
小红书消息中间件的运维实践与治理之路
简介:近年来,消息领域的全面云原生化逐渐走向深入,比如 RocketMQ 5.0 版本的存算分离设计和 raft 模式,再比如 Kafka3.0 引入了分层设计的方式(tiered storage)和 raft 模式,以及近年来新崛起的 Pulsar 也开始采用云原生架构,在未来都可以针对具体业务需求引入进行功能迭代,发挥组件的最大价值。

作者:张亿皓|小红书消息中间件负责人
一、消息队列业务场景与挑战
1、整体规模
下图展示了 RocketMQ 和 Kafka 的总体规模。其中峰值 TPS 的 8000w/s 一般出现在晚上下班以后的时间段,写入量达到50GB/s,每天新增2-3PB数据,节点数1200+个。

2、业务架构
虽然 RocketMQ 和 Kafka 的性能相似,但在使用场景上还是有所区别的。RocketMQ 丰富的业务特性更适用于在线业务场景,而 Kafka 的高吞吐性使其更偏向离线、近线业务。当然,在实际应用中也会有交叉使用的现象,有时在线业务也会使用 Kafka 解耦,有的流处理数据也会使用 RocketMQ 存储。
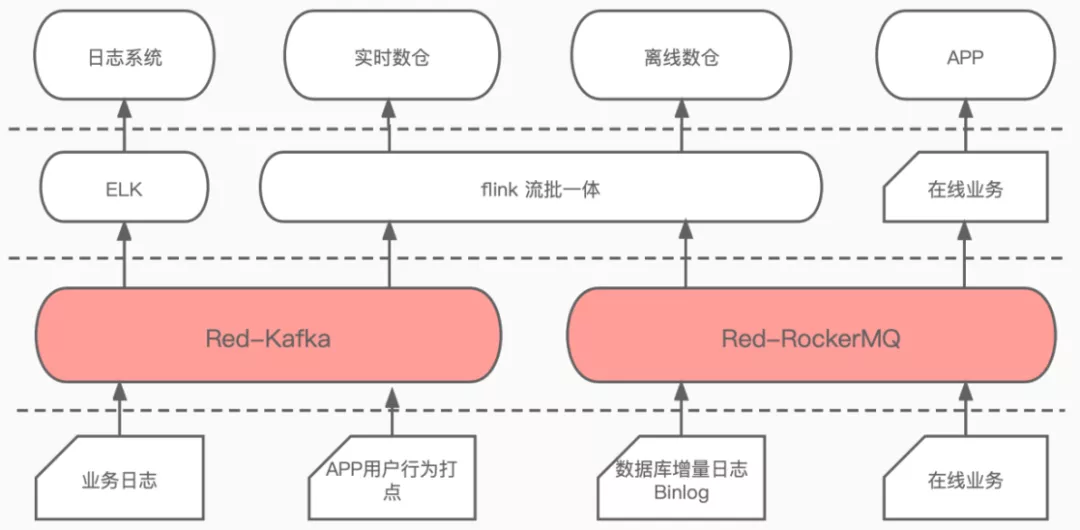
