

ZooKeeper 在阿里巴巴的服务形态演进
简介: 本文将给大家介绍下 ZooKeeper 的最佳实践场景,归为了 3 类,分别是:微服务领域,代表的集成产品是 Dubbo/SpringCloud;大数据领域,代表的集成产品是 Flink/Hbase/Hadoop/Kafka;自研的分布式系统,包括大家自己公司内部的分布式系统,对分布式协调有需求,如分布式锁。
作者:草谷 Apache ZooKeeper 在阿里巴巴经历了开源自用、深度优化、反哺社区、开发企业版服务云上客户的演进过程,为了厘清本文脉络,我们对演进过程中提到的关键名词做以下定义。
-
Apache ZooKeeper:提供分布式协调服务如分布式锁、分布式队列等,还可用于注册配置中心的能力。
-
TaoKeepeer:基于 ZooKeeper 做了深度改造,于2008年服务于淘宝。
-
MSE:阿里云的一个面向业界主流开源微服务生态的一站式微服务平台。
-
ZooKeeper 企业服务:MSE 的子产品,提供开源增强的云上服务,分为基础版和专业版两种。
ZooKeeper 在阿里巴巴的服务形态演进历程 早在 2008 年,阿里巴巴基于 ZooKeeper 的开源实现和淘宝的电商业务,设计 Taokeeper 这款分布式协调软件,彼时恰逢淘宝启动服务化改造,那时候,也诞生了各类分布式中间件,例如 HSF/ConfigServer/VIPServer 等。 10 年后的 2019 年,阿里巴巴实施全站上云战役,所有的产品都需要升级到公有云架构,MSE 就是在那个时候诞生的,上线后便兼容了主流的 ZooKeeper 版本。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
整个过程经历了以下 3 个阶段: 第一个阶段:08 年的 1.0 版本,主要支持集团有分布式协调需求的应用,那时候所有的业务都是混着用,有 1000 多个应用,最终大概手动运维着 150+个共享集群。随着时间的推移,业务都在做微服务拆分,共享集群的容量爆炸式增长,这样带来的问题就是:业务混部,爆炸半径大,稳定性存在着很大的风险;日常的运维,例如机器置换等,牵一发而动全身,如果配置出问题,影响所有业务。 第二个阶段:为了解决阶段一的问题,我们将 ZooKeeper 演进到 2.0 版本。那时候正直容器化刚刚兴起,在仔细研究过容器化的改造方案后,我们在性能和运维能够同时满足要求的情况下,进行了大量的改造,业务进行拆分、集群迁移、按最小稳定单元去运维一个集群,这样我们终于可以睡个安稳觉了,拆分完后,依托于 K8s 的规模化运维能力,这些问题都得到了很好的解决,由此实现了独享模式集群、资源隔离,SLA 得到了提升,能到达 99.9%。 第三个阶段:上云提供公共云服务,也就演进到了 3.0。这个版本重点打造了开源增强,例如,基于 Dragonwell 进行构建、JVM 参数调优、集成了 Prometheus、部署形态多 AZ 强制平均打散、支持动态配置 、平滑扩缩容等改造,在性能、免运维、可观测、高可用和安全等方面做了诸多提升,SLA 能够到达 99.95%。

