
系统性能分析从入门到进阶
作者 | 勿非
本文以系统为中心, 结合日常工作和用例, 由浅入深地介绍了性能分析的一些方法和体会, 希望对想了解系统性能分析的同学有所帮助。
入门篇
资源角度
USE
产品跑在系统的各种资源上面, 从系统资源的角度入门性能分析是个不错的选择, 我们以业界知名大牛 Brendan Gregg 的 USE 方法开始, USE 特点就是简单有效适合入门, 用 Brendan 的话描述 USE 的效果:
I find it solves about 80% of server issues with 5% of the effort.
USE 从系统资源的角度, 包括但不限于 CPU, 内存, 磁盘, 网络等, 关注以下3个方面:
- Utilization (U): as a percent over a time interval. eg, "one disk is running at 90% utilization". 大多数情况可以合理推测利用率高可能会影响性能
- Saturation (S): as a queue length. eg, "the CPUs have an average run queue length of four". 资源竞争的激烈程度
- Errors (E). scalar counts. eg, "this network interface has had fifty late collisions". Errors 相对直观
CPU
对于 CPU, 主要关注以下指标:
- Utilization. CPU 的利用率
- Saturation. 可以是 load average, runqueue length, sched latency 等
CPU 利用率用 top 看下:
top - 17:13:49 up 83 days, 23:10, 1 user, load average: 433.52, 422.54, 438.70 Tasks: 2765 total, 23 running, 1621 sleeping, 0 stopped, 34 zombie %Cpu(s): 23.4 us, 9.5 sy, 0.0 ni, 65.5 id, 0.7 wa, 0.0 hi, 1.0 si, 0.0 st
CPU 利用率拆分成了更细粒度的几部分:
- us, sys, ni - 对应 un-niced user, kernel, niced user 的 CPU 利用率
- id, wa - 对应到 idle, io wait 的比例, io wait 本质上也是一种 idle, 区别在于对应 cpu 上有等待 io 的任务
- hi, si - 对应 hardirq, softirq 的比例
- st - 因为超卖等原因, hypervisor 从该 vm 偷走的时间 (todo: docker)
继续看 load average, 3 个数值分别对应到系统 1/5/15 分钟内的系统平均 load, load 是个比较模糊的概念, 可以简单认为是对资源有需求的任务数, 包括 on cpu, runnable 的任务, 也包括等待 IO 及任意 D 状态的任务. load 使用采样的方式, 每隔 5 秒采样一样, 越近的采样权重越大, 这样从 1/5/15 的趋势可以看出系统压力的变化。
load average: 433.52, 422.54, 438.70
在这台 128 个 CPU 的机器上, loadavg 看起来有些偏高, 但是具体影响目前不得而知, 性能低是相对具体目标而言的, load 高只是现象, 它可能相关也可能无关, 但至少是值得注意的。
再看下 dstat 关于任务状态的统计:
- run - 对应到/proc/stat 里面的 procs_running, 也就是 runnable 任务数
- blk - 对应到/proc/stat 里面的 procs_blocked, 阻塞在 I/O 的任务数
实际上和 loadavg 没有本质区别, 只是 load 模糊了 runnable 和 D 状态, 同时 load 使用 1/5/15 分钟的力度, 而 dstat 可以使用更细粒度, 如果只看某一时间点用 load, 如果要观察长时间的变化使用 dstat (/proc/stat)。
#dstat -tp
----system---- ---procs---
time |run blk new
07-03 17:56:50|204 1.0 202
07-03 17:56:51|212 0 238
07-03 17:56:52|346 1.0 266
07-03 17:56:53|279 5.0 262
07-03 17:56:54|435 7.0 177
07-03 17:56:55|442 3.0 251
07-03 17:56:56|792 8.0 419
07-03 17:56:57|504 16 152
07-03 17:56:58|547 3.0 156
07-03 17:56:59|606 2.0 212
07-03 17:57:00|770 0 186
内存
这里主要关注内存容量方面, 不关注访存的性能。
- Utilization. 内存利用率
- Saturation. 这里主要考察内存回收算法的效率
简单的内存利用率用 free 命令:
- total - MemTotal + SwapTotal, 一般来说 MemTotal 会略小于真实的物理内存
- free - 未使用的内存. Linux 倾向于缓存更多页面以提高性能, 所以不能简通过 free 来判断内存是否不足
- buff/cache - 系统缓存, 一般不需要严格区分 buffer 和 cache
- available - 估计的可用物理内存大小
- used - 等于 total - free - buffers - cache
- Swap - 该机器上未配置
#free -g
total used free shared buff/cache available
Mem: 503 193 7 2 301 301
Swap: 0 0 0
更详细的信息可以直接去读/proc/meminfo:
#cat /proc/meminfo MemTotal: 527624224 kB MemFree: 8177852 kB MemAvailable: 316023388 kB Buffers: 23920716 kB Cached: 275403332 kB SwapCached: 0 kB Active: 59079772 kB Inactive: 431064908 kB Active(anon): 1593580 kB Inactive(anon): 191649352 kB Active(file): 57486192 kB Inactive(file): 239415556 kB Unevictable: 249700 kB Mlocked: 249700 kB SwapTotal: 0 kB SwapFree: 0 kB [...]