业务总体架构如下图所示,业务日志和APP用户行为打点类的内容会发给 Kafka,数据库增量日志、在线业务、线上数据交换等会发给 RocketMQ。Kafka 和 RocketMQ 中的数据会有一部分流入 flink 中构建实时数仓、离线数仓以及一些数据产品(如报表、监控,等),RocketMQ 中另一部分数据会用于在线业务APP异步解耦。
3、稳定性挑战
a. 背景:
小红书整体收敛消息组件较晚,公司技术架构最大的目标是提升系统稳定性;
b. 挑战:
现存消息组件使用量极大,但没有稳定性保障;同时面临人手紧缺、时间紧,对MQ原理了解不深入的困境;
c. 策略:
先做监控,增强集群的可观测能力是了解其健康状况的最高效手段。
4、稳定性治理
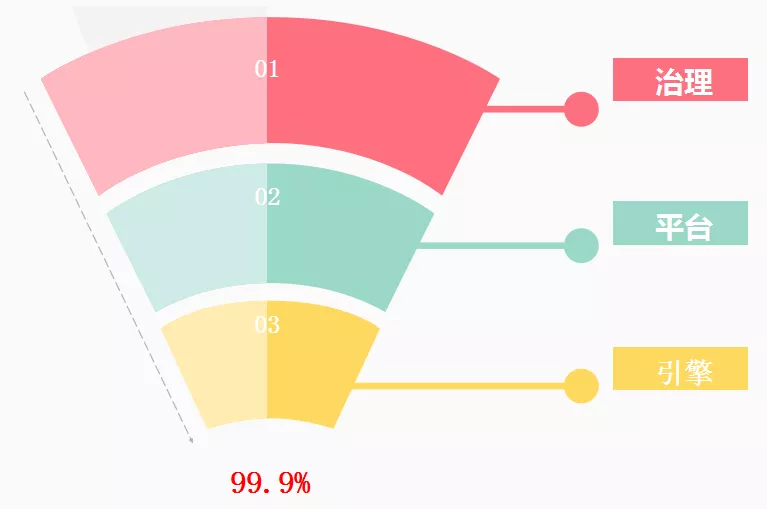
除了监控告警,我们在稳定性治理方面还做了以下改造工作:
a. 引擎:资源隔离,新增监控打点等;
b. 平台:工单审核,权限管控,业务追溯;
c. 治理:针对集群可视化能力和集群可运维能力的建设;
二、消息队列治理实践
1、集群可视化:监控metrics
下图是基于 Prometheus Grafana 构建的消息中间件体系架构。
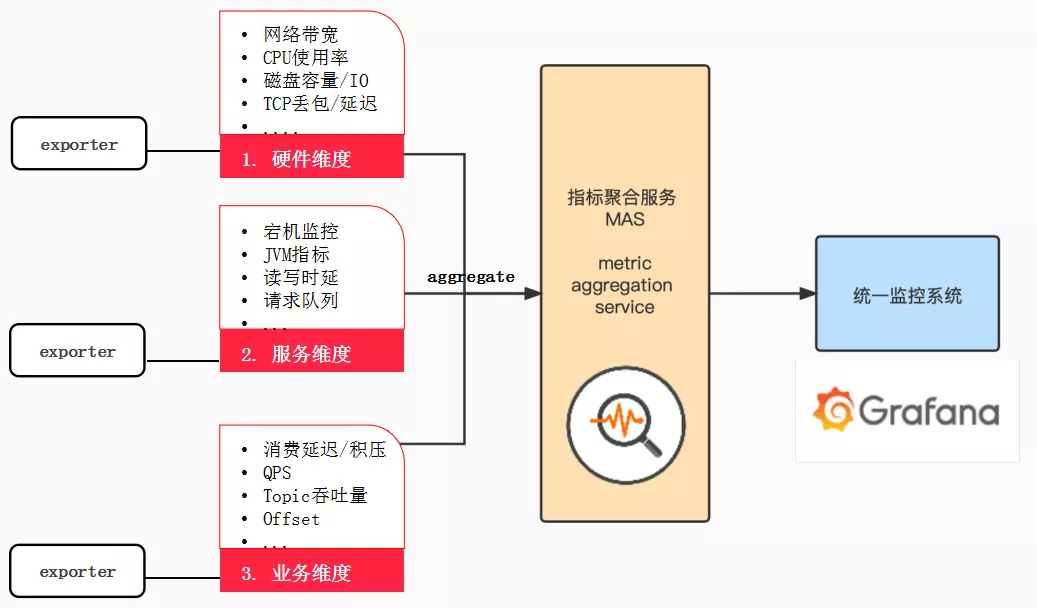
图中包含三个监控维度:硬件维度、服务维度和业务维度,累计收集监控指标150+项。
那么如何定义这三个维度的监控指标呢?
