
如何使用 Kubernetes 监测定位慢调用
简介:本次课程主要分为三大部分,首先将介绍慢调用的危害以及常见的原因;其次介绍慢调用的分析方法以及最佳实践;最后将通过几个案例来去演示一下慢调用的分析过程。
作者:李煌东
大家好,我是阿里云的李煌东。今天我为大家分享 Kubernetes 监测公开课第四节,如何使用 Kubernetes 监测定位慢调用。今天的课程主要分为三大部分,首先我会介绍一下慢调用的危害以及常见的原因;其次我会介绍慢调用的分析方法以及最佳实践;最后通过几个案例来去演示一下慢调用的分析过程。
慢调用危害及常见原因
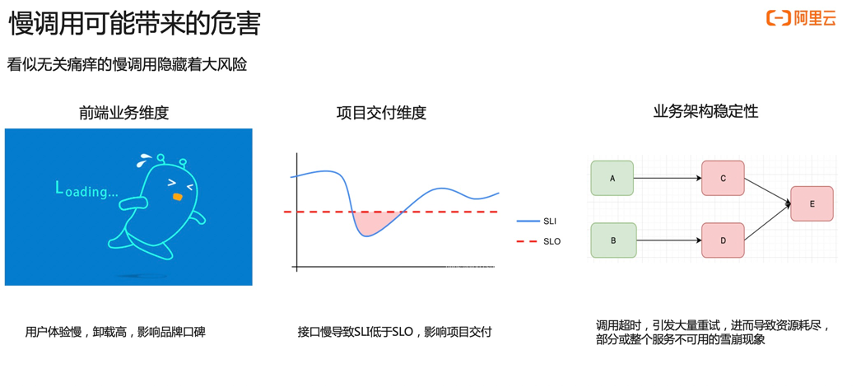
- 前端业务维度:首先慢调用可能会引起前端加载慢的问题,前端加载慢可能会进一步导致应用卸载率高,进而影响品牌的口碑。
- 项目交付的维度:由于接口慢导致达不到 SLO,进而导致项目延期。
- 业务架构稳定性:当接口调用慢时,非常容易引起超时,当其他业务服务都依赖这个接口,那么就会引发大量重试,进而导致资源耗尽,最终导致部分服务或者整个服务不可用的雪崩的现象。