添加图片注释,不超过 140 字(可选)
ZooKeeper 在技术场景上的最佳实践 接下来,给大家介绍下 ZooKeeper 的最佳实践场景,归为了 3 类,分别是:
-
微服务领域,代表的集成产品是 Dubbo/SpringCloud
-
大数据领域,代表的集成产品是 Flink/Hbase/Hadoop/Kafka
-
自研的分布式系统,包括大家自己公司内部的分布式系统,对分布式协调有需求,如分布式锁
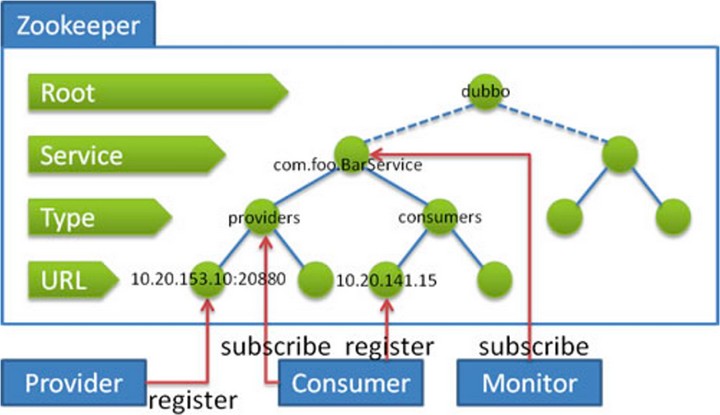
微服务领域-注册中心 ZooKeeper 在微服务场景里面,主要是用作注册中心,利用了 ZooKeeper 的注册/订阅模式,可以看下 Dubbo 在 ZooKeeper 里面的数据结构:
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
在 Provider 启动时,会向 ZooKeeper 固定路径 providers 下面创建一个临时节点, 在这个节点里面存入本机的服务信息,例如,应用名,IP 和端口等,Consumer 启动的时候 ,监听对应服务下 Providers 的所有子节点,ZooKeeper 会把所有子节点信息主动通知到 Consumer,Consumer 此时就拿到所有 Provider 的地址列表信息了,Provider 注册到 ZooKeeper 上面的临时节点,它的生命周期和 Provider 与ZooKeeper 之间建立的长链接时一致的,除非 Provider 主动下线,当 Provider 宕机或者主动下线,这个临时节点就会被删除,那么订阅这个服务的 Consumer 们,会通过 Watch 监听到事件,更新一下地址列表,把它摘除调。
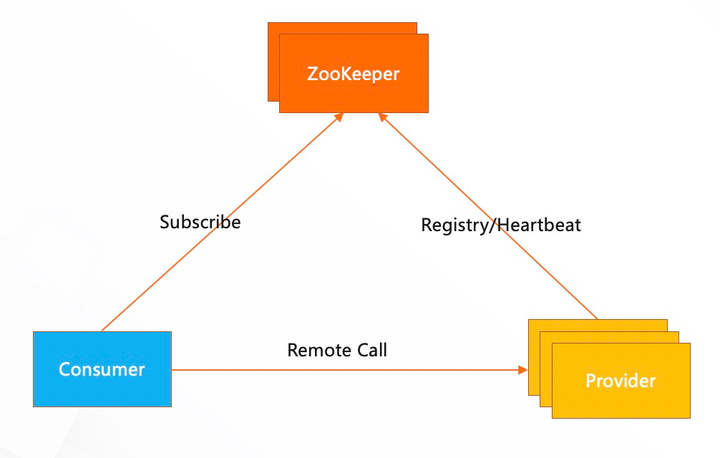
添加图片注释,不超过 140 字(可选)
在这里有 2 个注意的点:
-
注册到 ZooKeeper 的服务数据,不要太多,在 Provider 或者 Consumer 非常多的情况下,频繁上下线的时候,非常容易导致 ZooKeeper FullGC。
-
Provider 在非正常下线时,临时节点的生命周期取决于 SessionTimeOut 的时间,这个可以根据业务自行设置,避免过长或者过短影响业务调用。
