

智能巡检云监控指标的最佳实践
简介:在真实的企业生产中,对研发和运维的同学都会面临一个十分繁复且艰难的问题,就是对指标的监控和告警。具体我枚举一些特定的问题请对号入座,看看在算力爆炸的时代能否通过算力和算法一起解决!
背景介绍
在真实的企业生产中,对研发和运维的同学都会面临一个十分繁复且艰难的问题,就是对指标的监控和告警。具体我枚举一些特定的问题请对号入座,看看在算力爆炸的时代能否通过算力和算法一起解决!
- 问题一:当一个新业务上线前,运维人员都需要明确服务的部署情况,确定监控对象,以及监控对象的一些可观测性指标,并根据此完成相关日志数据的采集和处理;这里面会涉及到很多日志采集、指标加工等一系列脏活累活;
- 问题二:当确定了监控对象的黄金指标后,往往都需要先适配一组规则:某个接口每分钟的平均请求延时不要超过多少毫秒;单位分钟内的错误请求数量,不要超过多少等等;就如上图所示,从操作系统维度去看,每个个体有上百种形态各异的指标,切指标的形态有不尽相同,试问要多少种规则才能较好的覆盖到上述监控;
- 问题三:随着业务逐步对外提供服务,以及各种运营活动的加推,我们运维监控同学一定会面临两个突出的问题:误报太多和漏报的风险,那么这两个问题都在现阶段都需要人工介入,进行阈值的调整;尤其是漏报的问题,更加需要人工盯屏的形式,设计新的监控规则去覆盖一些事件;

时序存储的介绍
SLS的日志存储引擎在2016年对外发布,目前承接阿里内部以及众多企业的日志数据存储,每天有数十PB的日志类数据写入。其中有很大一部分属于时序类数据或者用来计算时序指标,为了让用户能够一站式完成整个DevOps生命周期的数据接入、清洗、加工、提取、存储、可视化、监控、问题分析等过程,我们专门推出了时序存储的功能,与日志存储一道为大家解决各类机器数据的存储问题。
智能异常分析介绍
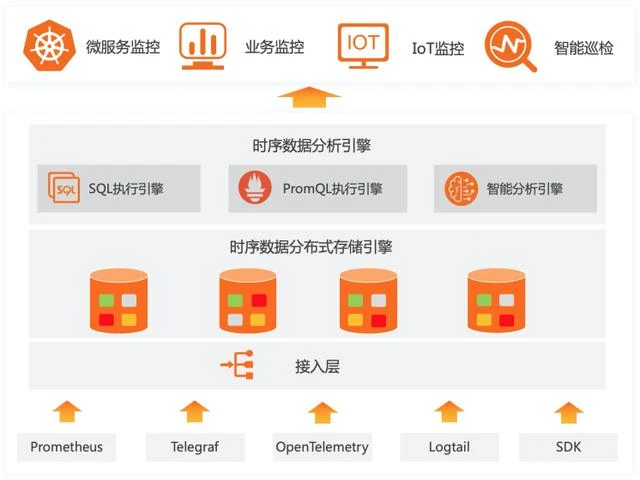
智能异常分析应用是一个可托管、高可用、可扩展的服务,主要提供智能巡检、文本分析和根因诊断三大能力。本文介绍智能异常分析应用的产品架构、功能优势、适用场景、核心名词、使用限制和费用说明等信息。
智能异常分析应用围绕运维场景中的监控指标、程序日志、服务关系等核心要素展开,通过机器学习等手段产生异常事件,通过服务拓扑关联分析时序数据和事件,最终降低企业的运维复杂度,提高服务质量。产品架构图如下所示。
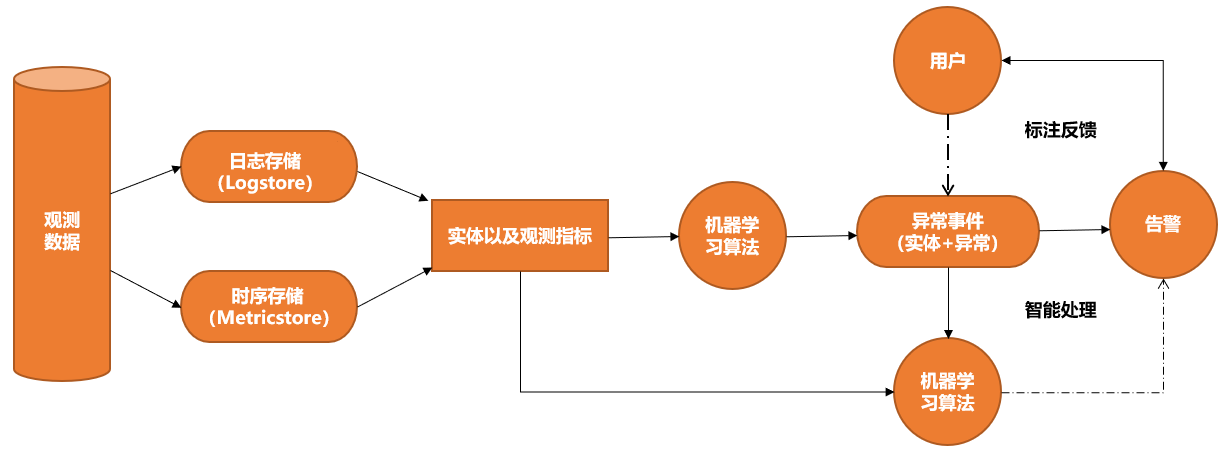
- 观察对象多且每个观察对象的观测维度也多。
- 观测对象没有明确的阈值规则,但需要关注指标的形态。
- 需要对观测对象编写大量的业务规则。
- 处理非结构化的日志数据时,需要对文本日志中的模式进行挖掘。
接下来我们在云监控指标数据场景中使用下
场景实验
智能监控云监控指标
云监控数据接入
通过[官网文档](

我们可以在SLS控制台上查看对应的导入指标,对应各个指标的名称可以参考[这篇文档](
* | select promql_query_range('acs_ecs_dashboard:cpu_system:Average') from metrics limit 100000
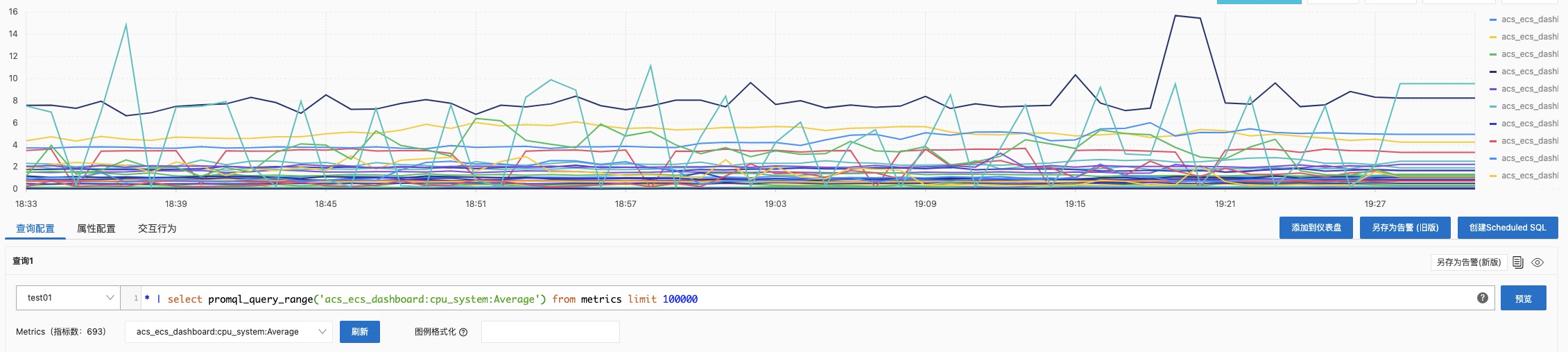
通过【查询页面右上角的查询页面】按钮,可以跳转过去查看下具体的数据格式。