a. 硬件维度:主要包括网络带宽、CPU使用率、磁盘容量/IO、TCP丢包/延迟等资源指标;
b. 服务维度:主要指运行状况的指标,如:宕机监控、JVM指标、读写时延、请求队列等;
c. 业务维度:即面向用户的指标,这是客户比较关心的指标,如:消费延迟/积压、QPS、Topic吞吐量、Offset等;
由于公司内部规定一个节点只能使用一个端口给Prometheus,而各项监控指标大多是分开收集,于是设计了指标聚合服务 MAS 将所有指标汇集在一起,同时又增加了一些元信息帮助进一步排查问题。这里 MAS 相当于metric 的一个代理层,可以根据业务的实际情况来添加。
2、告警处理
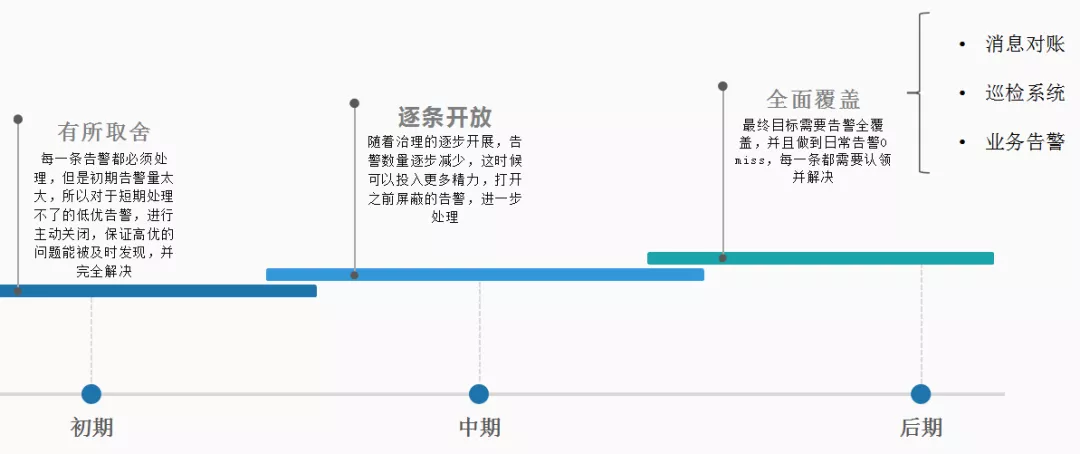
下图列举了一些发生在监控体系刚建立时候的告警信息,当时每天的告警信息约有600-700条之多,告警的问题也是各式各样,根本无法处理,造成监控系统形同虚设。


- 初期:关闭低优告警,以确保每一条高优告警能得到及时发现和处理;
- 中期:随着高优告警的减少,逐步打开之前屏蔽的告警,进一步处理,实现告警数量逐步减少;
- 后期:打开全部告警,确保日常告警每一条都能及时发现和处理。
根据我们的经验,到后期基本不会有“服务不可用”这类的告警,大部分告警属于预警,如果预警能及时介入处理,就可以确保在问题进一步扩大之前解决。
3、集群可视化:metric设计与优化
