


PolarDB-X迎来开源后首个重大版本升级,2.1版本新增5大特色功能
2022 年 5 月25日,阿里云开源
新增功能:
本次开源包含5大核心特性,全面提升
01. 高可用的开源能力补齐
分布式一致性算法(Consensus Algorithm )是一个分布式计算领域的基础性问题,其最基本的功能是为了在多个进程之间对某个(某些) 值达成一致(强一致),进而解决分布式系统的可用性能问(高可用),近几年NewSQL和云原生数据库的不断兴起,极大的推动了关系数据库和一致性协议的结合,常见的技术有Paxos和Raft。
2022年4月1号,PolarDB-X 正式开源X-Paxos,基于原生MySQL存储节点,提供Paxos三副本共识协议,可以做到金融级数据库的高可用和容灾能力,做到RPO=0的生产级别可用性,可以满足同城三机房、两地三中心等容灾架构。
Paxos协议对于面向云的架构是非常必要的,云的本质是虚拟化和资源池化,节点的变化和弹性是一个常规操作,我们需要解决面向用户透明运维的能力,任何情况下数据都不能丢、不能错。
02. 分布式水平扩展能力升级
PolarDB-X 作为一款基于MySQL原生分布式,除了提供基于Paxos RPO=0的金融级容灾能力外,最重要的特性就是分布式的水平扩展,在PolarDB-X 2.1.0版本正式推出新版数据分区表,提供Auto分区模式。
Auto模式的数据库支持自动分区,即创建表时无需指定分区键,数据即可自动在集群内均匀分布;同时也支持使用标准的MySQL分区表语法,对表进行手动分区。结合新版分区表能力,新增支持热点分裂、TTL(Time To Live)分区、Locality亲和性调度等能力,可以让您便捷地享受到分布式数据库的透明式分布、弹性伸缩和分区管理等诸多红利。
具体细节可参考文档:
基于新版分区表,可扩展提供分布式热力分析能力,样例效果图
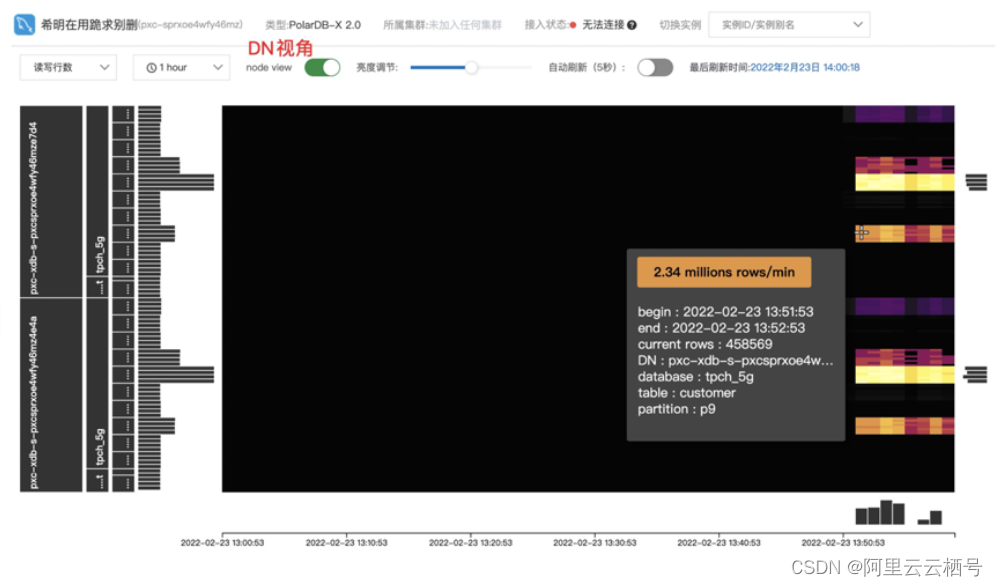 热力分析
热力分析
03. MySQL生态适配加速
PolarDB-X 架构中有一个特殊的CDC(Change Data Capture)组件,其主要用于提供分布式的增量日志获取,作为MySQL原生分布式,对应分布式CDC在设计上也选择全面兼容MySQL Binlog,在PolarDB-X 2.1.0版本我们又进一步完善了与MySQL现有CDC生态的适配和兼容。
首先,PolarDB-X CDC的binlog服务,与canal、maxwell、debezium、Flink CDC等开源MySQL binlog解析组件完成适配认证。其次,PolarDB-X CDC新增replica服务,全面兼容MySQL Replication相关协议,通过MySQL的start slave指令,可以将PolarDB-X作为开源MySQL的备库实时同步数据。

PolarDB-X and Flink CDC
04. 轻量化部署功能完善
PolarDB-X Operator 是一个基于 Kubernetes 的 PolarDB-X 集群管控系统,希望能在原生 Kubernetes 上提供完整的生命周期管理能力,满足用户的轻量化部署。在PolarDB-X 2.1.0版本我们进一步完善了部分运维能力,比如提供Prometheus + Grafana 的监控系统、完善分布式节点升降配、扩缩容、版本升级等能力。