* | select __time_nano__ / 1000000 as time, __name__ as metric_name, element_at(__labels__, 'instanceId') as instanceId from "test01.prom" where __name__ != '' and __name__ = 'acs_ecs_dashboard:cpu_system:Average' order by time, instanceId limit 100000
通过这条SQL语句,我们可以详细的分析出,写入到SLS中的具体的指标(某个监控对象,某个指标在什么时间的值是多少)。上述SQL语句仅仅罗列了在 2021-12-12 19:37~2021-12-12 19:38 这个时间区间的全部监控对象的监控指标,接下来,我们通过简单的改写,仅仅显示某个单独的监控对象在一分钟的数据形态。
* | select date_trunc('second', time) as format, * from ( select __time_nano__ / 1000000 as time, __name__ as metric_name, element_at(__labels__, 'instanceId') as instanceId from "test01.prom" where __name__ != '' and __name__ = 'acs_ecs_dashboard:cpu_system:Average') where instanceId = 'xxxx' order by time limit 100000

这里要在强调一下:SLS侧是是通过OpenAPI去获取云监控的指标数据的,数据导入SLS是有一定的延时的,具体延时大约在3分钟左右,也就是说在 T0 时刻,SLS中的数据只能保证 [T0-300s] 之前的数据时一定按时写入的。这一点在后续的巡检任务配置过程中至关重要。
我们通过PromQL在简化下上边的描述,我们继续使用对应的指标 "acs_ecs_dashboard:cpu_system:Average",通过如下的语句可以得到预期的结果,这已经距离我们创建巡检任务已经很接近了。
* | select promql_query_range('avg({__name__=~"acs_ecs_dashboard:cpu_system:Average"}) by (instanceId, __name__) ', '15s') from metrics limit 1000000

通过如下的Query可以大概知道在云监控关于ECS提供了多少监控指标:
* | select COUNT(*) as num from ( select DISTINCT __name__ from "test01.prom" where __name__ != '' and __name__ like '%acs_ecs_dashboard%' limit 10000 )
得到的结果是295个结果,但是我们没有比较全部都进行巡检配置,因此第一步就是要根据[指标说明文档](
- acs_ecs_dashboard:CPUUtilization:Average
- acs_ecs_dashboard:DiskReadBPS:Average
- acs_ecs_dashboard:DiskReadIOPS:Average
- acs_ecs_dashboard:DiskWriteBPS:Average
- acs_ecs_dashboard:DiskWriteIOPS:Average
- acs_ecs_dashboard:InternetIn:Average
- acs_ecs_dashboard:InternetInRate:Average
