
如何在云原生混部场景下利用资源配额高效分配集群资源?
引言
在阿里集团,离线混部技术从 2014 年开始,经历了七年的双十一检验,内部已实现大规模落地推广,每年为阿里集团节省数十亿的资源成本,整体资源利用率为 70%左右,达到业界领先水平。这两年,我们开始把集团内的混部技术通过产品化的方式输出给业界,通过插件化的方式无缝安装在标准原生的 K8s 集群上,配合混部管控和运维能力,提升集群的资源利用率和产品的综合用户体验。
由于混部是一个复杂的技术及运维体系,包括 K8s 调度、OS 隔离、可观测性等等各种技术,之前的一篇文章《
资源配额概述
首先想提一个问题,在设计上,既然 K8s 的调度器已经可以在没有资源的情况下,让 pod 处于 pending 状态,那为什么,还需要有一个资源配额(Resource Quota)的设计?
我们在学习一个系统时,不但要学习设计本身,还需要考虑为什么这个设计是必须的?如果把这个设计从系统中砍掉,会造成什么后果?因为在一个系统中增加任何一项功能设计,都会造成好几项边际效应(Side Effect),包括使用这个系统的人的心智负担,系统的安全性、高可用性,性能,都需要纳入考虑。所以,功能不是越多越好。越是优秀的系统,提供的功能反而是越少越好。例如 C 语言只有 32 个关键字,而用户可以通过自定义组合这些基础能力,实现自己想要的任何需求。
回到原问题,一个集群的资源一定是有限的,无论是物理机上的 CPU、内存、磁盘,还有一些别的资源例如 GPU 卡这些。光靠调度,是否能解决这个问题呢?如果这个集群只有一个用户,那么这个问题其实还是能忍受的,例如看到 pod pending了,那就不创建新的 pod 了;如果新的 pod 比较重要,这个用户可以删掉旧的 pod,然后再创建新的。但是,真实的集群是被多个用户或者说团队同时使用的,当 A 团队资源不够了,再去等 B 团队的人决策什么应用可以腾挪出空间,在这个时候,跨团队的交流效率是非常低下的。所以在调度前,我们就需要再增加一个环节。如下图所示:

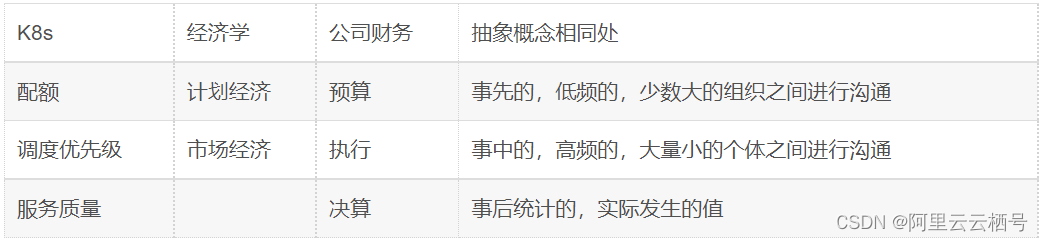
所以从这个角度来说,资源配额,是多个租户之间低频高效率沟通合作的一种方式。如果把配额这个概念放到经济学中,是不是就有点计划经济的感觉了呢?其实里面的核心思想是一致的,都是在有限的资源情况下,各个组织之间在事先达成一个高效率的合作沟通方案。
低优资源配额从哪里来?