再来看下内存回收相关的信息, sar 的数据主要从/proc/vmstat 采集, 主要关注:
- pgscank/pgscand - 分别对应 kswapd/direct 内存回收时扫描的 page 数
- pgsteal - 回收的 page 数
- %vmeff - pgsteal/(pgscank+pgscand)
要理解这些数据的具体含义, 需要对内存管理算法有一定了解, 比如这里的 pgscan/pgsteal 只是针对inactive list而言的, 在内存回收的时候可能还需要先把页面从 active list 搬到 inactive list 等. 如果这里有异常, 我们可以先把这当成入口, 再慢慢深入, 具体到这里的%vmeff, 最好情况就是每个扫描的 page 都能回收, 也就是 vmeff 越高越好。
#sar -B 1
11:00:16 AM pgscank/s pgscand/s pgsteal/s %vmeff
11:00:17 AM 0.00 0.00 3591.00 0.00
11:00:18 AM 0.00 0.00 10313.00 0.00
11:00:19 AM 0.00 0.00 8452.00 0.00
I/O
存储 I/O 的 USE 模型:
- Utilization. 存储设备的利用率, 单位时间内设备在处理 I/O 请求的时间
- Saturation. 队列长度
我们一般关注这些部分:
- %util - 利用率. 注意即使达到 100%的 util, 也不代表设备没有性能余量了, 特别地现在的 SSD 盘内部都支持并发. 打个比方, 一家旅馆有 10 间房, 每天只要有 1 个房间入住, util 就是 100%。
- svctm - 新版 iostat 已经删掉
- await/r_await/w_await - I/O 延迟, 包括排队时间
- avgrq-sz - 平均 request size, 请求处理时间和大小有一定关系, 不一定线性
- argqu-sz - 评估 queue size, 可以用来判断是否有积压
- rMB/s, wMB/s, r/s, w/s - 基本语义
资源粒度
当我们判断资源是否是瓶颈的时候, 只看系统级别的资源是不够的, 比如可以用 htop 看下每个 CPU 的利用率, 目标任务运行在不同 CPU 上的性能可能相差很大。
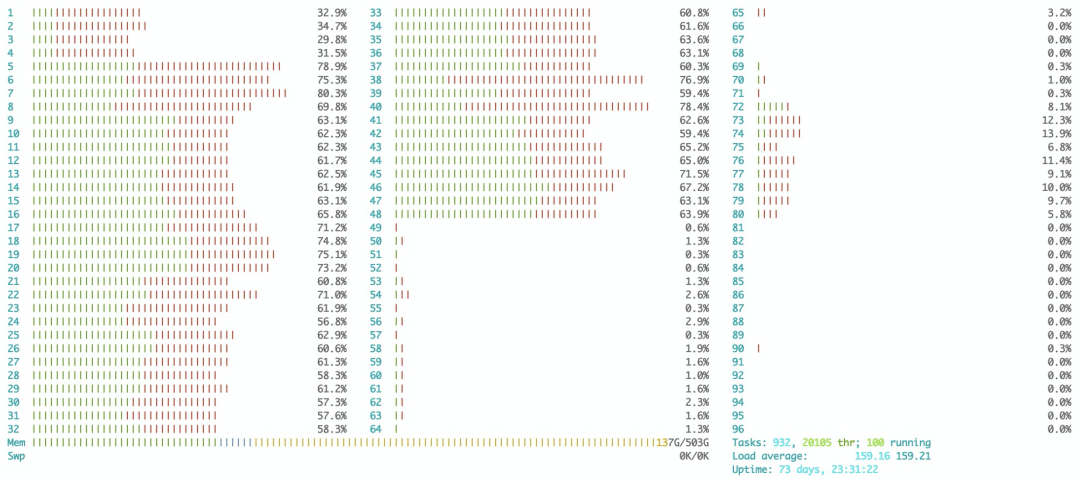
内存也有类似情况, 运行 numastat -m
Node 0 Node 1 Node 2 Node 3
--------------- --------------- --------------- ---------------
MemTotal 31511.92 32255.18 32255.18 32255.18
MemFree 2738.79 131.89 806.50 10352.02
MemUsed 28773.12 32123.29 31448.69 21903.16
Active 7580.58 419.80 9597.45 5780.64
Inactive 17081.27 26844.28 19806.99 13504.79
Active(anon) 6.63 0.93 2.08 5.64
Inactive(anon) 12635.75 25560.53 12754.29 9053.80
Active(file) 7573.95 418.87 9595.37 5775.00
Inactive(file) 4445.52 1283.75 7052.70 4450.98
系统不一定就是物理机, 如果产品跑在 cgroup, 那么这个 cgroup 是更需要关注的系统, 比如在空闲系统上执行如下命令:
#mkdir /sys/fs/cgroup/cpuset/overloaded
#echo 0-1 > /sys/fs/cgroup/cpuset/cpuset.cpus
#echo 0 > /sys/fs/cgroup/cpuset/cpuset.mems
#echo $$
#for i in {0..1023}; do /tmp/busy & done
此时从物理机级别看, 系统的 load 很高, 但是因为 cpuset 的限制, 竞争约束在 cpu 0 和 1 上, 对运行在其他 cpu 上的产品影响并不大。
#uptime 14:10:54 up 6 days, 18:52, 10 users, load average: 920.92, 411.61, 166.95
应用角度
系统资源和应用的性能可能会有某种关联, 但是也可以更直接地从应用的角度出发定位问题:
- 应用能使用多少资源, 而不是系统提供了多少资源, 这里面可能会有gap, 系统是个模糊的概念, 而应用本身却相对具体. 以上面cpuset为例, 物理机是个系统, cpuset管理的资源也可以成为系统, 但是应用在cpuset里面还是外面是确定的。
- 应用对资源的需求, 即使系统资源再多, 应用用不上性能也上不去, 也就是系统可能没问题, 而是应用本身的原因。
以下面的myserv为例, 它的4个线程%cpu都达到了100, 这个时候再去分析整个系统的load什么用处不大, 系统有再多的空闲cpu对myserv来说已经没有意义。
#pidstat -p `pgrep myserv` -t 1 15:47:05 UID TGID TID %usr %system %guest %CPU CPU Command 15:47:06 0 71942 - 415.00 0.00 0.00 415.00 22 myserv 15:47:06 0 - 71942 0.00 0.00 0.00 0.00 22 |__myserv ... 15:47:06 0 - 72079 7.00 94.00 0.00 101.00 21 |__myserv 15:47:06 0 - 72080 10.00 90.00 0.00 100.00 19 |__myserv 15:47:06 0 - 72081 9.00 91.00 0.00 100.00 35 |__myserv 15:47:06 0 - 72082 5.00 95.00 0.00 100.00 29 |__myserv
常用命令
基本命令
基本命令一般用来读取内核中记录的各种统计信息, 特别是/proc下面的各种文件, 这里简单列举部分:
- top - 提供了交互模式和batch模式, 不带参数进入交互模式, 按下h键可以看到各种功能
- ps - 提供了各种参数查看系统中任务的状态, 比如ps aux或者ps -eLf, 很多参数可以在需要的时候查看手册
- free - 内存信息
- iostat - I/O性能
- pidstat - 查看进程相关的信息, 上面已经介绍过
- mpstat - 可以查看单独cpu的利用率, softirq, hardirq个数等
- vmstat - 可以查看虚拟内存及各种系统信息
- netstat - 网络相关
- dstat - 可以查看cpu/disk/mem/net等各种信息, 这些stat命令哪个方便用哪个
- htop - 上面介绍过
- irqstat - 方便观察中断信息
- sar/tsar/ssar - 收集和查看系统运行的各种历史信息, 也提供实时模式