RocketMQ 的服务、业务指标监控,基于开源 RocketMQ-exporter 进行改造,解决 metrics 泄漏、部分指标采集偏差等问题。
这里着重介绍两个比较重要的改造:
a. lag监控优化
- 问题一:consumer metric 泄露,exporter 运行几天指标量就可达到 300w+,curl 一次接口花费时间 25s,log文本有600MB;
原因:如下图所示,每接入新的客户端,端口值就会增加,由于exporter实现中没能将离线客户端指标值及时清理造成客户端端口持续增加导致系统告警。
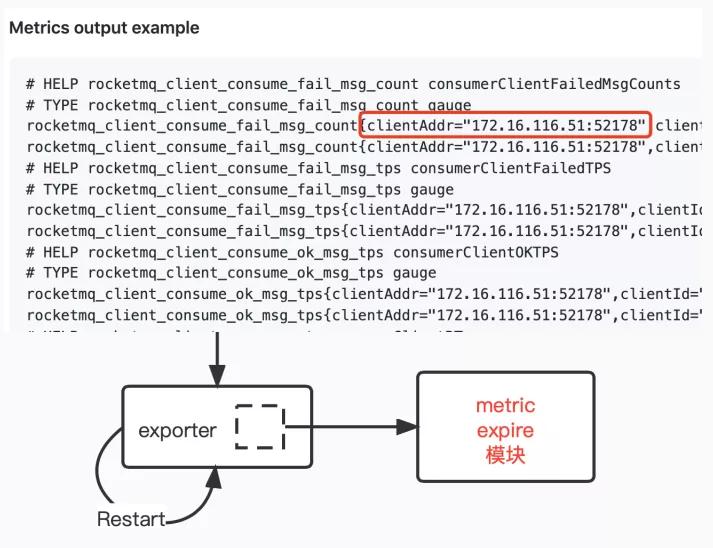
结果:curl一次接口花费的时间降到2s;
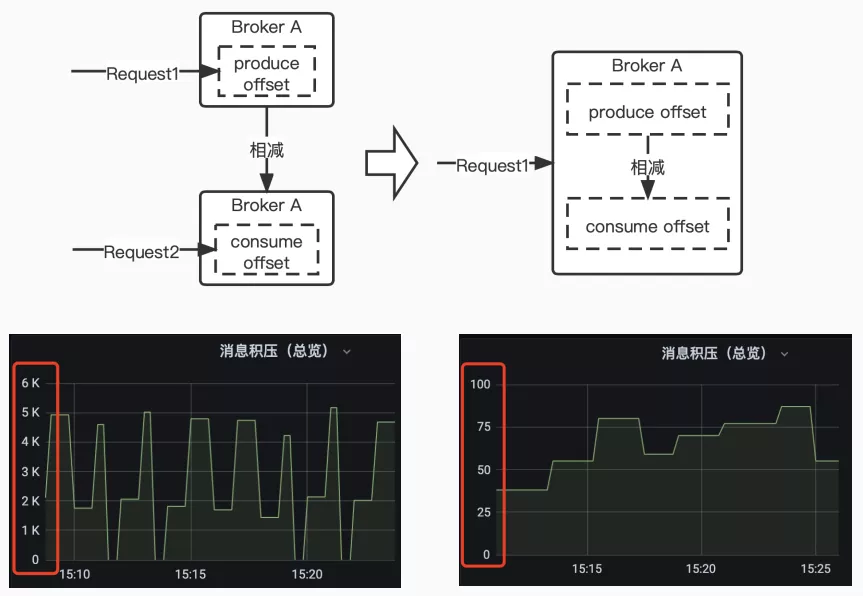
- 问题二:lag指标不准,造成线上误告警
原因:export只提供group维度的 rocketmq_group_diff,没有 broker 维度的,要额外计算;
改造:在 broker 中加入计算逻辑,先将 lag 计算好;
结果:可以从下图中看到,消息积压值从 6K 的抖动恢复成平稳值;
b. 分位线/滑动窗优化
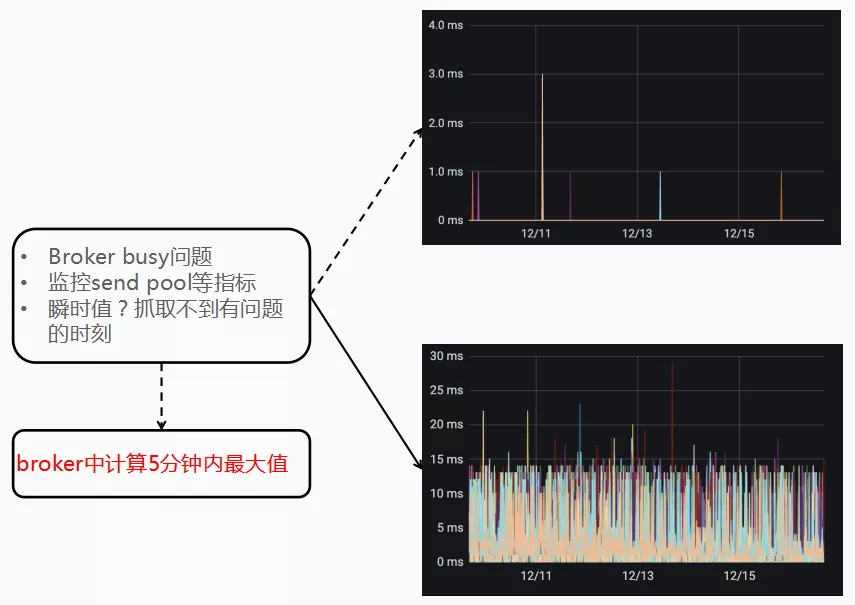
- 问题一:线上时常会遇到 broker busy 的问题,需要对发生的时间点进行监控。虽然 exporter自带 send pool 等指标,但为瞬时值,几乎没有参考意义;
