

数据湖揭秘—Delta Lake
DeltaLake简介
Delta Lake 是 DataBricks 公司开源的、用于构建湖仓架构的存储框架。能够支持 Spark,Flink,Hive,PrestoDB,Trino 等查询/计算引擎。作为一个开放格式的存储层,它在提供了批流一体的同时,为湖仓架构提供可靠的,安全的,高性能的保证。
Delta Lake 关键特性:
- ACID事务:通过不同等级的隔离策略,Delta Lake 支持多个 pipeline 的并发读写;
- 数据版本管理:Delta Lake 通过 Snapshot 等来管理、审计数据及元数据的版本,并进而支持 time-travel 的方式查询历史版本数据或回溯到历史版本;
- 开源文件格式:Delta Lake 通过 parquet 格式来存储数据,以此来实现高性能的压缩等特性;
- 批流一体:Delta Lake 支持数据的批量和流式读写;
- 元数据演化:Delta Lake 允许用户合并 schema 或重写 schema,以适应不同时期数据结构的变更;
- 丰富的DML:Delta Lake 支持 Upsert,Delete 及 Merge 来适应不同场景下用户的使用需求,比如 CDC 场景;
文件结构
湖表较于普通 Hive 表一个很大的不同点在于:湖表的元数据是自管理的,存储于文件系统。下图为 Delta Lake 表的文件结构。
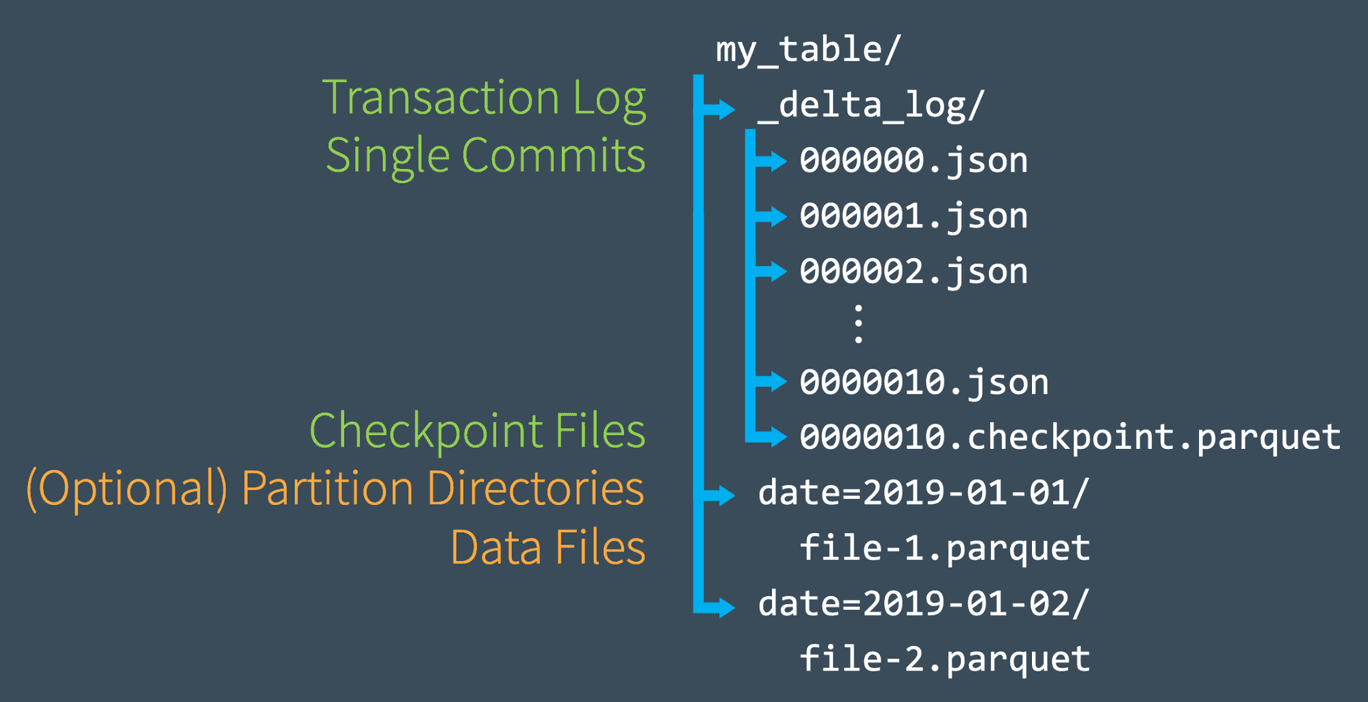
Delta Lake 的文件结构主要有两部分组成:
- _delta_log目录:存储 deltalake 表的所有元数据信息,其中:
- 每次对表的操作称一次 commit,包括数据操作(Insert/Update/Delete/Merge)和元数据操作(添加新列/修改表配置),每次 commit 都会生成一个新的 json 格式的 log 文件,记录本次 commit 对表产生的行为(action),如新增文件,删除文件,更新后的元数据信息等;
- 默认情况下,每10次 commit 会自动合并成一个 parquet 格式的 checkpoint 文件,用于加速元数据的解析,及支持定期清理历史的元数据文件;
- 数据目录/文件:除 _delta_log 目录之外的即为实际存储表数据的文件;需要注意:
- DeltaLake 对分区表的数据组织形式同普通的 Hive 表,分区字段及其对应值作为实际数据路径的一部分;
- 并非所有可见的数据文件均为有效的;DeltaLake 是以 snapshot 的形式组织表,最新 snopshot 所对应的有效数据文件在 _delta_log 元数据中管理;
元数据机制
Delta Lake 通过 snapshot 来管理表的多个版本,并且支持对历史版本的 Time-Travel 查询。不管是查询当前最新的 snapshot 还是历史某版本的 snapshot 信息,都需要先解析得到对应 snapshot 的元数据信息,主要涉及到:
- 当前 DeltaLake 的读写版本协议(Protocol);
- 表的字段信息和配置信息(Metadata);
- 有效的数据文件列表;这一点通过一组新增文件(AddFile)和删除文件(RemoveFile)来描述;