这里举个ps的例子, 我们监控mysqld服务, 当该进程使用的内存超过系统内存70%的时候, 通过gdb调用jemalloc的malloc_stats_print函数来分析可能的内存泄漏。
largest=70
while :; do
mem=$(ps -p `pidof mysqld` -o %mem | tail -1)
imem=$(printf %.0f $mem)
if [ $imem -gt $largest ]; then
echo 'p malloc_stats_print(0,0,0)' | gdb --quiet -nx -p `pidof mysqld`
fi
sleep 10
done
perf
perf是性能分析的必备工具, 它最核心的能力是能访问硬件上的Performance Monitor Unit (PMU), 对分析CPU bound的问题很有帮助, 当然perf也支持各种软件event. perf的主要能力包括:
- 通过采样发现程序热点
- 通过硬件PMU深入分析问题的根源, 特别是配合硬件上的优化
perf list可以列出支持的event, 我们可以通过perf来获取cache misses, cycles等等。
#perf list | grep Hardware branch-misses [Hardware event] bus-cycles [Hardware event] cache-misses [Hardware event] cache-references [Hardware event] cpu-cycles OR cycles [Hardware event] instructions [Hardware event] L1-dcache-load-misses [Hardware cache event] L1-dcache-loads [Hardware cache event] L1-dcache-store-misses [Hardware cache event] L1-dcache-stores [Hardware cache event] L1-icache-load-misses [Hardware cache event] L1-icache-loads [Hardware cache event] branch-load-misses [Hardware cache event] branch-loads [Hardware cache event] dTLB-load-misses [Hardware cache event] iTLB-load-misses [Hardware cache event] mem:<addr>[/len][:access] [Hardware breakpoint]
perf使用的时候一般会传入以下参数:
- 通过-e指定感兴趣的一个或多个event
- 指定采样的范围, 比如进程级别 (-p), 线程级别 (-t), cpu级别 (-C), 系统级别 (-a)
这里使用默认的event看下进程31925的执行情况. 一个比较重要的信息是insns per cycle (IPC), 也就是每个cycle能执行多少指令, 其他pmu event像cache misses, branch misses如果有问题最终都会反映到IPC上. 虽然没有一个明确的标准, 但是下面0.09的IPC是比较低的, 有必要继续深入。
#perf stat -p 31925 sleep 1
Performance counter stats for process id '31925':
2184.986720 task-clock (msec) # 2.180 CPUs utilized
3,210 context-switches # 0.001 M/sec
345 cpu-migrations # 0.158 K/sec
0 page-faults # 0.000 K/sec
4,311,798,055 cycles # 1.973 GHz
<not supported> stalled-cycles-frontend
<not supported> stalled-cycles-backend
409,465,681 instructions # 0.09 insns per cycle
<not supported> branches
8,680,257 branch-misses # 0.00% of all branches
1.002506001 seconds time elapsed
除了stat外, perf另一个可能更常用的方式是采样来确定程序的热点, 现在有如下程序:
void busy(long us) {
struct timeval tv1, tv2;
long delta = 0;
gettimeofday(&tv1, NULL);
do {
gettimeofday(&tv2, NULL);
delta = (tv2.tv_sec - tv1.tv_sec) * 1000000 + tv2.tv_usec - tv1.tv_usec;
} while (delta < us);
}
void A() { busy(2000); }
void B() { busy(8000); }
int main() {
while (1) {
A(); B();
}
return 0;
}
函数A和B执行时间的比例, perf的采样结果和我们期望的2:8基本一致。
#perf record -g -e cycles ./a.out
#perf report
Samples: 27K of event 'cycles', Event count (approx.): 14381317911
Children Self Command Shared Object Symbol
+ 99.99% 0.00% a.out [unknown] [.] 0x0000fffffb925137
+ 99.99% 0.00% a.out a.out [.] _start
+ 99.99% 0.00% a.out libc-2.17.so [.] __libc_start_main
+ 99.99% 0.00% a.out a.out [.] main
+ 99.06% 25.95% a.out a.out [.] busy
+ 79.98% 0.00% a.out a.out [.] B
- 71.31% 71.31% a.out [vdso] [.] __kernel_gettimeofday
__kernel_gettimeofday
- busy
+ 79.84% B
+ 20.16% A
+ 20.01% 0.00% a.out a.out [.] A
strace
trace相对于采样最大的优势在于精度, trace能抓住每次操作, 这给调试和理解带来很大方便. strace专门用来trace系统调用。
strace通过捕获所有的系统调用能快速帮助理解应用的某些行为, 这里使用strace来看下上面提到的perf-record的实现, 很容易发现系统调用perf_event_open以及它的参数, 因为有128个cpu, 针对每个cpu都会调用一次该系统调用。
#strace -v perf record -g -e cycles ./a.out