所以,看似一个无关痛痒的慢调用可能隐藏着巨大风险,我们应该引起警惕。对慢调用最好都不要去忽视它,应该尽可能去分析其背后的原因,从而进行风险控制。
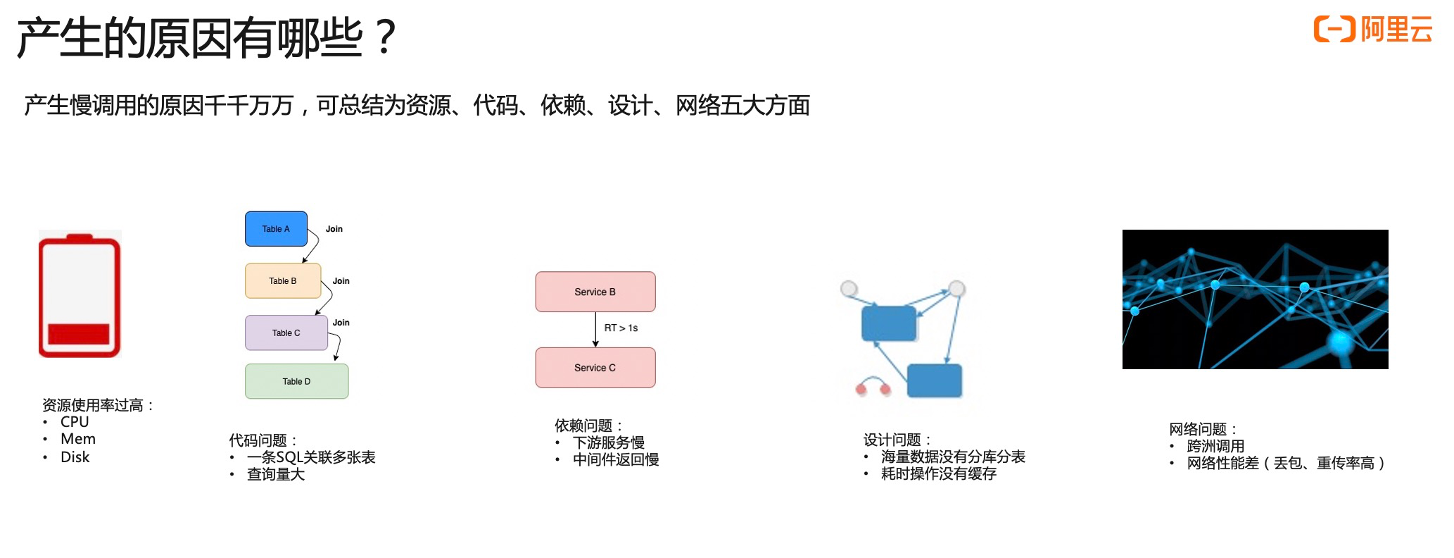
- 第一个是资源使用率过高问题,比如说 CPU 内存、磁盘、网卡等等。当这些使用率过高的时候,非常容易引起服务慢。
- 第二个是代码设计的问题,通常来说如果 SQL 它关联了很多表,做了很多表,那么会非常影响 SQL 执行的性能。
- 第三个是依赖问题,服务自身没有问题,但调用下游服务时下游返回慢,自身服务处于等待状态,也会导致服务慢调用的情况。
- 第四个是设计问题,比如说海量数据的表非常大,亿级别数据查询没有分库分表,那么就会非常容易引起慢查询。类似的情况还有耗时的操作没有做缓存。
- 第五个是网络方面问题,比如说跨洲调用,跨洲调用是物理距离太大了,导致往返时间比较长,进而导致慢调用。或者两点之间的网络性能可能比较差。比如说有丢包重传率,重传率高的问题。