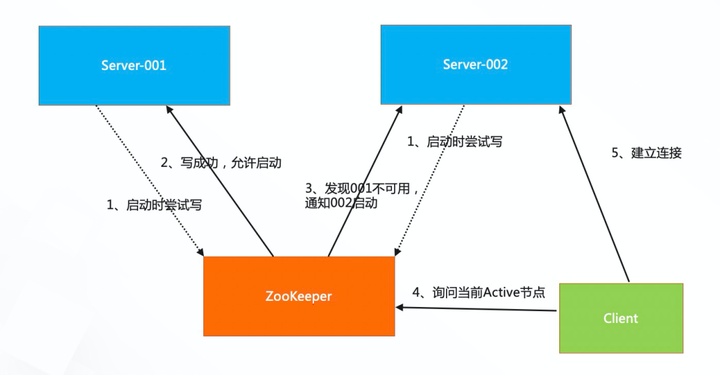
大数据领域-HA 高可用 在大数据领域,Flink/Hadoop/Hbase/Kafka 等系统都默认的把 ZooKeeper 当作分布式协调的组件,在这里面,ZooKeeper 利用自己的特性,帮助它们解决了非常多的分布式问题,其中最主要的就是利用 ZooKeeper 做了 HA(Highly Available)方案,提高集群可用性,一般有两个或两个以上的节点,且分为活动节(Active)点及备用节点(standby)。 下方图例中有 2 个 Server,组成 HA 模式,在 Server 启动的时候,往 ZooKeeper 写入一个约定好的路径下临时节点,由于 ZooKeeper 只允许 1 个写成功,谁先写成功,谁就作为 Active, 并且由 ZooKeeper 通知到集群中其他节点,其他节点则状态改成 standby 状态。 当 Active 节点宕机的时候,ZooKeeper 将节点状态通知下去,其他的 standby 节点立刻往该节点里面写数据,写成功了,就接替成为 Active。 整个流程大概就是这样,这里要注意一个点,就是在网络异常情况下,主备节点切换不那么实时,可能会出现脑裂,也就是存在 2 个主节点的情况,这种情况的话,可以客户端在切换的时候,可以尝试等一等,状态稳定之后,再切换。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
自研系统的分布式协调场景 在自研分布式系统的时候,必然会遇到许多分布式协调的问题,ZooKeeper 就像一个万能的工具箱。 针对不同的场景,基于 ZooKeeper 的特性,都能组合成一个解决方案;在写分布式系统的时候,经常需要用到的有这几个功能:
-
Master 的选举
我们的系统需要选举出来 1 个 Maseter 来执行任务;例如 ScheduleX 就是利用 ZooKeeper 做到这个的,Schedulex 的 Worker 节点有非常多,一些任务是非幂等的,只能由一个进程执行,这时候就需要从众多的 Worker 中选一个 master 来,实现的方式主要有 2 种:
-
抢占主节点的方式:约定一个固定的路径,谁往里面写临时节点数据写成功了,就算当 master,当 Master 宕机后,临时节点会过期释放,ZooKeeper 通知到其他节点,其他节点再继续往里面写数据抢占。
-
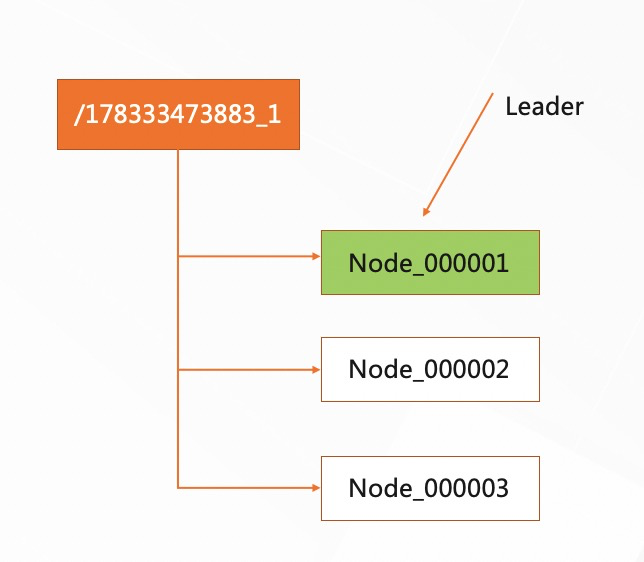
最小节点方式:利用的是 ZooKeeper 的临时有序节点实现的,如图所示:要进行选主的时候,每台 Server 往目录下面写一个临时有序节点,约定好,序号最小的节点作为 master 即可。