perf_event_open({type=PERF_TYPE_HARDWARE, size=PERF_ATTR_SIZE_VER5, config=PERF_COUNT_HW_CPU_CYCLES, sample_freq=4000, sample_type=PERF_SAMPLE_IP|PERF_SAMPLE_TID|PERF_SAMPLE_TIME|PERF_SAMPLE_CALLCHAIN|PERF_SAMPLE_PERIOD, read_format=0, disabled=1, inherit=1, pinned=0, exclusive=0, exclusive_user=0, exclude_kernel=0, exclude_hv=0, exclude_idle=0, mmap=1, comm=1, freq=1, inherit_stat=0, enable_on_exec=1, task=1, watermark=0, precise_ip=0 /* arbitrary skid */, mmap_data=0, sample_id_all=1, exclude_host=0, exclude_guest=1, exclude_callchain_kernel=0, exclude_callchain_user=0, mmap2=1, comm_exec=1, use_clockid=0, context_switch=0, write_backward=0, namespaces=0, wakeup_events=0, config1=0, config2=0, sample_regs_user=0, sample_regs_intr=0, aux_watermark=0, sample_max_stack=0}, 51876, 25, -1, PERF_FLAG_FD_CLOEXEC) = 30
blktrace
iostat因为粒度太粗有的时候并不能很好地定位问题, blktrace通过跟踪每个I/O, 并在I/O的关键路径打桩, 可以获得更精确的信息, 从而帮忙分析问题. blktrace封装了几个命令:
- blktrace: 收集
- blkparse: 处理
- btt: 强大的分析工具
- btrace: blktrace/blkparse的一个简单封装, 相当于blktrace -d /dev/sda -o - | blkparse -i -
简单看下blktrace的输出, 里面记录了I/O路径上的关键信息, 特别地:
- 时间戳, 性能分析的关键信息之一
- event, 第6列, 对应到I/O路径上的关键点, 具体对应关系可以查找相应手册或源码, 理解这些关键点是调试I/O性能的必要技能
- I/O sector. I/O请求对应的扇区和大小
$ sudo btrace /dev/sda 8,0 0 1 0.000000000 1024 A WS 302266328 + 8 <- (8,5) 79435736 8,0 0 2 0.000001654 1024 Q WS 302266328 + 8 [jbd2/sda5-8] 8,0 0 3 0.000010042 1024 G WS 302266328 + 8 [jbd2/sda5-8] 8,0 0 4 0.000011605 1024 P N [jbd2/sda5-8] 8,0 0 5 0.000014993 1024 I WS 302266328 + 8 [jbd2/sda5-8] 8,0 0 0 0.000018026 0 m N cfq1024SN / insert_request 8,0 0 0 0.000019598 0 m N cfq1024SN / add_to_rr 8,0 0 6 0.000022546 1024 U N [jbd2/sda5-8] 1
这是btt的一个输出, 可以看到S2G的个数和延迟, 正常情况不应该出现这个问题, 这样就找到了一条可以深入的线索。
$ sudo blktrace -d /dev/sdb -w 5
$ blkparse sdb -d sdb.bin
$ btt -i sdb.bin
==================== All Devices ====================
ALL MIN AVG MAX N
--------------- ------------- ------------- ------------- -----------
Q2Q 0.000000001 0.000014397 0.008275391 347303
Q2G 0.000000499 0.000071615 0.010518692 347298
S2G 0.000128160 0.002107990 0.010517875 11512
G2I 0.000000600 0.000001570 0.000040010 347298
I2D 0.000000395 0.000000929 0.000003743 347298
D2C 0.000116199 0.000144157 0.008443855 347288
Q2C 0.000118211 0.000218273 0.010678657 347288
==================== Device Overhead ====================
DEV | Q2G G2I Q2M I2D D2C
---------- | --------- --------- --------- --------- ---------
( 8, 16) | 32.8106% 0.7191% 0.0000% 0.4256% 66.0447%
---------- | --------- --------- --------- --------- ---------
Overall | 32.8106% 0.7191% 0.0000% 0.4256% 66.0447%
进阶篇
大学教材
通过教程能够系统地了解一门课的全貌, 网上搜到的大部分性能分析的教程都是基于Raj Jain的The Art of Computer Systems Performance Analysis, 这本书里面主要包括几个部分:
- Part I: AN OVERVIEW OF PERFORMANCE EVALUATION
- Part II: MEASUREMENT TECHNIQUES AND TOOLS
- Part III: PROBABILITY THEORY AND STATISTICS
- Part IV: EXPERIMENTAL DESIGN AND ANALYSIS
- Part V: SIMULATION
- Part VI: QUEUEING MODELS
书的重心放在performance analysis上面, 涉及较多概率和统计的计算, 另外rice大学的这个教程写得挺不错[1]。
技术博客
- 参考文末[2]有时间可以都过一遍, 总的来说主要包括3个部分:
- 性能分析的方法集. 代表作 USE方法
- 性能数据的搜集. 代表作 "工具大图"
- 性能数据的可视化. 代表作 火焰图
- 文末链接[3]
- 文末链接[4]
- 文末链接[5]
知识结构
系统性能分析在深度和广度上都有要求, 对底层包括OS和硬件, 以及一些通用能力要做到足够深, 对上层产品的理解又需要有足够的广度, 近一年在混合云亲手摸过的产品估计不下二十款, 当然重点分析过的只有几个。