今天我们的例子围绕这五个方面,我们一起来看一下。
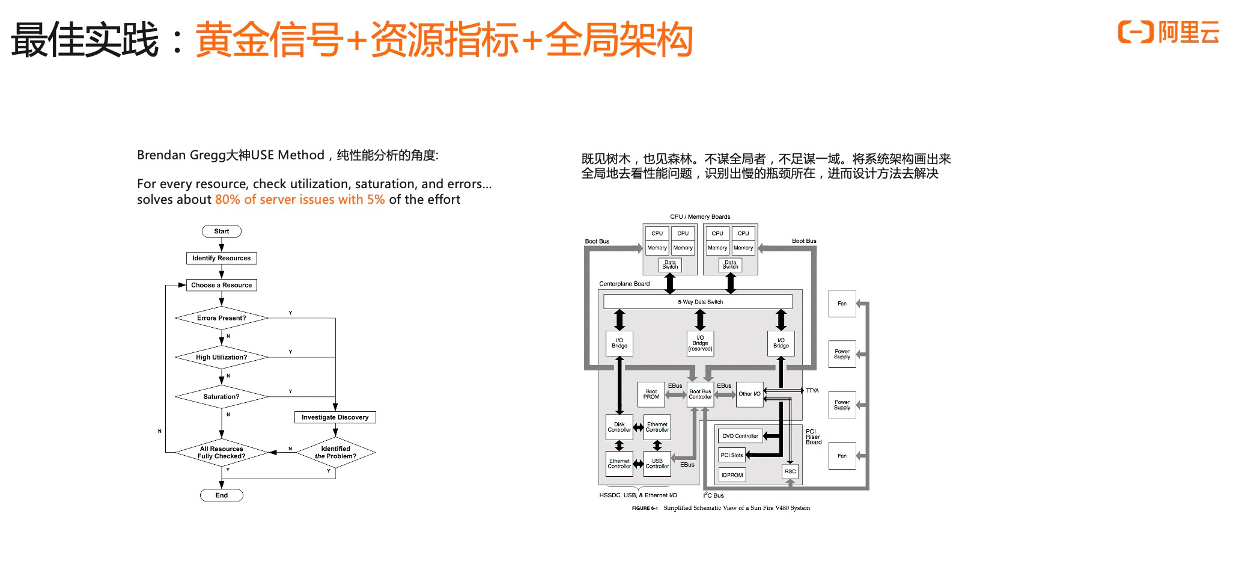
定位慢调用一般来说有什么样的步骤,或者说有什么样的最佳实践呢?我这里总结的为三个方面:黄金信号 + 资源指标 + 全局架构。

- 延时--用来描述系统执行请求花费的时间。常见指标包括平均响应时间,P90/P95/P99 这些分位数,这些指标能够很好的表征这个系统对外响应的快还是慢,是比较直观的。
- 流量--用来表征服务繁忙程度,典型的指标有 QPS、TPS。
- 错误--也就是我们常见的类似于协议里 HTTP 协议里面的 500、400 这些,通常如果错误很多的话,说明可能已经出现问题了。
- 饱和度--就是资源水位,通常来说接近饱和的服务比较容易出现问题,比如说磁盘满了,导致日志没办法写入,进而导致服务响应。典型的那些资源有 CPU、 内存、磁盘、队列长度、连接数等等。