添加图片注释,不超过 140 字(可选)
-
分布式锁
在分布式环境中,程序都分布独立的节点中,分布式锁是控制分布式系统之间同步访问共享资源的一种方式,下面介绍下 Zookeeper 如何实现分布式锁,分布式锁主要有 2 种类型: 1、排他锁(Exclusive Locks):称为独占锁,获取到这个锁后,其他的进程都不允许读写 实现的原理也很简单,利用 ZooKeeper 一个具体路径下只能创建一个节点的特性,约定谁创建成功了,就抢到了锁,同时其他节点要监听这个变化,临时节点删除了,可以被通知到去抢(Create),这个和 Master 选举里面抢占 Master 节点,是一样的做法:
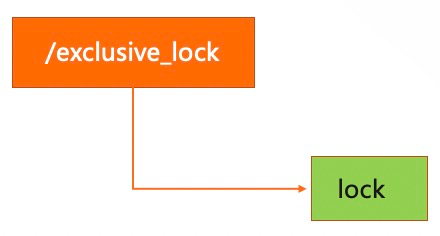
添加图片注释,不超过 140 字(可选)
2、共享锁(Shared Locks):又称为读锁,多个进程可以同时获取这把锁,进行读操作,但是如果要写操作,必须没有读操作了,且自己是第一个获取到写操作类型锁的 实现的方式如图示;读的时候,创建一个 R 的临时顺序节点,如果比他小的节点里面没有 W 节点,那么写入成功,可以读,如果要写,则判断所有 R 的节点中,自己是否最小的即可。
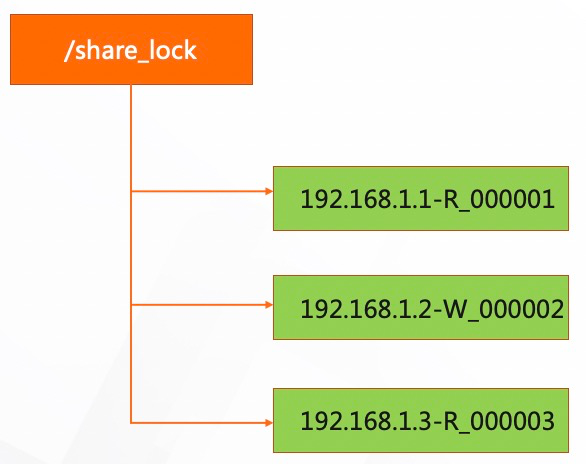
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
-
分布式队列
分布式队列最常见的 FIFO(First Input First Output )先入先出队列模型,先进入队列的请求操作先完成后,才会开始处理后面的请求:
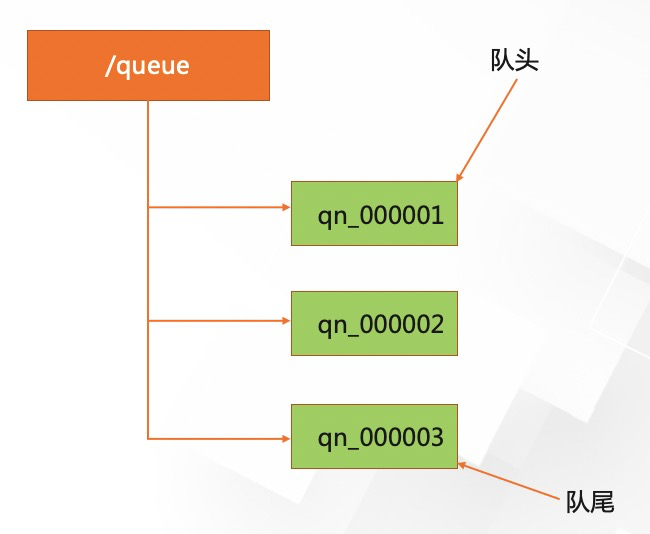
添加图片注释,不超过 140 字(可选)
Zookeeper 实现 FIFO 队列,和共享锁实现类似,类似于一个全写的共享锁模型: 1、获取/Queue 节点下的所有子节点,获取队列中的所有元素 2、确定自己的节点序号在所有子节点中的顺序 3、如果自己的序号不是最小,那么就需要等待,同时向比自己序号小的最后一个节点注册 Watcher 监听 4、接收到 Watcher 通知后,重复第一个步骤
-
配置中心
使用 ZooKeeper 作为配置中心,利用的也是 ZooKeeper 的注册/订阅模式,这里有个注意点,ZooKeeper 不适用于存储太大的数据,一般不超过 1M,否则容易出现性能问题。
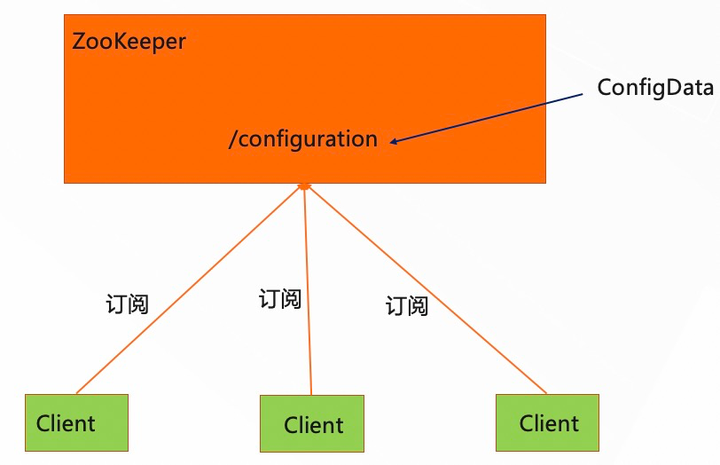
添加图片注释,不超过 140 字(可选)