改造:在 broker 中加入计算5分钟内最大值的指标;
结果:
![]()
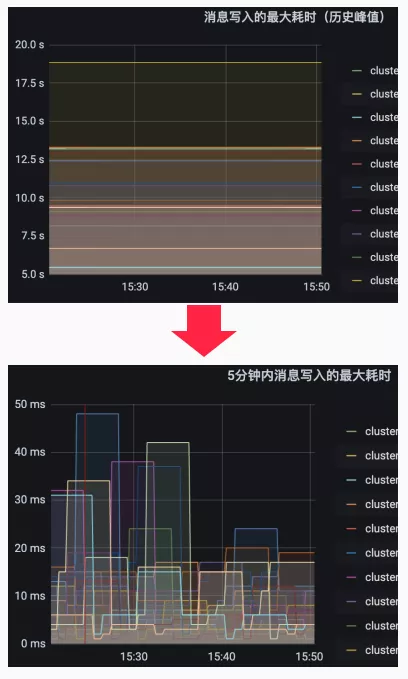
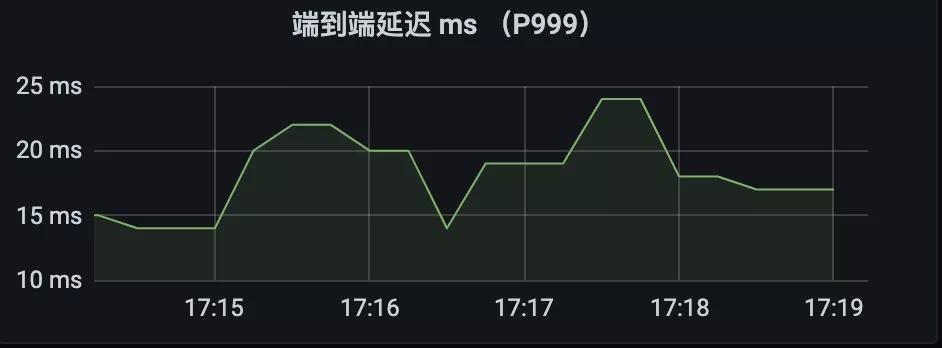
- 问题二:消息写入耗时是历史最大值,参考作用有限;
改造:优化为5分钟内耗时,以及P99/P999等分位值;
结果:得到准确的消息写入耗时。
4、集群可视化:巡检系统
巡检系统与监控系统的区别是:监控系统是反应瞬时的问题,变化很快,需要及时发现和处理,呈现形式相对固定;巡检系统则是长期工作的监督,针对静态环境和配置,变化较少,呈现形式更加自由。
随着治理工作的持续开展,如何确认一个集群达到健康状态?
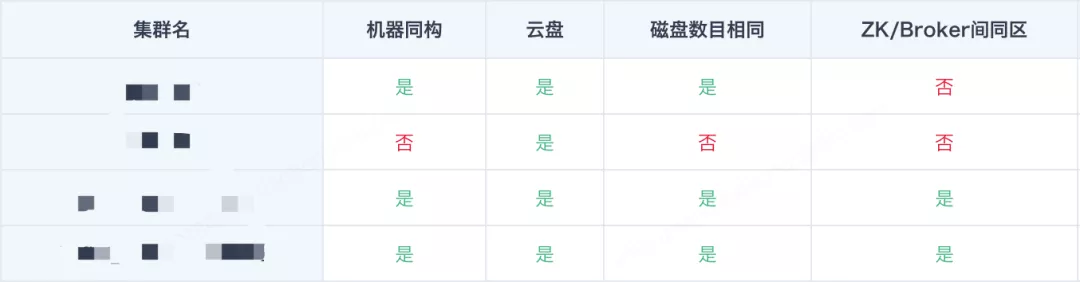
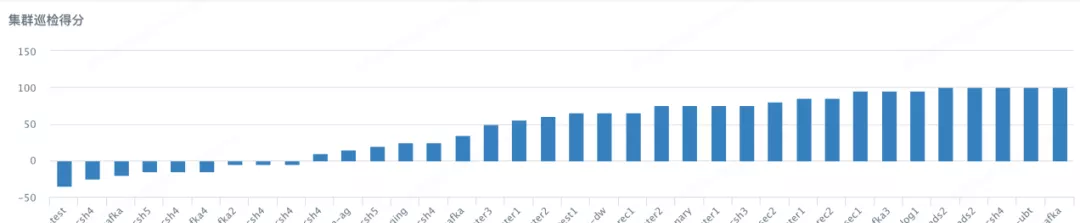
a. 严格按照部署标准部署集群,包括硬件配置、运行参数、可用区等,对所有集群进行定期巡检,产出报表反映集群状况;
b. 共制定核心标准20+项,巡检结果以表格形式呈现,如下图表格。
5、集群可视化:消息对账监控
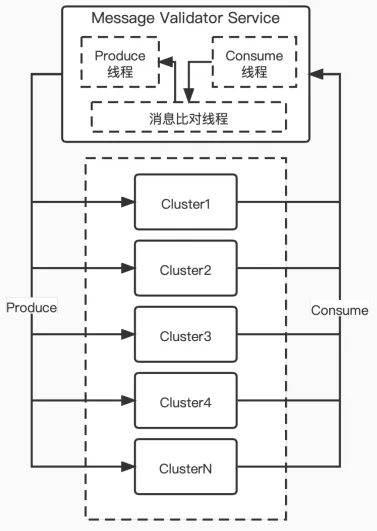
在设计告警时,总会有些没有考虑到的告警项,这里的解决方案是消息对账系统,它可以有效监控消息延迟、丢失和集群健康度。