除了黄金信号,我们还需要关注一个资源指标。著名的性能分析大神 Brandan Gregg ,在他的性能分析方法论文章中提到一个 USE 方法。USE 方法是从资源角度进行分析,它是对于每一个资源去检查 utilization(使用率),saturation (饱和度),error(错误) ,合起来就是 USE 了,检查这三项基本上能够解决 80% 的服务问题,而你只需要花费 5% 的时间。
慢调用最佳实践
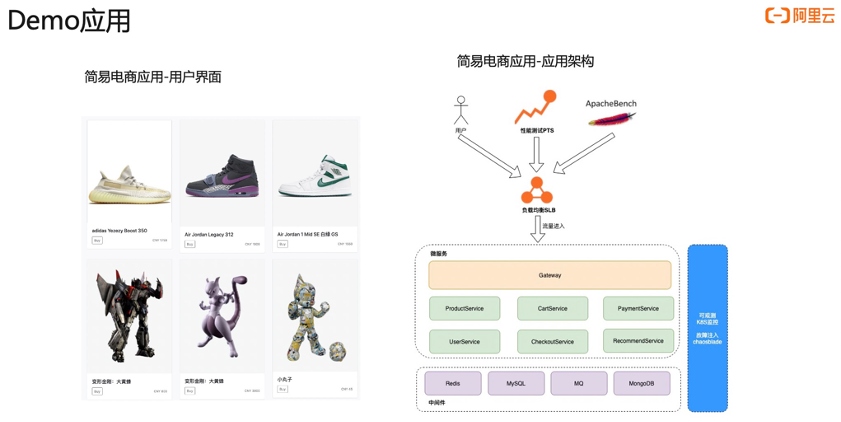
接下来我会讲三个案例,第一个是节点 CPU 打满问题,这也是典型的资源问题导致的服务慢的问题,即服务自身的资源导致的问题。第二个是依赖的服务中间件慢调用的问题。第三个是网络性能差。第一个案例是判断服务自身有没有问题;第二个案例是判断下游服务的问题;第三个就是判断自身跟服务之间的网络性能问题。
我们以一个电商应用举例。首先流量入口是阿里云 SLB,然后流量进入到微服务体系中,微服务里面我们通过网关去接收所有流量,然后网关会把流量打到对应的内部服务里面,比如说 ProductService、CartService、 PaymentService 这些。