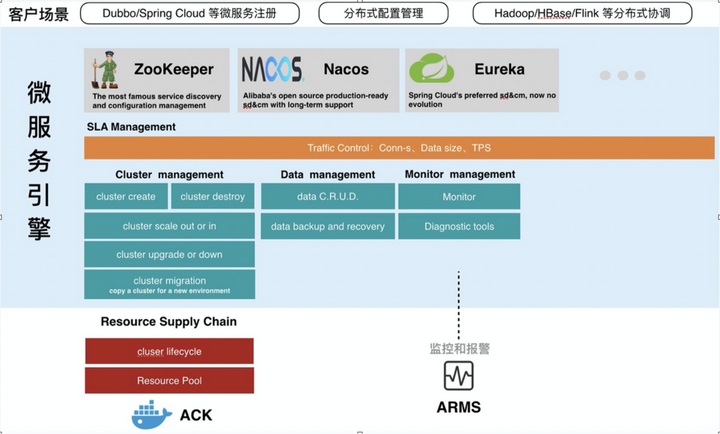
MSE 提供的 ZooKeeper 企业服务 MSE 和 ZooKeeper 的关系 微服务引擎(Micro Service Engine,简称 MSE)是一个面向业界主流开源微服务生态的一站式微服务平台,微服务生态的所有服务都能够在这个平台上面被集成,它提供的引擎都是独立托管的,目的就是为了给大家提供高性能、高可用、高集成、安全的服务,目前,MSE 提供了如下模块:
-
注册配置中心-(ZooKeeper/Nacos/Eureka)
-
云原生网关-(Envoy)
-
分布式事务-(Seata)
-
微服务治理(Dubbo/Spring Cloud/Sentinel/OpenSergo)
ZooKeeper 和 Nacos 一样,提供注册配置中心功能,但是 ZooKeeper 还提供了分布式协调的能力,应用在大数据领域。 MSE 提供的 ZooKeeper 企业服务分为基础版和专业版两种,前者适用于开发测试环境和简单的生产环境,后者在性能、可观测、高可用方便做了诸多提升,接下来,我们将介绍专业版,相比自建的优势。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
比自建的 ZooKeeper 更稳定和高可用
添加图片注释,不超过 140 字(可选)
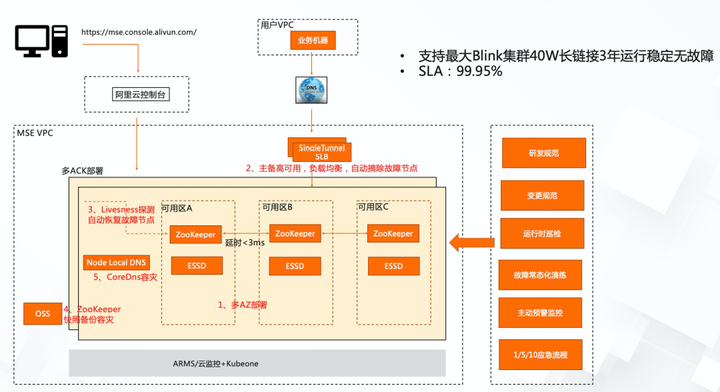
MSE 的产品架构图
-
ZooKeeper 是多 AZ 部署的:大家知道 ZooKeeper 只有过半的节点才能选出主来,当一个 5 节点的 ZooKeeper 集群,部署在 3 个可用区的时候,它应该要 2/2/1 的分布,这样的话,任意一个可用区出现故障,ZooKeeper 整体还是可用的,阿里云 AZ 之间的延时,目前是低于 3ms 的,非常短是可控的。
-
高可用负载均衡:用户节点访问 ZooKeeper 的 endpoint,是 MSE 提供的一个 SingleTunnelSLB,这个 SLB 是一个主备高可用的,它会自动对用户请求做负载均衡,将请求压力分散到后端节点,当后端节点故障时,会自动摘除,保证请求到正常的节点上面。
-
节点故障自愈:依托于 K8s 的 Liveness 能力,在节点出现故障的时候,会自动恢复故障节点,及时的保障服务的可持续性。
-
数据安全:专业版 ZooKeeper 提供了快照的备份能力,在集群出现非预期的情况下 ,能够快速重建恢复集群中的数据,保障数据的安全。