操作系统
操作系统是系统分析的基础, 不管是I/O, 内存, 网络, 调度, docker等等都离不开操作系统, 操作系统知识可以从Understanding the Linux Kernel开始, 这本书虽然老了但不妨碍理解OS的基本概念, 慢慢做到能阅读内核文档和源码。
在适配某款arm平台的时候发现, 在numa off的情况下:
- ecs绑在socket 0上性能好
- mysql绑在socket 1上性能好
能确定的是, 该平台跨socket性能访问不管是latency还是throughput和本地访问都有较大差距, 所以一个合理的方向是跨socket的内存访问, 如果有类似x86 pcm的话会比较直接, 但是该平台上缺少该类pmu来查看跨socket的信息, 我们尝试从OS的角度来回答这个问题。
首先通过将内存压测工具跑在不同的socket/node上, 发现numa off表现出了和numa on相同的性能特征, 和硬件产生确认该平台numa off和on的实现在硬件上并没有区别, 只是bios不传递numa信息给操作系统, 这样是可以知道物理地址在哪个socket/node上的。
接下来只要确定ecs/mysql的物理内存位置, 就可以用于判断性能和跨socket的相关性. Linux在用户态可以通过pagemap将虚拟地址对应到物理地址, 只需要稍加修改tools/vm/page-types.c就能拿到进程对应的所有物理地址. 经确认, 确实ecs/mysql的性能和它们使用的物理内存的位置强相关。最后要回答的是为什么ecs和mysql表现恰好相反, 注意到ecs使用hugepage而mysql使用normal page, 有如下假设, 具体代码这里不再列出。
- 系统启动的时候, 物理内存加到伙伴系统是先socket 0后socket 1
- socket 1上的内存会被先分出来, 所以mysql分配的内存在socket 1. 特定集群的机器不会随意跑其他进程
- 在ecs的host上, 因为要分配的hugepage已经超过了socket 1上的所有内存, 所以后面分配的hugepage已经落在了socket 0
- hugepage的分配是后进先出, 意味着ecs一开始分配到的hugepage在socket 0, 而该机器资源并没全部用完, 测试用的几个ecs内存全落在了socket 0上, 所以将ecs进程绑到socket 0的性能更好
硬件知识
如果一直是x86架构, 事情会简单很多, 一是x86的知识大家耳濡目染很久了, 多多少少都了解一些, 二是架构变化相对较小, 各种应用都适配较好, 需要调优的用例较少. 随着各种新平台的崛起, 它们性能各异, 对整个系统性能带来的冲击是巨大的, 这不是影响某个产品, 这影响的几乎是所有产品. 最基本地, 我们要处理以下问题:
- 新的平台上, 应用原有的很多假设被打破, 需要重新适配, 否则性能可能不及预期. 比如在Intel上面, 开关numa的性能差距不大, 在其他平台上可能就不一样
- 新的平台要取代老的平台, 就存在性能的比较. 由于平台性能差异大并且差异点多, 虽然speccpu之类的benchmark能一定程度反应平台整体的计算性能, 但很多时候还需要结合不同场景分别进行性能调优
- 不排除新平台存在某种bug或者未知的feature, 都需要我们去摸索解决的办法
数据分析
在收集了大量数据后, 经过数据分析可以放大数据的价值
- 数据提取. 利用各种工具比如awk/sed/perl等脚本语言提取所需的数据
- 数据抽象. 从不同角度加工数据, 识别异常, 比如单机/集群分别是什么表现, 统计哪些值
- 可视化. 可视化是数据处理非常重要的能力, 一图胜千言, 火焰图就是最好的例子. 常用画图工具有gnuplot, excel等
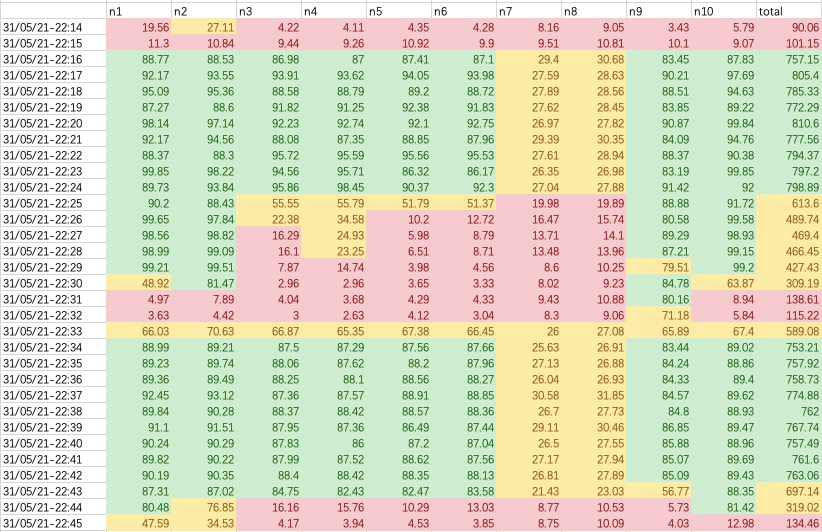
比如分析MapReduce任务在10台机器的集群上的性能, 即使每台机器都体现出一定的共性, 但是如果从集群角度看的话则更加明显, 也很容易验证这种共性。
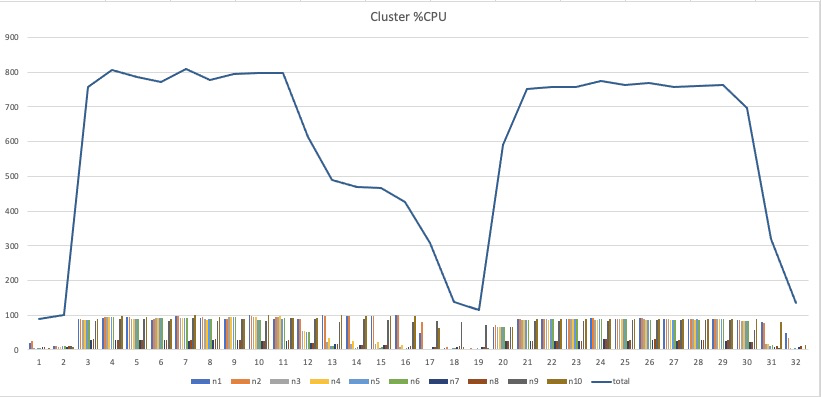
换种显示方式则更加明显, 很容易知道在不同阶段的表现, 比如正常Map和Reduce阶段cpu利用率也只有80%, 这个是否符合预期, 另外在Map和Reduce切换的时候, 系统idle很明显, 会不会是潜在优化点。
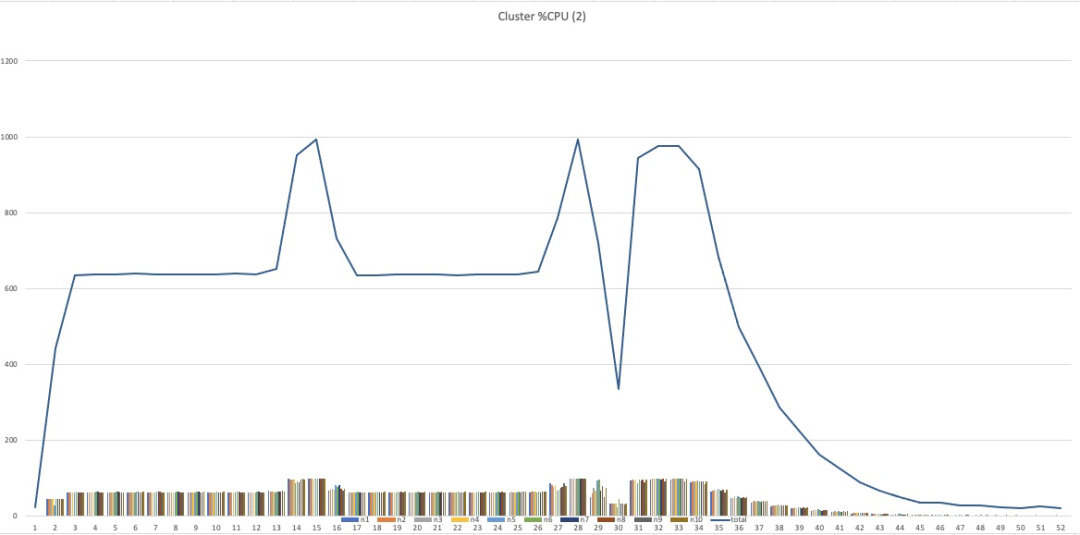
如果有对照的话, 可以直观地看不到不同表现, 特别是巨大的长尾时间有进一步优化的空间。

Benchmarking
Benchmarking是获取性能指标最基本的手段, 也是测试常用的方法, 每个领域几乎都有自己的一套测试用例. 对于benchmarking, 首先需要知道它测的是什么. 以spec cpu2017为例, 它主要测试的是处理器, 内存子系统以及编译器的性能, 那么在测试的时候我们除了关注CPU型号, 还要考虑内存大小插法型号, 以及编译器及其参数等等, 在做性能比对时也能清楚它的使用范围。
Benchmark的一个特点是可重复性, spec.org做得很好的一点是上面有大量公布的测试结果, 可以参考这些测试结果来验证我们自己的测试方法参数是否合理. 如果想测试cpu2017, 第一件事就是先重做别人的测试, 直到能复现别人的数据, 这个过程可能会有很多收获, 对benchmark也会有更多了解. 以intel 8160为例, 在硬件基本一致的情况下, 不经额外的配置自己环境cpu2017 integer rate只能跑到140, 而spec.org上面的测试用例能达到240, 性能逐步逼近240的过程, 也是深入理解cpu2017的过程。
关于性能数据, 首先想要强调的是有数据并不一定比没数据强, 只有解释过的数据才是有效数据, 没解释过的数据反而会引起不必要的误判, 比如上面cpu2017的例子, 在做不同平台性能对比的时候, 8160到底用140还是240呢, 得出的结论会十万八千里. 再比如使用下面的命令测试某新平台的内存延迟:
lat_mem_rd -P 1 -N 1 10240 512
测试出的延迟是7.4ns, 不加分析采用该结果就可能得出新平台延迟太好的错误结论. 所以对待数据要足够谨慎, 一般会有几个阶段:
- 在信任关系建立前, 对别人的数据保持谨慎. 一是有可能自己对这块还没有足够理解, 二是需要测试报告提供足够的信息供他人做判断。
- 相信自己的数据. 必须相信自己, 但是选择相信自己的数据, 是因为有过详细合理的分析。
- 相信别人的数据. 信任链建立之后, 以及自己有了足够理解后, 选择相信.
更多工具
ftrace
想要快速理解代码实现, 没有什么比打印调用路径更直接了. ftrace可以用来解决2个问题:
- 谁调用了我. 这个只要在执行对应函数的时候拿到对应的栈就可以, 多种工具可以实现
- 我调用了谁. 这个是ftrace比较unique的功能
为了方便我们使用ftrace的wrapper trace-cmd, 假设我们已经知道I/O路径会经过generic_make_request, 为了查看完整的路径我们可以这样:
#trace-cmd record -p function --func-stack -l generic_make_request dd if=/dev/zero of=file bs=4k count=1 oflag=direct