下面我们依赖了一些中间件,比如说 Redis 、MySQL 等等,这整个架构我们会使用阿里云的 ARMS 的 Kubernetes 监测产品来去监测整个架构。故障注入方面,我们会通过 chaosblade 去注入诸如 CPU 打满、网络异常等不同类型的异常。
案例一:节点 CPU 打满问题
节点 CPU 打满会带来什么样的问题呢?节点 CPU 打满之后,上面的 Pod 可能没办法申请到更多 CPU,导致里面的线程都处于等待调度的状态,进而导致慢调用。除了节点上面,我们这除了 CPU 之外,还有一些像磁盘、Memory 等等资源。
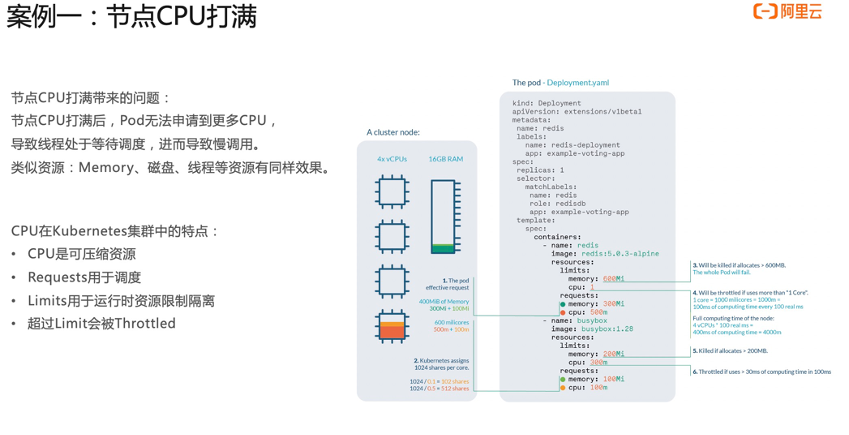
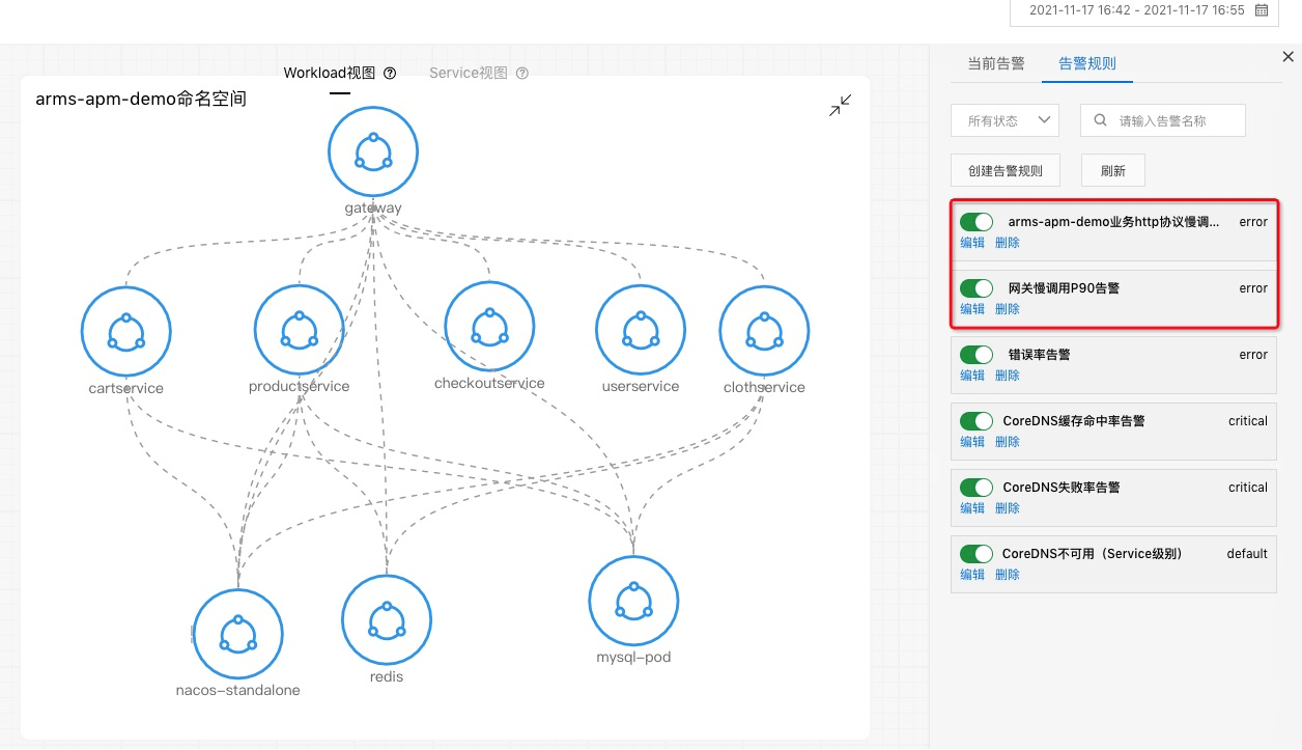