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/qosClass: BE # {LSR,LS,BE}
spec:
containers:
- resources:
limits:
alibabacloud.com/reclaimed-cpu: 1000 # 单位 milli core,1000表示1Core
alibabacloud.com/reclaimed-memory: 2048 # 单位 字节,和普通内存一样。单位可以为 Gi Mi Ki GB MB KB
requests:
alibabacloud.com/reclaimed-cpu: 1000
alibabacloud.com/reclaimed-memory: 2048
再回到今天想讨论的话题,云原生混部的资源配额,和 K8s 社区原生的资源配额有什么区别?从上面的 yaml 配置可以看到,低优资源我们使用了社区的扩展资源来进行管理,所以,很顺理成章的就是对低优 CPU 和低优内存做一个配额总量的控制,并且这些总量会在不同部门之间进行事先的预算分配,这些逻辑和社区的资源配额逻辑是一样的,在这里就不赘述了,大家可以看社区的官方文档:《资源配额》
但是低优资源还有一些逻辑是和社区资源配额是不一样的,并且,由于 CPU 和内存这 2 种资源天生的特性不同,所以还有区别,接下来用一张表来展现这个概念。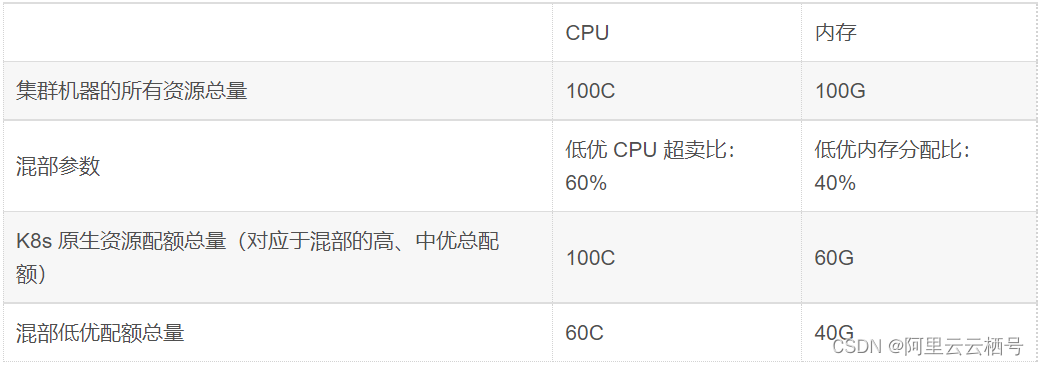
![]()
可以看到,由于 CPU 是可压缩资源,我们引入了低优 CPU 超卖比这个参数,在原有集群 100C 的基础上,可以另外超卖出 60C 的资源,给所有的低优任务使用。而对于内存这种不可压缩资源而言,总体 100G,按照低优内存分配比这个参数,划分了 40G 之后,剩下给高中优的用量就只剩 60G 了。因为在混部集群的管理中,由此得到的一个结论就是,要给集群的机器配置更多的内存,这样才有足够的数量不影响在线业务使用。
注:可压缩资源(例如 CPU 循环,disk I/O 带宽)都是速率性的可以被回收的,对于一个 task 可以降低这些资源的量而不去杀掉 task;和不可压缩资源(例如内存、硬盘空间)这些一般来说不杀掉 task 就没法回收的。
《在 Google 使用 Borg 进行大规模集群的管理 5-6》- 6.2 性能隔离
这里顺便卖个关子,具体这个配比多少是合适的,包括这几个参数到底设置多少是合理的,在阿里云的商用产品 ACK 敏捷版混部里面会有具体内容输出。
基于容量的弹性配额调度
云原生混部在配额方面,和社区的第二个区别在哪里呢?可以看到的是,引入混部后会引入大量的离线运算任务,和比较有规律的在线业务相比,离线任务像洪水一样是一波一波的,在整个时间区间内更不规律。有可能 A 团队在跑大数据计算,把自己的低优配额都跑完了,但是 B 团队的大数据计算这个时候还没跑,还有空闲的配额。
那么,是否可以把这部分的配额利用起来,先“借”给 A 部门使用呢?这里就可以引入另外一个能力,基于容量的配额调度。

- 支持定义不同层级的资源配额。如上图所示,您可以根据具体情况(比如:公司的组织结构)配置多个层级的弹性配额。弹性配额组的叶子节点可以对应多个 Namespace,但同一个 Namespace 只能归属于一个叶子节点。
- 支持不同弹性配额之间的资源借用和回收。
- Min:您可以使用的保障资源(Guaranteed Resource)。当整个集群资源紧张时,所有用户使用的 Min 总和需要小于集群的总资源量。
- Max:您可以使用的资源上限。
引入了这个弹性配额调度后,我们发现组织中多个团队在使用低优资源时的“弹性”更强了,当 B 团队有空闲的配额时,可以动态的“借”给 A 团队使用,反之亦然。这样集群在全时间段里面的利用率进一步提升,更充分和有效的利用了集群的资源。
相关解决方案介绍
进入了 2022 年,混部在阿里内部已经成为了一个非常成熟的技术,为阿里每年节省数十亿的成本,是阿里数据中心的基本能力。而阿里云也把这些成熟的技术经过两年的时间,沉淀成为混部产品,开始服务于各行各业。
在阿里云的产品族里面,我们会把混部的能力通过 ACK 敏捷版,以及 CNStack(CloudNative Stack)产品家族,对外进行透出,并结合龙蜥操作系统(OpenAnolis),形成完整的云原生数据中心混部的一体化解决方案,输出给我们的客户。
预告:关于混部水位线,也就是保障可靠性的最后一道防线,我们会在后一篇文章里面进行介绍。
参考链接
1、《资源配额》:
2、《在Google使用Borg进行大规模集群的管理 5-6》:
3、《Capacity Scheduling》:
4、龙蜥操作系统
本文为阿里云原创内容,未经允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号