通过report来查看就一目了然了:
#trace-cmd report
cpus=128
dd-11344 [104] 4148325.319997: function: generic_make_request
dd-11344 [104] 4148325.320002: kernel_stack: <stack trace>
=> ftrace_graph_call (ffff00000809849c)
=> generic_make_request (ffff000008445b80)
=> submit_bio (ffff000008445f00)
=> __blockdev_direct_IO (ffff00000835a0a8)
=> ext4_direct_IO_write (ffff000001615ff8)
=> ext4_direct_IO (ffff0000016164c4)
=> generic_file_direct_write (ffff00000825c4e0)
=> __generic_file_write_iter (ffff00000825c684)
=> ext4_file_write_iter (ffff0000016013b8)
=> __vfs_write (ffff00000830c308)
=> vfs_write (ffff00000830c564)
=> ksys_write (ffff00000830c884)
=> __arm64_sys_write (ffff00000830c918)
=> el0_svc_common (ffff000008095f38)
=> el0_svc_handler (ffff0000080960b0)
=> el0_svc (ffff000008084088)
现在如果我们想继续深入generic_make_request, 使用function_graph plugin:
$ sudo trace-cmd record -p function_graph -g generic_make_request dd if=/dev/zero of=file bs=4k count=1 oflag=direct
这样就可以拿到整个调用过程 (report结果稍微整理过):
$ trace-cmd report
dd-22961 | generic_make_request() {
dd-22961 | generic_make_request_checks() {
dd-22961 0.080 us | _cond_resched();
dd-22961 | create_task_io_context() {
dd-22961 0.485 us | kmem_cache_alloc_node();
dd-22961 0.042 us | _raw_spin_lock();
dd-22961 0.039 us | _raw_spin_unlock();
dd-22961 1.820 us | }
dd-22961 | blk_throtl_bio() {
dd-22961 0.302 us | throtl_update_dispatch_stats();
dd-22961 1.748 us | }
dd-22961 6.110 us | }
dd-22961 | blk_queue_bio() {
dd-22961 0.491 us | blk_queue_split();
dd-22961 0.299 us | blk_queue_bounce();
dd-22961 0.200 us | bio_integrity_enabled();
dd-22961 0.183 us | blk_attempt_plug_merge();
dd-22961 0.042 us | _raw_spin_lock_irq();
dd-22961 | elv_merge() {
dd-22961 0.176 us | elv_rqhash_find.isra.9();
dd-22961 | deadline_merge() {
dd-22961 0.108 us | elv_rb_find();
dd-22961 0.852 us | }
dd-22961 2.229 us | }
dd-22961 | get_request() {
dd-22961 0.130 us | elv_may_queue();
dd-22961 | mempool_alloc() {
dd-22961 0.040 us | _cond_resched();
dd-22961 | mempool_alloc_slab() {
dd-22961 0.395 us | kmem_cache_alloc();
dd-22961 0.744 us | }
dd-22961 1.650 us | }
dd-22961 0.334 us | blk_rq_init();
dd-22961 0.055 us | elv_set_request();
dd-22961 4.565 us | }
dd-22961 | init_request_from_bio() {
dd-22961 | blk_rq_bio_prep() {
dd-22961 | blk_recount_segments() {
dd-22961 0.222 us | __blk_recalc_rq_segments();
dd-22961 0.653 us | }
dd-22961 1.141 us | }
dd-22961 1.620 us | }
dd-22961 | blk_account_io_start() {
dd-22961 0.137 us | disk_map_sector_rcu();
dd-22961 | part_round_stats() {
dd-22961 0.195 us | part_round_stats_single();
dd-22961 0.054 us | part_round_stats_single();
dd-22961 0.955 us | }
dd-22961 2.148 us | }
dd-22961 + 15.847 us | }
dd-22961 + 23.642 us | }
uftrace
uftrace在用户态实现了一个类似ftrace的功能, 对需要快速理解用户态的逻辑会有帮助, 但是需要加上-pg重新编译源码, 详情见[6]。
#gcc -pg a.c
#uftrace ./a.out
# DURATION TID FUNCTION
[ 69439] | main() {
[ 69439] | A() {
0.160 us [ 69439] | busy();
1.080 us [ 69439] | } /* A */
[ 69439] | B() {
0.050 us [ 69439] | busy();
0.240 us [ 69439] | } /* B */
1.720 us [ 69439] | } /* main */
BPF
BPF (eBPF) 是这几年的热点, 通过BPF几乎可以看清系统的各个角落, 给诊断带来了极大的方便. BPF不是一个工具, BPF是生产工具的工具, BPF工具编写是性能分析必须掌握的技能之一。