- acs_ecs_dashboard:InternetOut:Average
- acs_ecs_dashboard:InternetOutRate:Average
- acs_ecs_dashboard:InternetOutRate_Percent:Average
- acs_ecs_dashboard:IntranetIn:Average
- acs_ecs_dashboard:IntranetInRate:Average
- acs_ecs_dashboard:IntranetOut:Average
- acs_ecs_dashboard:IntranetOutRate:Average
- acs_ecs_dashboard:cpu_idle:Average
- acs_ecs_dashboard:cpu_other:Average
- acs_ecs_dashboard:cpu_system:Average
- acs_ecs_dashboard:cpu_total:Average
- acs_ecs_dashboard:cpu_user:Average
- acs_ecs_dashboard:cpu_wait:Average
- acs_ecs_dashboard:disk_readbytes:Average
- acs_ecs_dashboard:disk_readiops:Average
- acs_ecs_dashboard:disk_writebytes:Average
- acs_ecs_dashboard:disk_writeiops:Average
- acs_ecs_dashboard:load_1m:Average
- acs_ecs_dashboard:load_5m:Average
- acs_ecs_dashboard:memory_actualusedspace:Average
- acs_ecs_dashboard:memory_freespace:Average
- acs_ecs_dashboard:memory_freeutilization:Average
- acs_ecs_dashboard:memory_totalspace:Average
- acs_ecs_dashboard:memory_usedspace:Average
- acs_ecs_dashboard:memory_usedutilization:Average
- acs_ecs_dashboard:net_tcpconnection:Average
- acs_ecs_dashboard:networkin_errorpackages:Average
- acs_ecs_dashboard:networkin_packages:Average
- acs_ecs_dashboard:networkin_rate:Average
- acs_ecs_dashboard:networkout_errorpackages:Average
- acs_ecs_dashboard:networkout_packages:Average
- acs_ecs_dashboard:networkout_rate:Average
根据上述配置,生成对应的查询PromQL如下:
* | select promql_query_range('avg({__name__=~"acs_ecs_dashboard:CPUUtilization:Average|acs_ecs_dashboard:DiskReadBPS:Average|acs_ecs_dashboard:DiskReadIOPS:Average|acs_ecs_dashboard:DiskWriteBPS:Average|acs_ecs_dashboard:DiskWriteIOPS:Average|acs_ecs_dashboard:InternetIn:Average|acs_ecs_dashboard:InternetInRate:Average|acs_ecs_dashboard:InternetOut:Average|acs_ecs_dashboard:InternetOutRate:Average|acs_ecs_dashboard:InternetOutRate_Percent:Average|acs_ecs_dashboard:IntranetIn:Average|acs_ecs_dashboard:IntranetInRate:Average|acs_ecs_dashboard:IntranetOut:Average|acs_ecs_dashboard:IntranetOutRate:Average|acs_ecs_dashboard:cpu_idle:Average|acs_ecs_dashboard:cpu_other:Average|acs_ecs_dashboard:cpu_system:Average|acs_ecs_dashboard:cpu_total:Average|acs_ecs_dashboard:cpu_user:Average|acs_ecs_dashboard:cpu_wait:Average|acs_ecs_dashboard:disk_readbytes:Average|acs_ecs_dashboard:disk_readiops:Average|acs_ecs_dashboard:disk_writebytes:Average|acs_ecs_dashboard:disk_writeiops:Average|acs_ecs_dashboard:load_1m:Average|acs_ecs_dashboard:load_5m:Average|acs_ecs_dashboard:memory_actualusedspace:Average|acs_ecs_dashboard:memory_freespace:Average|acs_ecs_dashboard:memory_freeutilization:Average|acs_ecs_dashboard:memory_totalspace:Average|acs_ecs_dashboard:memory_usedspace:Average|acs_ecs_dashboard:memory_usedutilization:Average|acs_ecs_dashboard:net_tcpconnection:Average|acs_ecs_dashboard:networkin_errorpackages:Average|acs_ecs_dashboard:networkin_packages:Average|acs_ecs_dashboard:networkin_rate:Average|acs_ecs_dashboard:networkout_errorpackages:Average|acs_ecs_dashboard:networkout_packages:Average|acs_ecs_dashboard:networkout_rate:Average"}) by (instanceId, __name__) ', '1m') from metrics limit 1000000