上面介绍的是架构设计上面,对高可用的一个保障。 在研发过程,我们有一套完备的稳定性保障体系:从研发阶段,到最后的变更上线,都有对应的规范制度,例如变更三板斧,在变更时,必须要满足可观测/可回滚/可灰度的情况下才能上线,否则会被打回;在运行时,我们有一系列的巡检组建,配置一致性检查,后面也会不断的完善,巡检出问题,立马需要解决。 MSE 也把故障演练做到了常态化,针对常见的故障场景,例如网络中断,CoreDNS 宕机、ECS 宕机等,都定期在跑着;在线上预警这块,我们也做到了主动探测,及时发现,安排值班人员 24 小时处理,我们有一套 1/5/10 的应急流程,要求在 1 分钟内发现问题,5 分钟解决,10 分钟恢复。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
以上的这些,最终都是为了保障 MSE 的稳定高可用,MSE 线上最大规模的一个集群,支持着 40w+的长链接,稳定运行了 3 年的时间,没有出现过故障,SLA 达到 99.95%。 免运维,提供了丰富的控制台功能 如果是自建 ZooKeeper 的话,需要做哪些事:
-
搭建基础设施:把一些基础的设施给准备齐全,例如 ECS/SLB 等,再做网络规划。
-
安装 ZooKeeper:安装过程中,要配置很多参数,并对这些参数足够的熟悉,否则出问题就抓瞎了,不同的参数,对集群运行时的性能也是有一定影响的,这都需要要有足够的专业知识,才能胜任。
-
扩缩容:规划 MyId 的分配,新扩容机器需要自增,否则新机器将无法加入旧集群同步数据,因为只有 MyId 大的才会去主动连小的去同步集群数据;新节点加入集群,也是有严格的启动顺序的,新加入的机器数,必须小于原集群的一半,否则会出现 master 选在新节点上面,导致数据丢失;在加入节点特别多的时候,需要按这个规则重复多次,少一个步骤,都很容易导致集群选主失败,数据丢失,造成线上生产故障。
-
服务端配置变更:zoo.cfg 中的配置项,更新之后,需要把集群中每台机器手动重启,才能触发生效。
-
数据管理:开源的 ZooKeeper 没有图形化管理工具,要查看数据,得通过 zkClient 或者写代码查询,操作非常的复杂和繁琐,这些都是自建带来的问题。
-
线上故障处理:例如 ZooKeeper GC 了,或者网络闪断了,这时候就需要熟悉 ZK/JVM/操作系统的专业运维人员处理了。
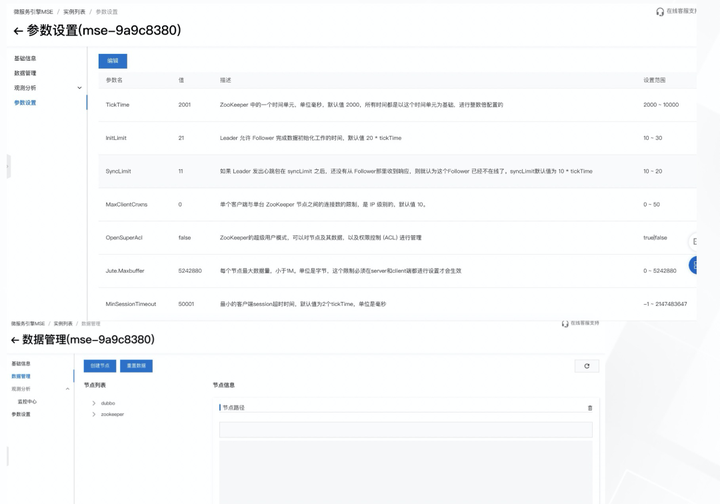
而 MSE 提供的 ZooKeeper 企业服务,则将以上问题通过产品化的方式解决了:

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