这里举个使用BPF来分析QEMU I/O延迟的例子. 为了简化问题, 先确保vm里面的块设备只有fio在使用, fio控制设备只有一个并发I/O, 这样我们在host上选择2个观察点:
- tracepoint:kvm:kvm_mmio. host捕获guest mmio操作, guest里面最终通过写该mmio发送请求给host
- kprobe:kvm_set_msi. 因为guest里面vdb使用msi中断, 中断最终通过该函数注入
因为host上有多个vm和虚拟盘需要区分, 使用以下信息捕获并且只捕获我们关注的这个设备:
- 只关注该qemu-kvm pid
- vbd mmio对应的gpa, 这个可以在guest里面通过lspci获得
对于kvm_set_msi, 使用如下信息:
- struct kvm的userspace_pid, struct kvm对应的qemu-kvm进程
- struct kvm_kernel_irq_routing_entry的msi.devid, 对应到pci设备id
#include <linux/kvm_host.h>
BEGIN {
@qemu_pid = $1;
@mmio_start = 0xa000a00000;
@mmio_end = 0xa000a00000 + 16384;
@devid = 1536;
}
tracepoint:kvm:kvm_mmio /pid == @qemu_pid/ {
if (args->gpa >= @mmio_start && args->gpa < @mmio_end) {
@start = nsecs;
}
}
kprobe:kvm_set_msi {
$e = (struct kvm_kernel_irq_routing_entry *)arg0;
$kvm = (struct kvm *)arg1;
if (@start > 0 && $kvm->userspace_pid == @qemu_pid && $e->msi.devid == @devid) {
@dur = stats(nsecs - @start);
@start = 0;
}
}
interval:s:1 {
print(@dur); clear(@dur);
}
执行结果如下:
@dur: count 598, average 1606320, total 960579533 @dur: count 543, average 1785906, total 969747196 @dur: count 644, average 1495419, total 963049914 @dur: count 624, average 1546575, total 965062935 @dur: count 645, average 1495250, total 964436299
更深理解
很多技术需要反复去理解验证, 每一次可能都有不同的收获, 这里举个loadavg的例子. 引用kernel/sched/loadavg.c最开始的一段注释:
5 * This file contains the magic bits required to compute the global loadavg 6 * figure. Its a silly number but people think its important. We go through 7 * great pains to make it work on big machines and tickless kernels.
这里的silly我想说的是loadavg有一定的局限性, 总的来说loadavg是有一定语义和价值的, 毕竟它只用了3个数字描述了过去一段时间的"load", 反过来说如果loadavg is silly, 那么有没有更好的选择?
- 如果是实时观察的话, vmstat/dstat输出的runnable和I/O blocked的信息是种更好的选择, 因为相对于loadavg每5秒的采样, vmstat可以做到粒度更细, 而且loadavg的算法某种程度可以理解为有损的。
- 如果是sar/tsar的话, 假设收集间隔是10min的话, loadavg因为能覆盖更大的范围, 确实比10min一个的数字包含更多的信息, 但我们需要思考它对调试的真正价值.
另外, 5秒钟的采样间隔是比较大的, 我们可以构造个测试用例执行了大量时间但跳过采样
- 获取load采样点的时间
- 测试用例刚好跳过该采样点
查看calc_load_fold_active在cpu 0上的调用时间:
kprobe:calc_load_fold_active /cpu == 0/ {
printf("%ld\n", nsecs / 1000000000);
}
运行没有输出, 监控上一层函数:
#include "kernel/sched/sched.h"
kprobe:calc_global_load_tick /cpu == 0/ {
$rq = (struct rq *)arg0;
@[$rq->calc_load_update] = count();
}
interval:s:5 {
print(@); clear(@);
}
执行结果符合预期:
#./calc_load.bt -I /kernel-source @[4465886482]: 61 @[4465887733]: 1189 @[4465887733]: 62 @[4465888984]: 1188
查看汇编发现这里代码被优化, 但是刚好id_nr_invalid调用没优化, 当然最方便的是能够直接在函数偏移处直接打点:
kprobe:id_nr_invalid /cpu == 0/ {
printf("%ld\n", nsecs / 1000000000);
}
根据这个时间戳, 可以很容易跳过load的统计:
while :; do
sec=$(awk -F. '{print $1}' /proc/uptime)
rem=$((sec % 5))
if [ $rem -eq 2 ]; then # 1s after updating load
break;
fi
sleep 0.1
done
for i in {0..63}; do
./busy 3 & # run 3s
done
- 系统级别的统计, 和具体应用产生的联系不够直接
- 使用采样的方式并且采样间隔 (5s) 较大, 有的场景不能真实反映系统
- 统计的间隔较大(1/5/15分钟), 不利于及时反映当时的情况
- 语义稍微不够清晰, 不只包括cpu的load, 还包括D状态的任务, 这个本身不是大问题, 更多可以认为是feature
Linux增加了Pressure Stall Information (PSI), PSI从任务的角度分别统计了10/60/300s内因为cpu/io/memory等资源不足而不能运行的时长, 并按照影响范围分成2类:
- some - 因为缺少资源导致部分任务不能执行
- full - 因为缺少资源导致所有任务不能执行, cpu不存在这种情况
我们在一台96c的arm机器上扫描所有cgroup的cpu.pressure:
这里会引出几个问题, 篇幅原因这里不再展开。
- 父cgroup的avg为什么比子cgroup还小? 是实现问题还是有额外的配置参数?