对于一般场景而言,我们可以在简化一些指标,这里直接提供对应的PromQL如下:
* | select promql_query_range('avg({__name__=~"acs_ecs_dashboard:CPUUtilization:Average|acs_ecs_dashboard:DiskReadBPS:Average|acs_ecs_dashboard:DiskReadIOPS:Average|acs_ecs_dashboard:DiskWriteBPS:Average|acs_ecs_dashboard:DiskWriteIOPS:Average|acs_ecs_dashboard:InternetIn:Average|acs_ecs_dashboard:InternetInRate:Average|acs_ecs_dashboard:InternetOut:Average|acs_ecs_dashboard:InternetOutRate:Average|acs_ecs_dashboard:InternetOutRate_Percent:Average|acs_ecs_dashboard:IntranetOut:Average|acs_ecs_dashboard:IntranetOutRate:Average|acs_ecs_dashboard:cpu_idle:Average|acs_ecs_dashboard:cpu_other:Average|acs_ecs_dashboard:cpu_system:Average|acs_ecs_dashboard:cpu_total:Average|acs_ecs_dashboard:cpu_user:Average|acs_ecs_dashboard:cpu_wait:Average|acs_ecs_dashboard:disk_readbytes:Average|acs_ecs_dashboard:disk_readiops:Average|acs_ecs_dashboard:disk_writebytes:Average|acs_ecs_dashboard:disk_writeiops:Average|acs_ecs_dashboard:load_1m:Average|acs_ecs_dashboard:load_5m:Average|acs_ecs_dashboard:memory_freespace:Average|acs_ecs_dashboard:memory_freeutilization:Average|acs_ecs_dashboard:memory_totalspace:Average|acs_ecs_dashboard:memory_usedspace:Average|acs_ecs_dashboard:memory_usedutilization:Average"}) by (instanceId, __name__) ', '1m') from metrics limit 1000000
配置智能巡检任务

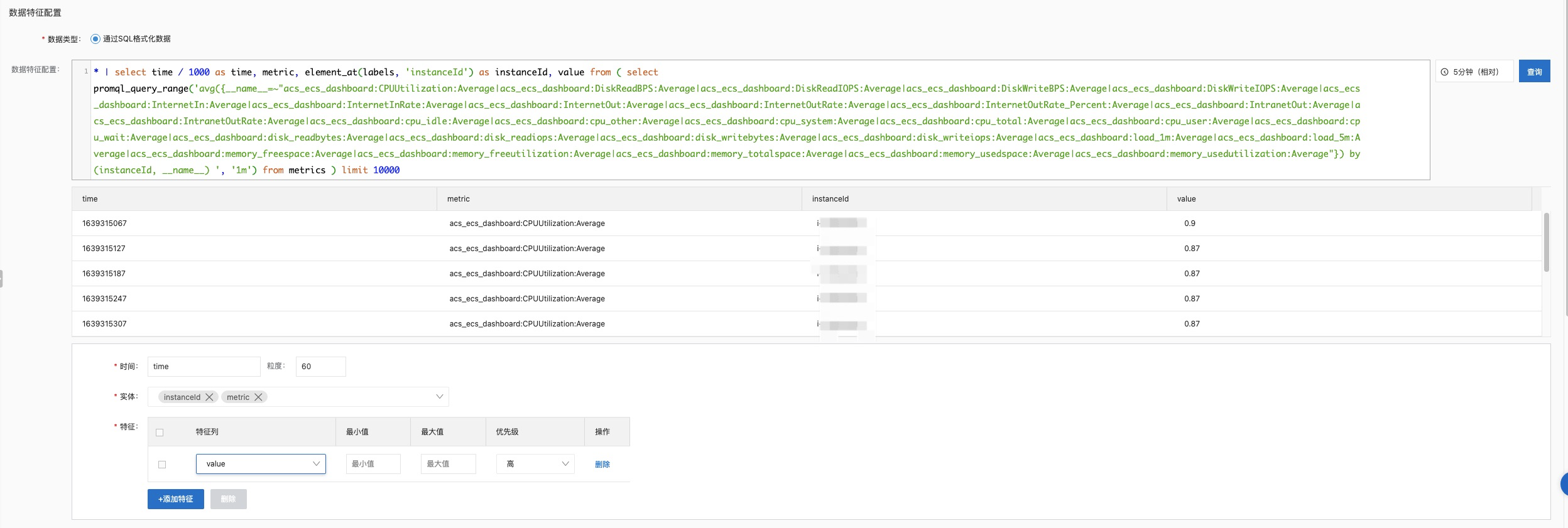
- 通过SQL转写一下,并对time字段进行处理,因为在巡检中,接受的时间的单位是秒,而PromQL得到的结果中time是毫秒;
- 通过element_at算子,提取出对应的实例ID(instanceId);
- 目前在配置粒度时,最小只支持60秒;