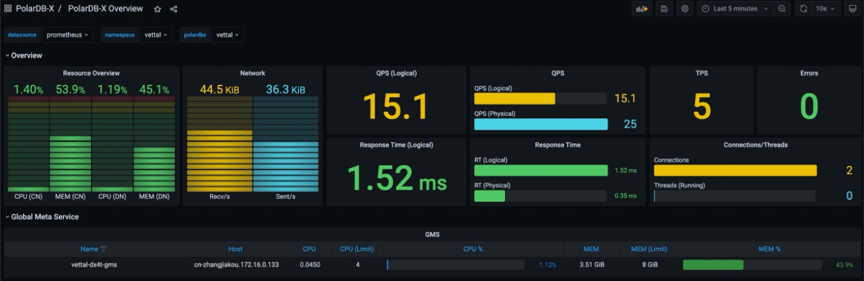
05. OSS冷热数据分离
TTL(time-to-live)
如何将冷数据从InnoDB行存中剥离出来?这是一个令很多开发者头疼的问题。如果使用delete from 语句 + where条件的形式来删除冷数据,很可能会因为扫描行数太多、数据太过分散,而造成锁表,影响整个数据库实例的访问;如果提前按照时间进行分区,再逐个将旧时间分区drop掉,则许多不适合按照时间分区的表将会束手无策。
针对用户反馈的这一实际问题,PolarDB-X 引入了TTL(time-to-live)这一新特性来帮助用户完成冷热数据剥离。用户无需手动维护,而是通过提前指定起始时间、分区大小和过期时间等信息,来完成数据的自动过期。我们在更底部的存储层将每张物理表做进一步的透明分区,数据按照最近的更新时间被集中到一起。
例如对于订单表t_orders,用户按照订单id进行哈希分区。引入了TTL之后,每个分区被进一步透明划分。旧时间分区(图中的2022-01分区)的过期,如同撕掉便利贴一样,在不锁表、不手动分区的情况下完成冷热数据的剥离。
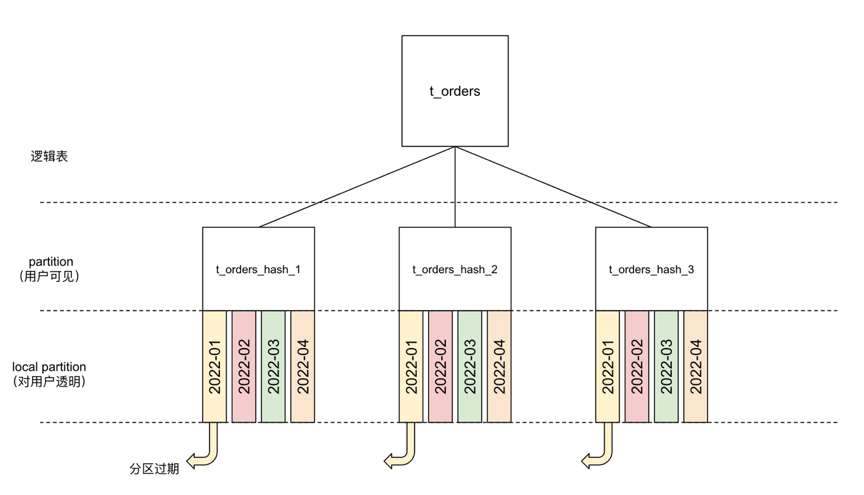
关于TTL的具体使用,可以参考官网文档:什么是
高性能查询
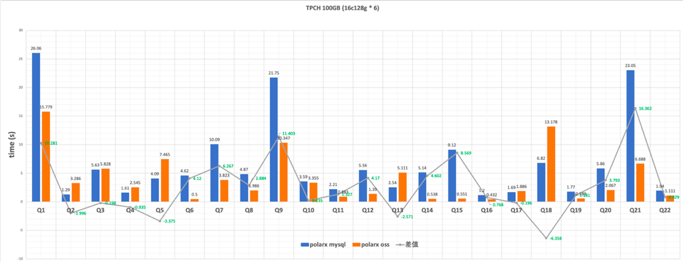
当冷数据从主库中剥离出来,归档至OSS存储服务后,我们就得到了一张以OSS为存储载体的归档表。它完全兼容MySQL数据类型和各种查询方式,在低成本、高可用的前提下,能带来与主表一致的使用体验。 为了满足不同用户对历史数据的查询需要,我们在设计上兼顾了点查和复杂分析型查询。对此我们进行了相应的测评。由于PolarDB-X on OSS 使用列存,在报表查询中有天然的优势,因此相比于PolarDB-X on MySQL 行存模式,TPC-H测试成绩有了大幅提升;1亿行数据量下的Sysbench点查测试也显示,归档表可以满足历史数据的查询要求。 在实现以上功能的过程中,最为关键的设计是文件系统、多级缓存、多级索引与查询裁剪。此外还包括列存索引选择、向量化计算、AGG加速等,我们都将在后续的文章中详细介绍。
TPC-H性能测试
规格:
●CPU:6 * 16C
●内存:6 * 128GB
●SF = 100 (TPC-H 100GB)
总耗时约89s (PolarDB-X on MySQL 总耗时 150s)
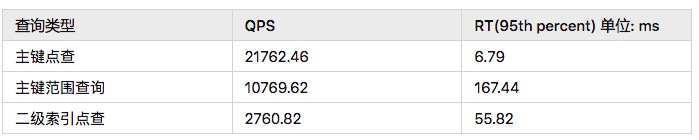
Sysbench 性能测试
规格:
●压测ECS:1 * 8C32G
●CN:6 * 16C128G
●Sysbench表行数: 1亿
●并发数:100
sysbench性能测试数据如下:
一键迁移
完成了冷热数据剥离后,如何将数据快速归档到OSS上呢?我们基于MySQL标准语法,提供了非常简易便捷的方式,只需要执行一条建表语句:
CREATE TABLE [oss_table_name] LIKE [innodb_table_name]
ENGINE = 'OSS' ARCHIVE_MODE = 'TTL'执行后,OSS表将克隆InnoDB表的表结构,免去用户对归档表结构的设计;同时,冷数据归档表和源表被绑定起来,源表过期的数据将自动导入到归档表中。此后,用户可以像访问普通表一样,通过SQL来完成包括点查、范围查询、复杂分析型查询在内的各种数据访问。