那在加载具体 snopshot 时,为了加速加载流程,先尝试找到小于或等于该版本的 checkpoint 文件,然后结合其后直到当前版本的 log 文件,共同解析得到元数据信息。
EMR DeltaLake
阿里云EMR团队从19年就开始跟进 DeltaLake 社区,并将其落地在 EMR 的商业产品中的。期间,在迭代功能,优化性能,融合生态,降低易用性,场景落地等方面,不断打磨升级 DeltaLake,使之更好的融入 EMR 产品,方便客户使用。
以下表格汇总了 EMR DeltaLake 较开源 DeltaLake(社区1.1.0)对比的主要自研特性。

![]()
特别说明:
DeltaLake1.x 版本仅支持 Spark3,且绑定具体 Spark 版本,导致部分新功能/优化不能在老的版本及 Spark2 上使用,而 EMR DeltaLake 保持 Spark2 的 DeltaLake(0.6)和 Spark3 的 DeltaLake(1.x)的功能特性同步;
与 DLF 的深度集成
DLF(Data Lake Formation)是一款全托管的快速帮助用户构建云上数据湖及 LakeHouse 的服务,为客户提供了统一的元数据管理、统一的权限与安全、便捷的数据入湖能力以及一键式数据探索能力,无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
EMR DeltaLake 与 DLF 深度集成,使 DeltaLake 表创建写入后自动完成元数据同步到 DLF 的 metastore,避免了像开源版本那样,需要用户再自行建立 Hive 外表关联 DeltaLake 表的操作。同步后,用户可以直接通过 Hive、Presto、Impala,甚至阿里云MaxCompute 及 Hologres 查询,无需任何其他额外操作。
同样 DLF 具备成熟的入湖能力,用户可以通过产品端的配置将 Mysql、RDS、Kafka 的数据直接同步生成 DeltaLake 表。
在 DLF 的产品侧,湖格式 DeltaLake 作为第一公民,DLF 也将在接下来的迭代中针对性的提供易用的可视化展示,和湖表管理的能力,帮助用户更好的维护湖表。
G-SCD 解决方案
Slowly Changing Dimension(SCD)即缓慢变化维,被认为是跟踪维度变化的关键ETL任务之一。在数仓场景下,通常使用星型模型来关联事实表和维度表。如果维度表中的某些维度随时间更新,那么如何存储和管理当前和历史的维度值呢?是直接忽略,还是直接覆盖,亦或者其他的处理方式,如永久保存历史所有的维度值。根据不同的处理方式,SCD 定义了多种类型,其中 SCD Type2 通过增加新记录的方式保留所有的历史值。
在实际的生产环境中,我们可能不需要关注所有的历史维度值,而关注在固定的时间段内最新的值,比如以天或者小时为粒度,关注在每一天或者小时内某个维度的值。因此实际的场景可以转化为基于固定粒度(或业务快照)的缓慢变化维(Based-Granularity Slowly Changing Dimension,G-SCD)。
在传统数仓基于 Hive 表的实现,有几种方式可选,以下列举两个解决方案:
- 流式构建T+1时刻的增量数据表,和离线表的T时刻分区数据做合并,生成离线表T+1分区。其中T表示粒度或业务快照。不难想象该方案每个分区保存了全量的数据,会造成大量的存储资源浪费;