需要一个 ZooKeeper 集群的时候,一键购买,3 分钟开箱即用,出现容量问题时,一键平滑扩缩容,还提供了重置数据、参数白屏化设置等功能,在可观测这块,也提供了常用的核心默认指标大盘,与之相配套的就是报警了。使用 ZooKeeper 企业服务,省心、省力,提高企业 IT ROI。 可观测性增强 ZooKeeper 专业版的第三个优势,可观测性的增强:
-
丰富的监控大盘:这次专业版和普罗米修斯进行了深度集成,并且给大家免费开启使用,提供了 20 多个 Zookeeper 常用的监控指标,4 个核心资源监控指标
-
支持核心告警规则:基本能满足大家日常的运维需求了,当然,如果你还需要的话,可以随时找我们,给你安排上
-
开放丰富 Metrics 标准指标:这次专业版把 ZooKeeper 内置的 70 多个 Metrics 指标,都通过 API 的形式开放出去了,对应你们来讲,就能够利用这些数据,自己去绘制监控大盘了,非常的方便

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
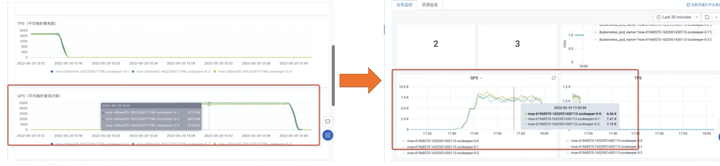
性能提升 写入性能优化提升 20%,数据可靠性达 99.9999999%(即 9 个 9)。 ZooKeeper 的写入性能, 和磁盘性能有很大的关系,必须要把数据写入到磁盘的事务日志成功后,才算写成功,为了提升写性能,我们采用了阿里云 ESSD 高性能云盘,最大 IOPS 能够达到 5W,最大吞吐量 350M/S,数据的可靠性 99.9999999%(即 9 个 9),整个写入 TPS 性能能够提升约 20%。 基于 Dragonwell 进行构建,读取性能提升 1 倍 我们集成了阿里高性能 JDK,开启了里面的协程优化能力,并对 ZooKeeper 的读写任务队列做了锁力度的优化,在高并发处理的场景下,读性能相比开源能够提升 1 倍左右的性能。
添加图片注释,不超过 140 字(可选)
GC 时间降低 80%,大幅减少 Full GC 的情况 ZooKeeper 是时延敏感型的应用,GC 的时间和次数,会影响 ZooKeeper 的处理吞吐量,因此我们针对这种情况,做了 JVM 参数的调优,堆的设置根据不同的配置动态设置,同时提前做了资源碎片的回收,避免出现 FullGC,整体优化下来,GC 时间降低 80%,同时尽可能的避免了 FullGC。
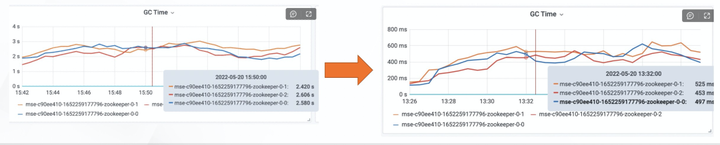
添加图片注释,不超过 140 字(可选)
基于 MSE,构建 Dubbo+Zookeeper 微服务 操作之前,需要购买一个 ZooKeeper,可以选择按量付费,不需要是可以释放,如果长期使用,可以选择包年包月:
添加图片注释,不超过 140 字(可选)
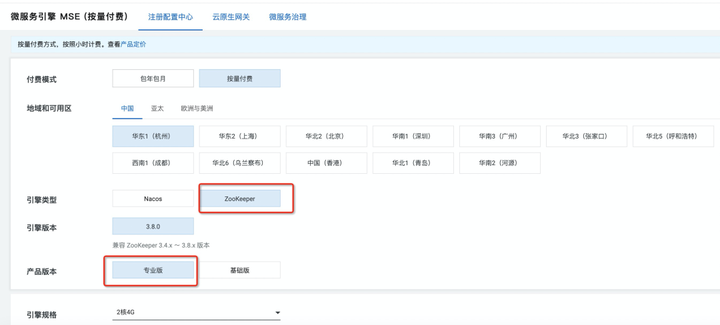