- avg10等于33, 也就是1/3的时间有task因为没有cpu而得不到执行, 考虑到系统cpu利用率在40%左右并不算高, 我们怎么合理看待和使用这个值
top - 09:55:41 up 127 days, 1:44, 1 user, load average: 111.70, 87.08, 79.41 Tasks: 3685 total, 21 running, 2977 sleeping, 1 stopped, 8 zombie %Cpu(s): 27.3 us, 8.9 sy, 0.0 ni, 59.8 id, 0.1 wa, 0.0 hi, 4.0 si, 0.0 st
RTFSC
有的时候RTFM已经不够了, 手册包括工具本身的更新没对上内核的节奏, 我们回到上面页面回收的例子, 估计有的同学之前就有疑问, 没有scan哪里来的steal。
#sar -B 1
11:00:16 AM pgscank/s pgscand/s pgsteal/s %vmeff
11:00:17 AM 0.00 0.00 3591.00 0.00
11:00:18 AM 0.00 0.00 10313.00 0.00
11:00:19 AM 0.00 0.00 8452.00 0.00
先看sysstat (sar) 里面的实现, 主要是读取分析/proc/vmstat:
- pgscand: 对应到pgscan_direct域
- pgscank: 对应到pgscan_kswapd域
- pgsteal: 对应到pgsteal_开头的域
#gdb --args ./sar -B 1
(gdb) b read_vmstat_paging
(gdb) set follow-fork-mode child
(gdb) r
Breakpoint 1, read_vmstat_paging (st_paging=0x424f40) at rd_stats.c:751
751 if ((fp = fopen(VMSTAT, "r")) == NULL)
(gdb) n
754 st_paging->pgsteal = 0;
(gdb)
757 while (fgets(line, sizeof(line), fp) != NULL) {
(gdb)
759 if (!strncmp(line, "pgpgin ", 7)) {
(gdb)
763 else if (!strncmp(line, "pgpgout ", 8)) {
(gdb)
767 else if (!strncmp(line, "pgfault ", 8)) {
(gdb)
771 else if (!strncmp(line, "pgmajfault ", 11)) {
(gdb)
775 else if (!strncmp(line, "pgfree ", 7)) {
(gdb)
779 else if (!strncmp(line, "pgsteal_", 8)) {
(gdb)
784 else if (!strncmp(line, "pgscan_kswapd", 13)) {
(gdb)
789 else if (!strncmp(line, "pgscan_direct", 13)) {
(gdb)
757 while (fgets(line, sizeof(line), fp) != NULL) {
(gdb)
看下/proc/vmstat都有什么:
#grep pgsteal_ /proc/vmstat pgsteal_kswapd 168563 pgsteal_direct 0 pgsteal_anon 0 pgsteal_file 978205 #grep pgscan_ /proc/vmstat pgscan_kswapd 204242 pgscan_direct 0 pgscan_direct_throttle 0 pgscan_anon 0 pgscan_file 50583828
最后看看内核的实现, pgsteal和pgscan的逻辑是一样, 除了nr_scanned换成了nr_reclaimed:
if (current_is_kswapd()) {
if (!cgroup_reclaim(sc))
__count_vm_events(PGSCAN_KSWAPD, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_KSWAPD,
nr_scanned);
} else {
if (!cgroup_reclaim(sc))
__count_vm_events(PGSCAN_DIRECT, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_DIRECT,
nr_scanned);
}
__count_vm_events(PGSCAN_ANON + file, nr_scanned);
现在问题很清晰了:
- 这里sar取得是系统的/proc/vmstat, 而cgroup里面pgscan_kswapd和pgscan_direct只会加到cgroup的统计, 不会加到系统级的统计
- cgroup里面pgsteal_kswapd和pgsteal_direct同样只会加到cgroup自己的统计
- 但是主要pgscan_anon, pgscan_file和pgsteal_anon, pgsteal_file都只加到系统级的统计
- sar读取了pgscan_kswapd, pgscan_direct, 以及pgsteal_*, 这里*还包括了pgsteal_anon和pgsteal_file
这整个逻辑都乱了, 我们有必要解决这个bug让sar的输出变得更加有意义. 那么在cgroup内是不是没问题?
#df -h . Filesystem Size Used Avail Use% Mounted on cgroup 0 0 0 - /sys/fs/cgroup/memory #grep -c 'pgscan\|pgsteal' memory.stat 0
这些统计信息在cgroup v1上完全没有输出, 而只在v2版本有输出. 在以前内核没有专门LRU_UNEVICTABLE的时候, 如果有很多比如mlock page的时候, 碰到过不停扫描却不能回收内存的情况, 这个统计会非常有用, 即使是现在我相信这个统计还是有用的, 只是大部分时候还不用看到这么细。
多上手
纸上得来终觉浅, 自己动手去做带来很多好处:
- 回答预设问题. 调试分析就是不断提出问题和验证的过程, 没有上手的话就会一直停留在第一个问题上. 比如我想了解某平台上物理内存是怎么编址的, 没有文档的话只能自己去实验
- 提出新的问题. 调试分析中不怕有问题, 怕的是提不出问题
- 会有意外收获. 很多时候并不是有意为之, 比如准备的是分析cpu调频能否降功耗, 上去却发现系统一直运行在最低频率
- 熟练. 熟练就是效率
- 改进产品. 可以试想下在整个云环境所有机器上扫描 (类似全面体检) 会发现多少潜在问题
参考资料
[1]https://www.cs.rice.edu/~johnmc/comp528/lecture-notes/
[2]https://brendangregg.com/
[3]http://dtrace.org/blogs/bmc/
[4]https://blog.stgolabs.net/
[5]https://lwn.net/
[6]https://github.com/namhyung/uftrace
[7]https://www.brendangregg.com/[8]The Art of Computer Systems Performance Analysis
本文为阿里云原创内容,未经允许不得转载。