手动强制过期
如果您想要更灵活的过期和归档操作,下列语句可以让您手动过期数据,并将过期数据导入至OSS中:
ALTER TABLE [innodb_table_name] EXPIRE LOCAL PARTITION [local_partition_name]还有更多特性
更详细的Features
新增 支持创建数据库指定建表模式(新的分区表模式与老的分库分表模式),默认是分库分表模式
新增 支持使用 MySQL分区表语法 创建一级分区的分区表,分区策略包括Hash/Range/List等
新增 支持分区表的动态裁剪能力,包括支持分区列条件的常量折叠、区间合并以及前缀查询裁剪等功能
新增 支持分区表的JOIN计算下推
新增 提供分区表的分区管理能力,包括分区的添加、删除、分裂、合并与迁移等功能
新增 提供表组及其他能力(包括表组的创建、删除、变更等),支持分区变更期间JOIN计算下推不受影响
新增 支持全局索引表使用MySQL分区表语法并按Hash/Range/List等分区策略进行分区
新增 自动拆分支持使用分区表语法
新增 拆分变更增加支持分区表
新增 新分区表GSI自动拆分会携带主键,可以处理GSI热点问题
新增 支持实例的缩容
新增 支持分区表的TTL及其管理能力(包括调整TTL的初始时间与时间间隔等)
优化 Check Table 指令,支持校验主表分区、索引表分区与列定义等元数据一致性
新增 SQL Advisor支持推荐广播表
新增 支持Instant Add Column功能
新增 支持Explain Statistics拉取优化器优化需要的所有信息
新增 限制cbo的搜索空间,减少复杂查询的优化耗时
优化 部分DDL后台操作的数据校验任务的性能,使GSI/扩缩容DDL变更操作加速
新增 支持兼容MySQL的Replica相关指令
新增 支持存储节点PAXOS三节点集群
新增Replica组件,支持通过change master … 语法的方式将PolarDB-X作为MySQL Slave来消费数据
全局Binlog中支持记录Rows_query_event类型数据,前置条件:需将DN节点binlog_rows_query_log_events参数设置为On
新增 Flink CDC 接入
新增 CR PolarDBXMonitor 用来监控 PolarDBXCluster
新增 Helm Chart polardbx-monitor,包含定制化的 kube-prometheus 和预定义的 Dashboard 用来展示 PolarDB-X 集群监控信息
PXD 工具支持单副本和三副本两种部署模式
PolarDB-X 源码开放地址
计算层:
PolarDB 开源社区介绍
PolarDB 开源社区是阿里云数据库开源产品PolarDB的技术交流平台。作为一款开源的数据库产品,离不开用户和开发者的支持, 大家可以在社区针对PolarDB产品提问题、功能需求、交流使用心得、分享最佳实践、提交issue、贡献代码等。
为了让社区成员可以更方便的交流, 促进数据库行业的发展, 社区会组织线上和线下的meetup, 举办高校、企业的交流活动, 组织技术类的竞技活动等。欢迎广大的数据库爱好者、用户、开发者加入社区大家庭。
本文为阿里云原创内容,未经允许不得转载。