* | select time / 1000 as time, metric, element_at(labels, 'instanceId') as instanceId, value from ( select promql_query_range('avg({__name__=~"acs_ecs_dashboard:CPUUtilization:Average|acs_ecs_dashboard:DiskReadBPS:Average|acs_ecs_dashboard:DiskReadIOPS:Average|acs_ecs_dashboard:DiskWriteBPS:Average|acs_ecs_dashboard:DiskWriteIOPS:Average|acs_ecs_dashboard:InternetIn:Average|acs_ecs_dashboard:InternetInRate:Average|acs_ecs_dashboard:InternetOut:Average|acs_ecs_dashboard:InternetOutRate:Average|acs_ecs_dashboard:InternetOutRate_Percent:Average|acs_ecs_dashboard:IntranetOut:Average|acs_ecs_dashboard:IntranetOutRate:Average|acs_ecs_dashboard:cpu_idle:Average|acs_ecs_dashboard:cpu_other:Average|acs_ecs_dashboard:cpu_system:Average|acs_ecs_dashboard:cpu_total:Average|acs_ecs_dashboard:cpu_user:Average|acs_ecs_dashboard:cpu_wait:Average|acs_ecs_dashboard:disk_readbytes:Average|acs_ecs_dashboard:disk_readiops:Average|acs_ecs_dashboard:disk_writebytes:Average|acs_ecs_dashboard:disk_writeiops:Average|acs_ecs_dashboard:load_1m:Average|acs_ecs_dashboard:load_5m:Average|acs_ecs_dashboard:memory_freespace:Average|acs_ecs_dashboard:memory_freeutilization:Average|acs_ecs_dashboard:memory_totalspace:Average|acs_ecs_dashboard:memory_usedspace:Average|acs_ecs_dashboard:memory_usedutilization:Average"}) by (instanceId, __name__) ', '1m') from metrics ) limit 10000
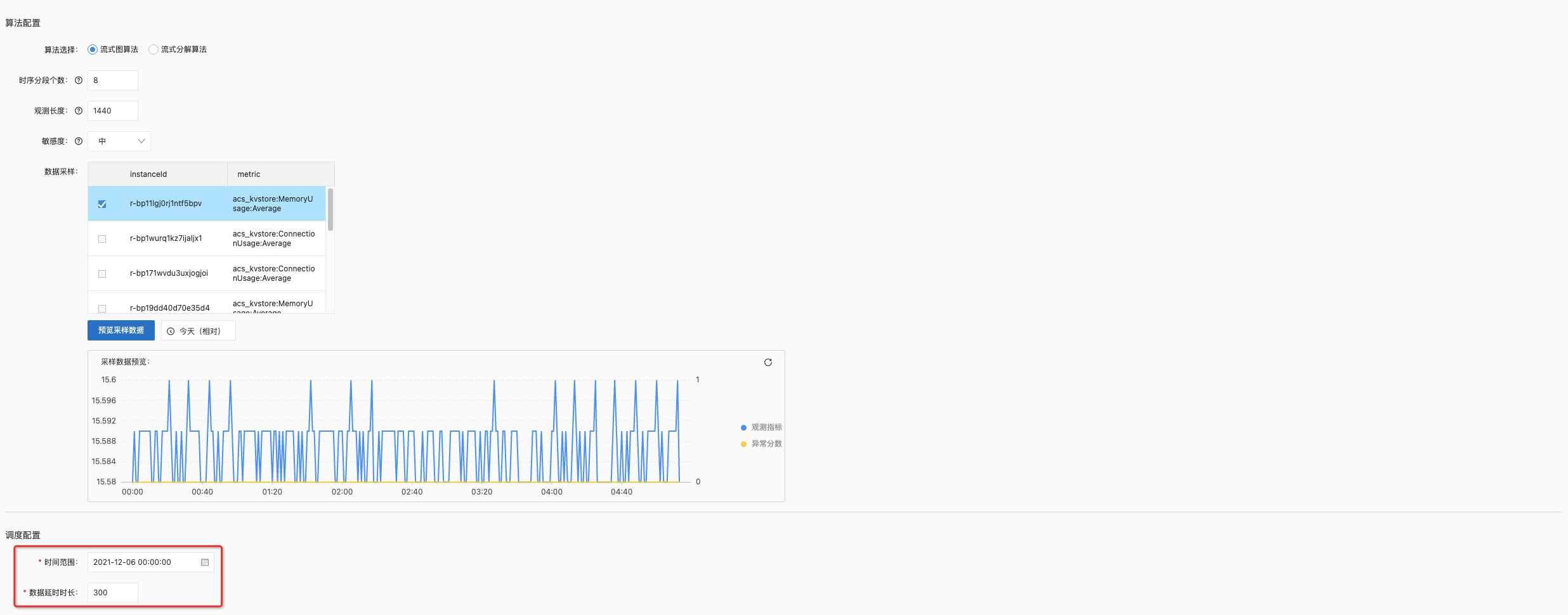
【数据延时时长】- 由于我们处理的是通过导入服务导入的云监控的数据,一般整体的链路延时最多不会超过300s,因此这里要选择300秒,防治观测丢点。
配置告警
通过SLS中提供的[新版告警](

建议您使用普通模式却设置告警,在【行动策略】这一栏中,选择我们内置的行动策略(sls.app.ml.builtin),这里我们已经配置好了,具体可以在告警配置中进行查看,查看地址具体:
原文链接
本文为阿里云原创内容,未经允许不得转载。
