

详解异步任务:函数计算的任务触发去重
前言
无论是在大数据处理领域,还是在消息处理领域,任务系统都有一个很关键的能力 - 任务触发去重的保障。这个能力对于一些准确性要求极高的场景中(如金融等)是必不可少的。作为 Serverless 化任务处理平台,Serverless Task 也需要提供这类保障,在用户应用层面及自身系统内部两个维度具备任务的准确触发语义。本文主要针对消息处理可靠性这一主题来介绍函数计算内部的一些技术细节,并展示如何在实际应用中使用函数计算所提供的这方面能力来增强任务执行的可靠性。
浅谈任务去重
在讨论异步消息处理系统时,消息处理的基本语义是无法绕开的话题。在一个异步的消息处理系统(任务系统)中,一条消息的处理流程简化如下图所示:
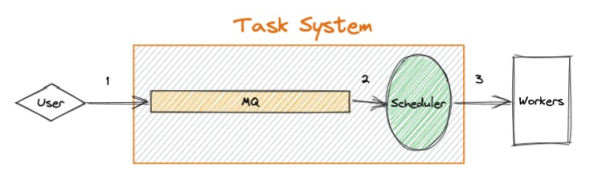
图 1
用户下发任务 - 进入队列 - 任务处理单元监听并获取消息 - 调度到实际 worker 执行
在任务消息整个的流转过程中,任何组件(环节)可能出现的宕机等问题会导致消息的错误传递。一般的任务系统会提供至多 3 个层级的消息处理语义:
●At-Most-Once:保证消息最多被传递一次。当出现网络分区、系统组件宕机时,可能出现消息丢失;
●At-Least-Once:保证消息至少被传递一次。消息传递链路支持错误重试,利用消息重发机制保证下游一定收到上游消息,但是在宕机或者网络分区的场景下,可能导致相同消息传递多次。
●Exactly-Once机制则可以保证消息精确被传送一次,精确一次并不是意味着在宕机或网络分区的场景下没有重传,而是重传对于接受方的状态不产生任何改变,与传送一次的结果一样。在实际生产中,往往是依赖重传机制 & 接收方去重(幂等)来做到 Exactly Once。
函数计算能够提供任务分发的 Exactly Once 语义,即无论在何种情况下,重复的任务将被系统认为是相同的触发,进而只进行一次的任务分发。
结合图 1,如果要做到任务去重,系统至少需要提供两个维度的保障:
1、系统侧保障:任务调度系统自身的 failover 不影响消息的传递正确性及唯一性;
2、提供给用户一种机制,可以做到整个业务逻辑的触发去重语义。
下面,我们将结合简化的 Serverless Task 系统架构,谈一谈函数计算是如何做到上面的能力的。
函数计算异步任务触发去重的实现
函数计算的任务系统架构如下图所示

图 2
首先,用户调用函数计算 API 下发一个任务(步骤 1)进入系统的 API-Server 中,API-Server 进行校验后将消息传入内部队列(步骤 2.1)。后台有一个异步模块实时监听内部队列(步骤 2.2),之后调用资源管理模块获取运行时资源(步骤 2.2-2.3)。获取运行时资源后,调度模块将任务数据下发到 VM 级别的客户端中(步骤 3.1),并由客户端将任务转发至实际的用户运行资源(步骤 3.2)。为了做到上文中所提到的两个维度的保障,我们需要在以下层面进行支持:
1、系统侧保障:在步骤 2.1 - 3.1 中,任何一个中间过程的 Failover 只能触发一次步骤 3.2 的执行,即只会调度一次用户实例的运行;
2、用户侧应用级别去重能力:能够支持用户多次反复执行步骤 1,但实际只会触发一次 步骤 3.2 的执行。
系统侧优雅升级 & Failover 时的任务分发去重保证
当用户的消息进入函数计算系统中(即完成步骤 2.1)后,用户的请求将收到 HTTP 状态码 202 的 Response,用户可以认为已经成功提交一次任务。从该任务消息进入 MQ 起,其生命周期便由 Scheduler 维护,所以 Scheduler 的稳定性及 MQ 的稳定性将直接影响系统 Exactly Once 的实现方案。
在大多数开源消息系统中(如 MQ、Kafka)一般都提供消息多副本存储及唯一消费的语义。函数计算所使用的消息队列(最底层为 RocketMQ)也是同样的,底层存储的 3 副本实现使得我们无需关注消息存储方面的稳定性。除此之外,函数计算所使用的的消息队列还具有以下特性:
1、消费的唯一性:每一个队列中的每一条消息当被消费后,会进入“不可见模式”。在此模式下,其他消费者无法获取该消息;
2、每条消息的实际消费者需要实时更新该模式的不可见时间;当消费者消费完成后,需要显示的删除该消息。因此,消息在队列中的的整个生命周期如下图所示:
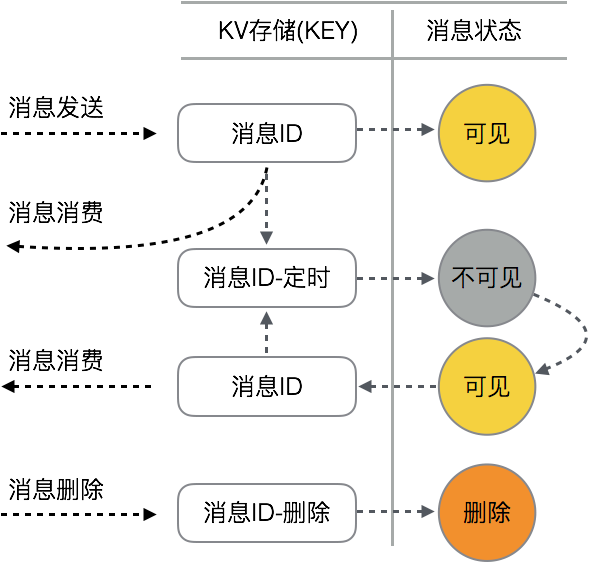
图 3
Scheduler 主要负责消息的处理,其任务主要有以下几个部分组成:
1、根据函数计算负载均衡模块的调度策略,监听自身所负责的队列;
2、当队列中出现消息后,拉取消息,并在内存中维持一个状态:直到消息消费完成(用户实例返回函数执行结果)前,不断更新消息的可见时间,确保消息不会再次在队列中出现;
3、当任务执行完成后,显示删除该消息。
在队列的调度模型方面,函数计算对于普通用户采用“单队列”的管理模式;即每一个用户的所有异步执行请求由一个独立队列相互隔离,并且由一个 Scheduler 固定负责。这个负载的映射关系由函数计算的负载均衡服务进行管理,如下图所示(我们在后续文章中还会更为详细的介绍这部分内容):
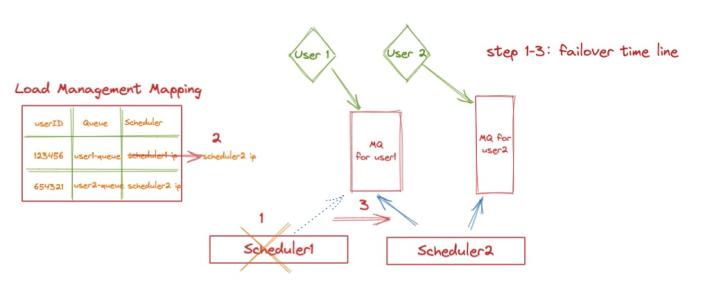
图 4
当 Scheduler 1 发生宕机或升级时,任务由两种执行状态:
1、如果消息还未传递到用户的执行实例中(图 2 中的步骤 3.1 ~ 3.2),那么当这台 Scheduler 负责的队列被其他 Scheduler 拾起后,消息将在消费可见期后再次出现,因此 Scheduler 2 将再次获取该消息,做到后续的触发。
2、如果消息已经开始执行(步骤 3.2),当消息在 Scheduler 2 中再次出现后,我们依赖用户 VM 中的 Agent 进行状态管理。此时 Scheduler 2 将向对应的 Agent 发送执行请求;此时 Agent 发现该消息已经存在于内存中,那么将直接忽略执行请求,并将执行的结果在执行后通过此链接告知 Scheduler 2,进而完成 Failover 的恢复。
用户侧业务级别的分发去重实现
函数计算系统能够做到对于单点故障下的每条消息准确的消费能力,但是如果用户侧对于同一条业务数据反复触发函数执行的话,函数计算无法识别不同消息是否在逻辑上是同一个任务。这种情况往往发生在网络分区。在图 2 中,如果用户调用 1 发生超时,此时有可能有两种情况:
1、消息未到达函数计算系统,任务未成功提交;
2、消息已经到达函数计算并入队,任务提交成功,但由于超时用户无法得知提交成功的信息。
大多数情况下用户会对此次的提交进行重试。如果是第 2 种情况,那么同一个任务将被提交并执行多次。因此函数计算需要提供一种机制,保证这种场景下业务的准确性。
函数计算提供了 TaskID 这一任务概念(StatefulAsyncInvocationID)。该 ID 全局唯一。用户每次提交任务均可以指定这样一个 ID。当发生请求超时时,用户可以进行无限次重试。所有的重复重试将在函数计算侧进行校验。函数计算内部使用 DB 对任务 Meta 数据进行存储;当有相同 ID 进入系统时该次请求将被拒绝,并返回 400 错误。此时客户端即可得知任务的提交情况。
在实际使用中以 Go SDK 为例,您可以编辑如下触发任务的代码:
import fc "github.com/aliyun/fc-go-sdk"
func SubmitJob() {
invokeInput := fc.NewInvokeFunctionInput("ServiceName", "FunctionName")
invokeInput = invokeInput.WithAsyncInvocation().WithStatefulAsyncInvocationID("TaskUUID")
invokeOutput, err := fcClient.InvokeFunction(invokeInput)
...
}
便提交了一个独一无二的任务。
总结
本文介绍了函数计算 Serverless Task 对于任务触发去重的相关技术细节,以便支持对于任务执行准确性有严格要求的场景。在使用 Serverless Task 后,您无需担心任何系统组件的 Failover,您每次提交的任务将被准确执行一次。为了支持业务侧语义的分发去重,您可以在提交任务时设置任务的全局唯一 ID,使用函数计算提供的能力帮您对任务进行去重处理。
原文链接:http://click.aliyun.com/m/1000345950/
本文为阿里云原创内容,未经允许不得转载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2021-06-16 进击的云原生,为开发者提供更多可能性
2021-06-16 分久必合的Lindorm传奇
2021-06-16 雷锋网独家解读:阿里云原生应用的布局与策略
2021-06-16 「技术人生」第4篇:技术、业务、组织的一般规律及应对策略
2021-06-16 云上安全保护伞--SLS威胁情报集成实战
2020-06-16 从 2018 年 Nacos 开源说起