在正式开始前,我们通过拓扑图对关键链路进行识别,在上面配置一些告警。比如说网关及支付链路,我们会配置平均响应时间 P90 以及慢调用等告警。然后配置完之后,我这边会注入一个节点 CPU 打满这么一个故障。那这个节点选的是网关的节点,大概等待五分钟之后,我们就可以收到告警,就是第二步里面的那个验证告警的有效性。
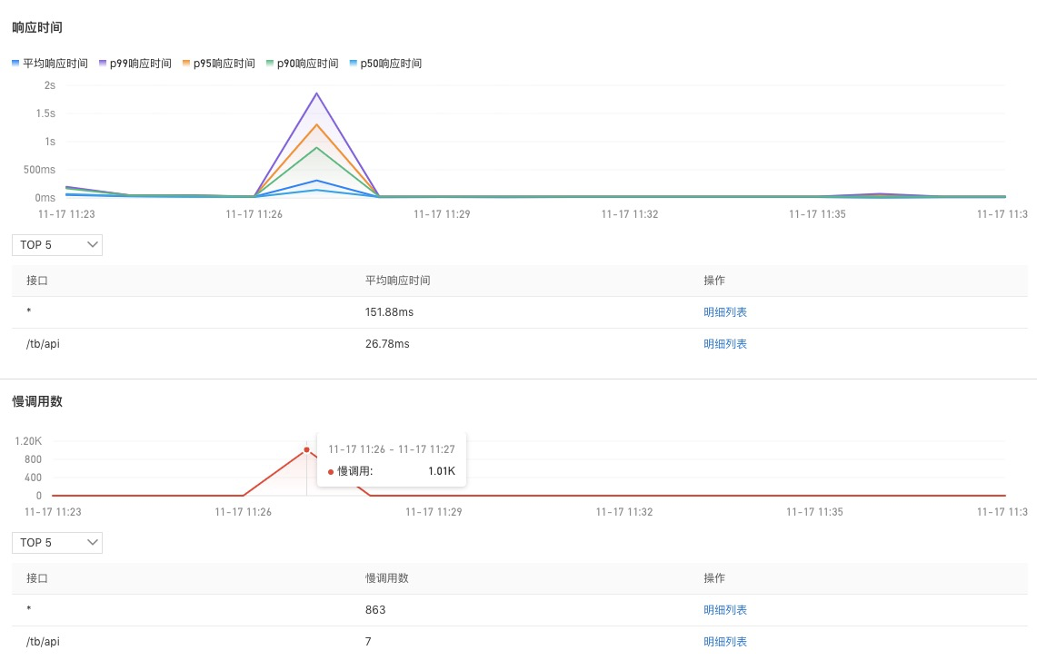
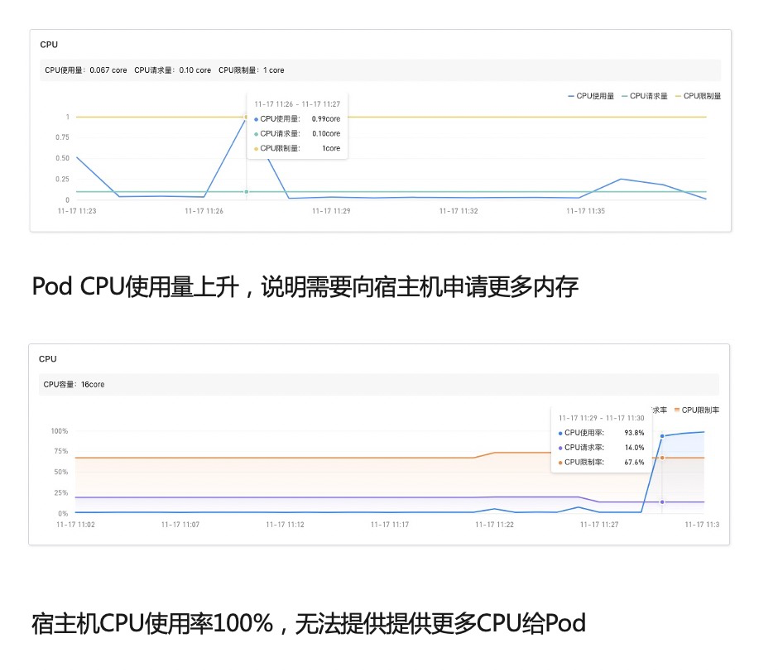
效果如下:注入 CPU 慢故障时,慢调用会上升,上升完成之后会触发到弹性伸缩,那就是 CPU 的使用率超过阈值了,如 70%。那么,它就会自动扩出一些副本去分担这些流量,我们可以看到慢调用数逐步下降直到消失,说明我们的那个弹性伸缩起到作用了。

案例二:依赖的服务中间件慢调用的问题
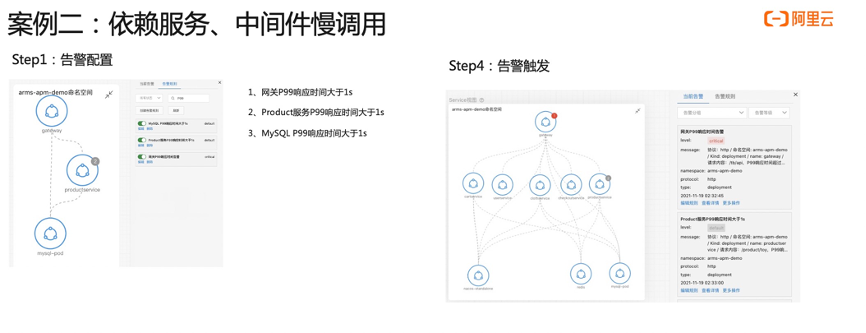
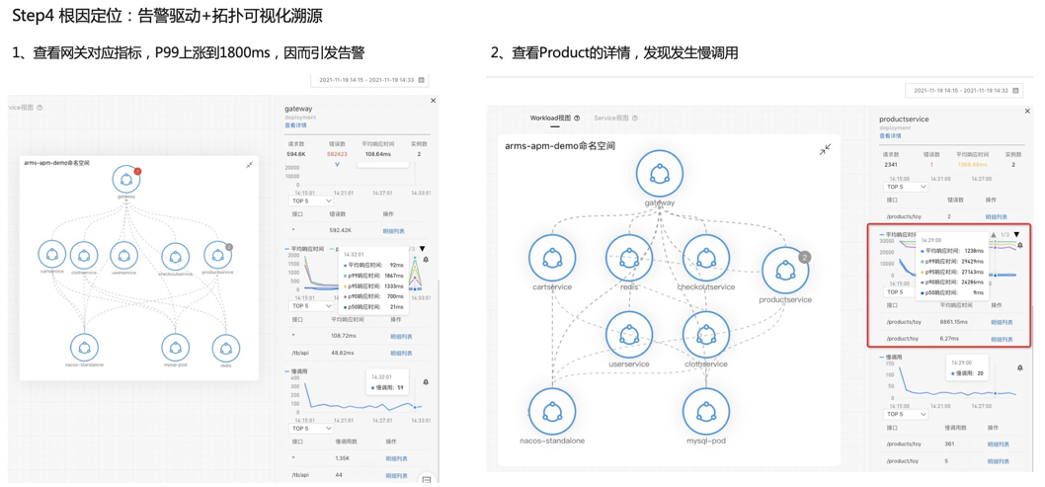
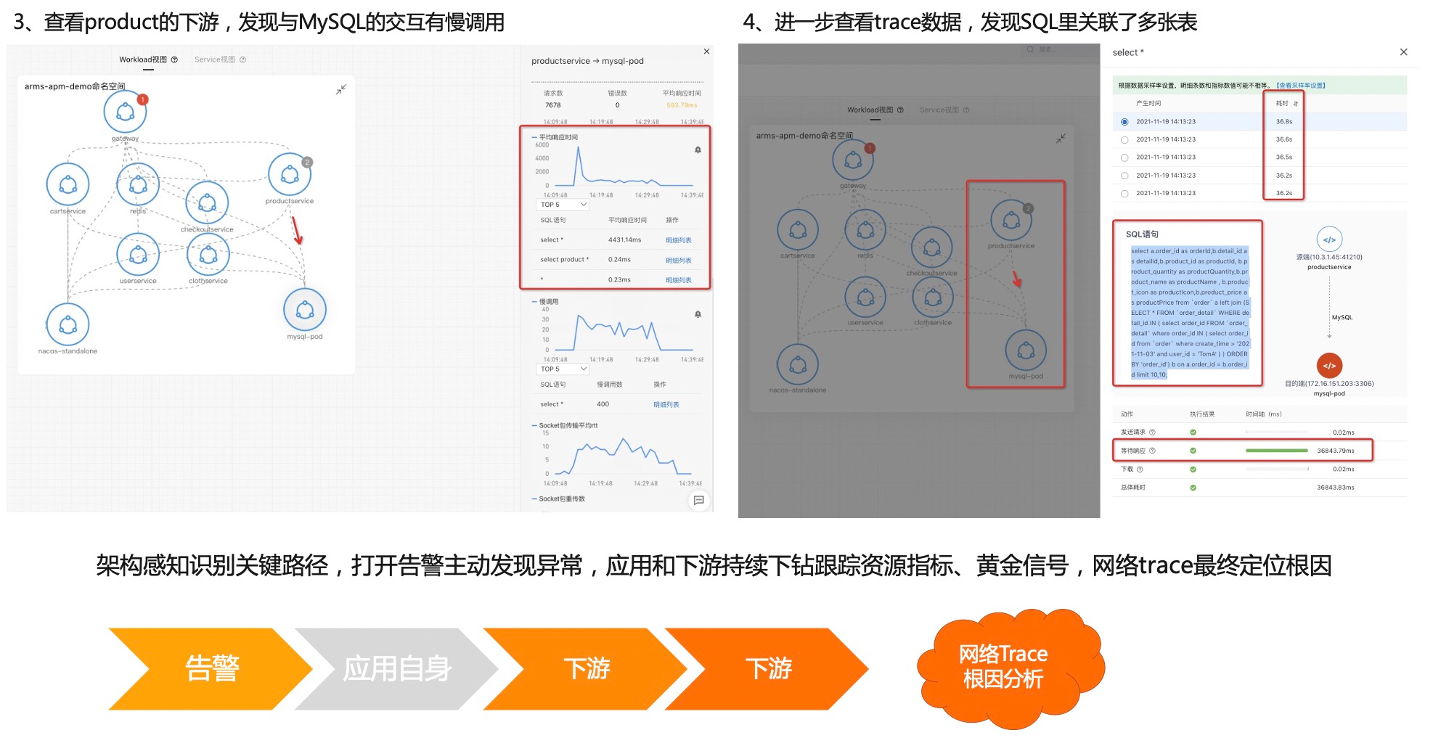