添加图片注释,不超过 140 字(可选)
在选择网络访问方式的时候,以下几种情况: 1、如果你只是使用 VPC 网络使用,你就选择专有网络,选上交换机和专业网络,其他不用动(这里注意:不要去选择公网带宽)
添加图片注释,不超过 140 字(可选)
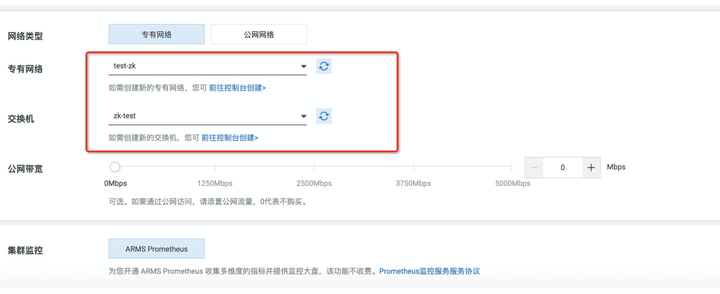
添加图片注释,不超过 140 字(可选)
2、如果你只是要公网访问,选择公网网络,再选上对应的带宽即可;
添加图片注释,不超过 140 字(可选)
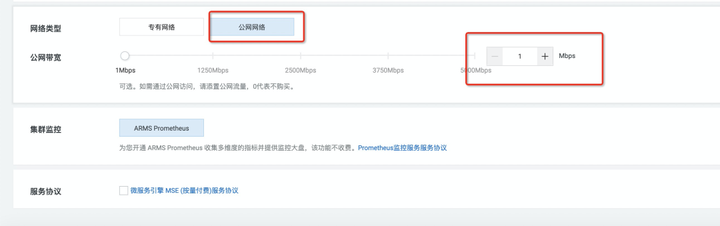
添加图片注释,不超过 140 字(可选)
3、如果需要公网,同时也需要 VPC 网络访问,那么你选择专有网络,同时在公网带宽处,选择你需要的公网带宽,这样就会创建 2 个接入点了;
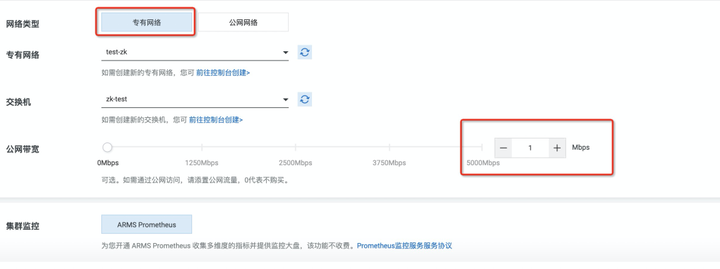
添加图片注释,不超过 140 字(可选)
购买之后,大概 5 分钟左右,ZooKeeper 集群就创建成功了,大家记住访问方式, 等会 Dubbo 配置文件里面需要配置这个地址:
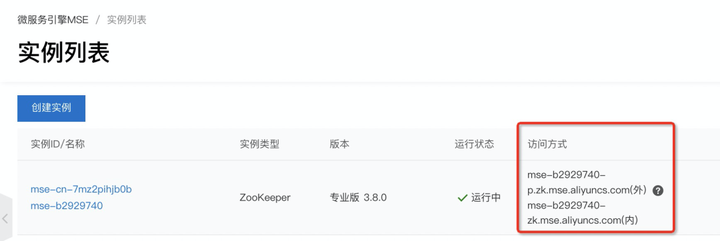
添加图片注释,不超过 140 字(可选)
环境准备好了,就准备 Provider/Consumer 的配置了。欲了解详细的操作步骤,可观看直播视频进行了解:https://yqh.aliyun.com/live/detail/28603 写在最后 MSE 提供的 ZooKeeper 企业服务,旨在为用户提供更可靠的、成本更低、效率更高的,完全兼容开源的分布式协调服务。提供后付费和包年包月两类付费模式,支持杭州,上海,北京,深圳等海内外 23 个 region,满足 95%地域用户。如果你有其他新开服需要,可以联系我们。
本文为阿里云原创内容,未经允许不得转载。




































【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2021-06-09 PyFlink 教程(三):PyFlink DataStream API - state & timer
2021-06-09 StarLake:汇量科技云原生数据湖的探索和实践
2021-06-09 【知识连载】 如何用钉钉宜搭制定企业疫情防控数字化管理方案
2021-06-09 Hologres揭秘:深度解析高效率分布式查询引擎
2021-06-09 Java编程技巧之样板代码
2020-06-09 怀里橘猫柴犬,掌上代码江湖——对话阿里云 MVP郭旭东