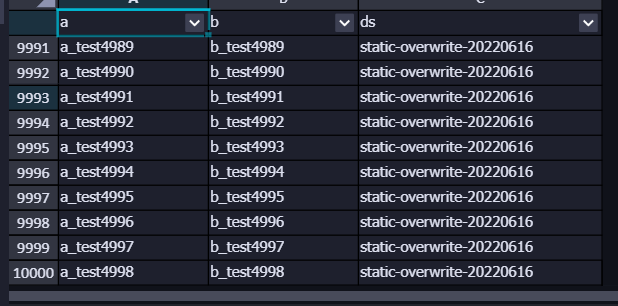
① 分区写入 万条 数据
-- 耗时:2.5s

-- 结果
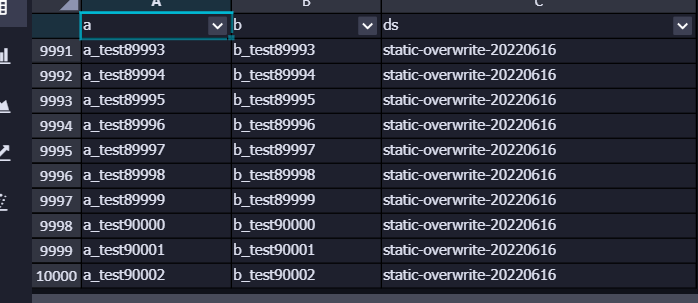
② 分区写入 十万条 数据
-- 耗时:8.44 s

-- 结果:
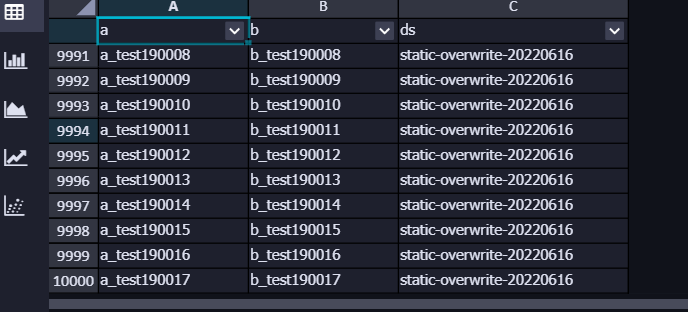
③ 分区写入 百万条 数据
-- 耗时:73.28 s

-- 结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号