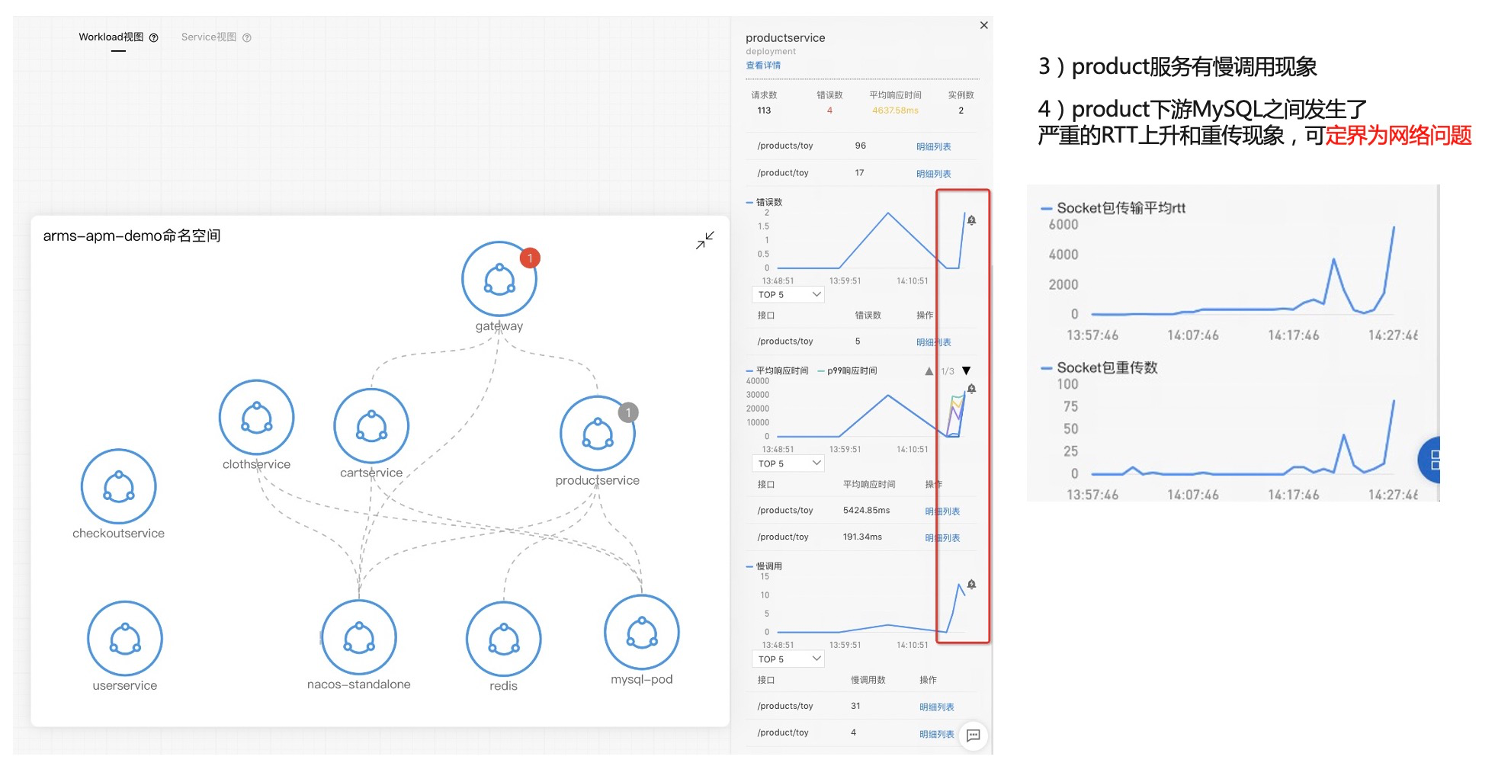
接下来我们看第二个案例。首先介绍一下准备工作,左边这边图我们可以看到网关进来掉了两个下游服务,一个是 MySQL ,一个是 ProductService,所以在网关上直接配置一个大于一秒的告警,平均响应时间 P99 大于一秒的告警。第二步我们看这个 Product 也是在关键链路上面,我给它配一个 P99 大于一秒的告警,第三个是 MySQL ,也配一个大于一秒的告警,配完之后,我会在 Product 这个服务上面去注入一个 MySQL 慢查询的故障,大概等到两分钟之后,我们就可以看到陆续告警就触发出来了,网关跟 Product 上面都有一个红点跟一个灰色的点,这一点其实就是报出来的故障,报出的告警事件,Kubernetes 监测会把这个告警事件通过命名空间应用自动的 match 到这个节点上面,所以能够一眼的看出哪些服务、哪些应用是异常的,这样能够快速定位出问题所在。我们现在收到告警了之后,下一步去进行一个根因定位。