消息对账系统的优势在于它提供端对端的监控,包罗多项监控的效果,并且它的自驱力可以替没有考虑到的告警项兜底,故障的发现和定位也被独立开。
6、集群可运维:自动化平台
可运维能力的建设是通过自动化来实现的,其根本目的是释放人力。
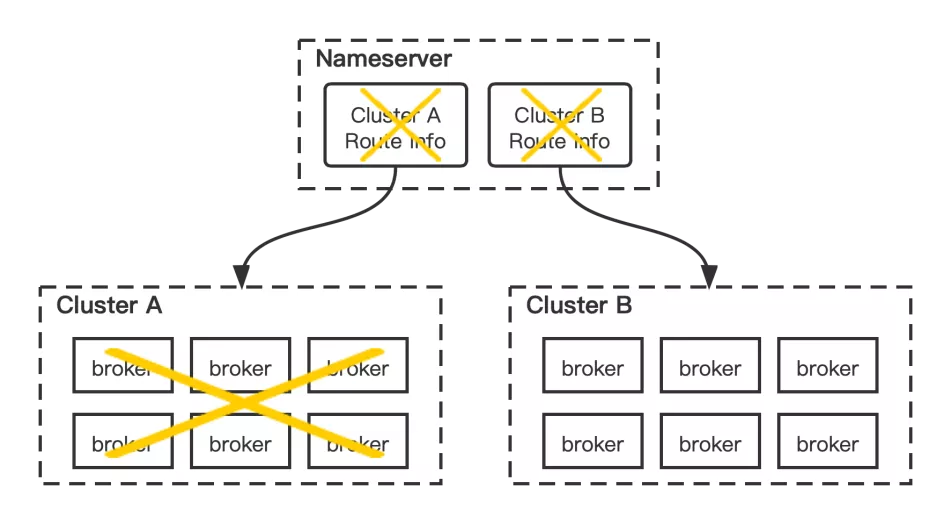
下图展示的是topic迁移工具,从RocketMQ和Kafka两部分改造:
a. RocketMQ
- 修改 nameserver delete 逻辑,支持在 broker 间自动迁移 topic;
- 同时处理 consumer-group,retry/dlq topic;
- 依赖自研管理平台;
b. Kafka
- 基于 reassign 改造,自定义 reassign 算法,减少 partition 搬迁的影响;
- stage 工作流化,每一步自动执行,人工确认下一步操作;
- 集成自研管理平台。
三、未来的探索与规划
近年来,消息领域的全面云原生化逐渐走向深入,比如 RocketMQ 5.0 版本的存算分离设计和 raft 模式,再比如 Kafka3.0 引入了分层设计的方式(tiered storage)和 raft 模式,以及近年来新崛起的 Pulsar 也开始采用云原生架构,在未来都可以针对具体业务需求引入进行功能迭代,发挥组件的最大价值。
本文为阿里云原创内容,未经允许不得转载。