- 保存离线的基础表,每个业务时刻的增量数据独立保存,在查询数据时合并基础表和增量表。该方案会降低查询效率。
通过对 DeltaLake 自身的升级,结合对 SparkSQL,Spark Streaming 的适配,我们实现了 SCD Type2 场景。架构如下:
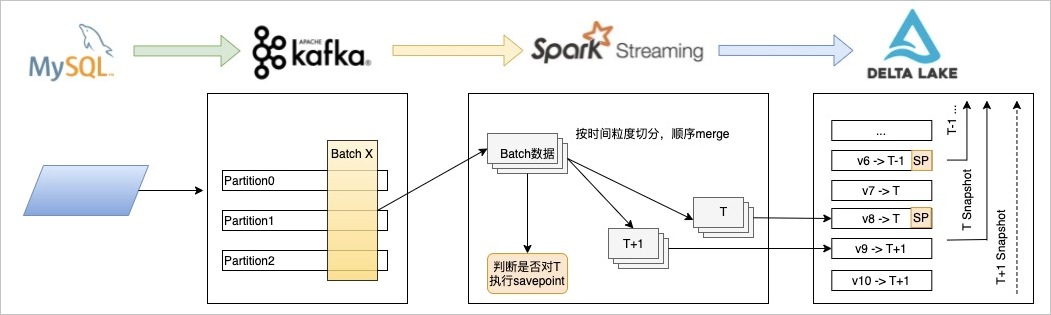
同样对接上游的 Kafka 的数据,在 Streaming 端按照配置的业务快照粒度将 Batch数据进行切分,分别 commit,并附带业务快照的值。DeltaLake 在接收到数据后,保存当前 snapshot 和业务快照的关系。并在下一个业务快照到达时,对前一个 snapshot 做 savepoint,永久保留该版本。用户查询时,通过指定的业务快照的具体值,识别到具体的 snapshot,然后通过 time-travel 的方式实现查询。
G-SCD on DeltaLake 方案优势:
- 流批一体:不需要增量表和基础表两张表;
- 存储资源:借助 Delta Lake 本身的 data versioning 能力,实现增量变化维度的管理,不需要按时间粒度保留历史全量数据;
- 查询性能:借助 Delta Lake 的元数据 checkpoint,数据的 Optimize、Zorder 及 DataSkipping 的能力,提升查询效率;
- 保留原实现的 SQL 语句:用户依然可以像用分区实现快照的方式一样,使用类似的分区字段执行要查询的业务时间粒度内的快照数据。
CDC 解决方案
在当前的数仓架构下,我们往往将数据分层为 ODS,DWD,DWS,ADS 等方便管理。原始数据如存储在 Mysql 或者 RDS,我们可以消费其 binlog 数据实现对 ODS 表的增量更新。但,从 ODS 到 DWD,从 DWD 到 DWS 层数据呢?由于 Hive 表本身不具备生成类似 binlog 数据的能力,因此我们无法实现下游各链路的增量更新。而让湖表具备生成类似 binlog 数据的能力,又是构建实时增量数仓的关键。
阿里云EMR 基于 DeltaLake 实现了将其作为 Streaming Source 的 CDC 能力。开启后,对所有的数据操作将同时生成 ChangeData 并持久化,以便下游 Streaming 读取;同时支持 SparkSQL 语法查询。如下图所示:
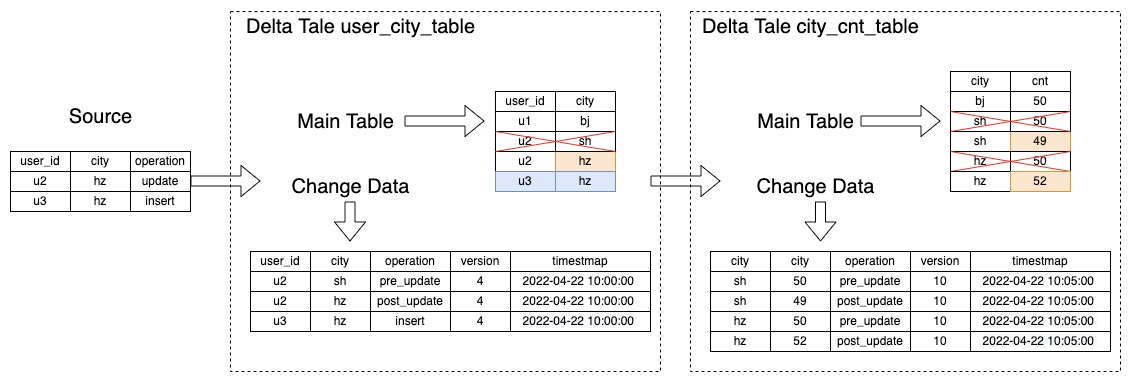
ODS 层 Delta 表 user_city_table 接收 Source 数据执行 Merge 操作,同时将变更的数据持久化保存;DWS 层按 city 聚合的 city_cnt_table 表读取 user_city_table表的 ChangeData 数据,对 cnt 聚合字段实现更新。
后续规划
DeltaLake 作为 EMR 主推的湖格式,得到了很多客户的信任和选择,并落地到各自的实际生产环境,对接了多种场景。后续会继续加强在 DeltaLake 的投入,深度发掘和 DLF 的集成,丰富湖表运维管理能力,降低用户入湖成本;持续优化读写性能,完善与阿里云大数据体系的生态建设,推进客户湖仓一体架构的建设。
本文为阿里云原创内容,未经允许不得转载。