案例三:网络性能差
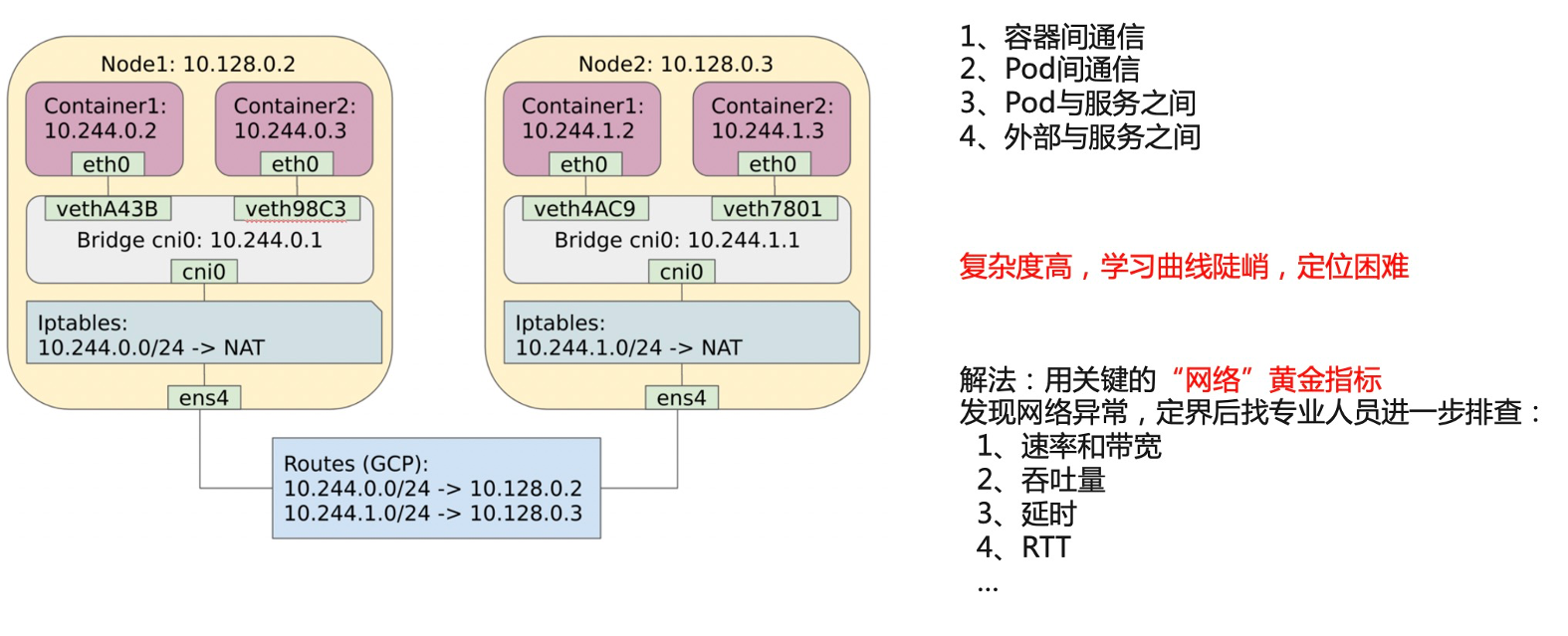
接下来我们讲最后一个例子就是网络性能差,Kubernetes 的网络架构是比较复杂的,容器之间的通信、Pod 之间的通信、Pod 与服务之间通信、外部与服务之间的通信等等。所以复杂度是比较高的,学习的曲线也比较陡峭,这给定位问题带来一定困难。那么,我们怎么去应对这种情况呢?如果采用关键网络环境指标去发现网络异常,有哪些关键环境指标呢?首先一个是速率跟带宽,第二个是吞吐量,第三个是延时,第四个是 RTT。

1、 通过默认告警主动发现异常,默认告警模板涵盖 RED,常见资源类型指标。除了默认下发的告警规则,用户还可以基于模板定制化配置。
2、 通过黄金信号和资源指标发现、定位异常,同时 Trace 配合下钻定位根因。
3、 通过拓扑图做上下游分析、依赖分析、架构感知,有利于从全局视角审视架构,从而得到最优解,做到持续改善,构建更稳定的系统。
原文链接
本文为阿里云原创内容,未经允许不得转载。

