

系统架构面临的三大挑战,看 Kubernetes 监控如何解决?
简介: 随着 Kubernetes 的不断实践落地,我们经常会遇到负载均衡、集群调度、水平扩展等问题。归根到底,这些问题背后都暴露出流量分布不均的问题。那么,我们该如何发现资源使用,解决流量分布不均问题呢?今天,我们就借助三个具体场景聊聊这一问题以及相应的解决方案。
作者|炎寻
大家好,我是阿里云云原生应用平台的炎寻,很高兴能与大家继续分享 Kubernetes 监控系列公开课。前两期公开课我们讲到了
如何使用 Kubernetes 监控的拓扑来探索应用架构,使用产品采集的监控数据配置告警来发现服务性能问题。今天我们将进行第三讲《使用 Kubernetes 监控发现资源使用,流量分布不均匀的问题》,大家可以钉钉搜索钉群 31588365,加入 Kubernetes 监控答疑群进行交流。
随着 Kubernetes 的不断实践落地,我们经常会遇到越来越多问题,诸如负载均衡、集群调度、水平扩展等问题。归根到底,这些问题背后都暴露出流量分布不均的问题。那么,我们该如何发现资源使用,解决流量分布不均问题呢?今天,我们就借助三个具体场景聊聊这一问题以及相应的解决方案。
系统架构面临的挑战一:负载均衡
- 应用服务器处理的请求是否均匀?
- 应用服务器对中间件服务实例的访问流量是否均匀?
- 数据库各个分库分表实例读写流量是否均匀?
- …
我们在实际工作实践中会遇到的典型场景就是负载不均衡,线上的流量转发策略或者流量转发组件自身有问题,导致应用服务各个实例接收到的请求量不均衡,部分实例处理的流量显著高于其他节点,导致这部分实例的性能相对于其他实例来说显著恶化,那么路由到这部分实例上的请求无法得到及时的响应,造成系统整体的性能和稳定性降低。

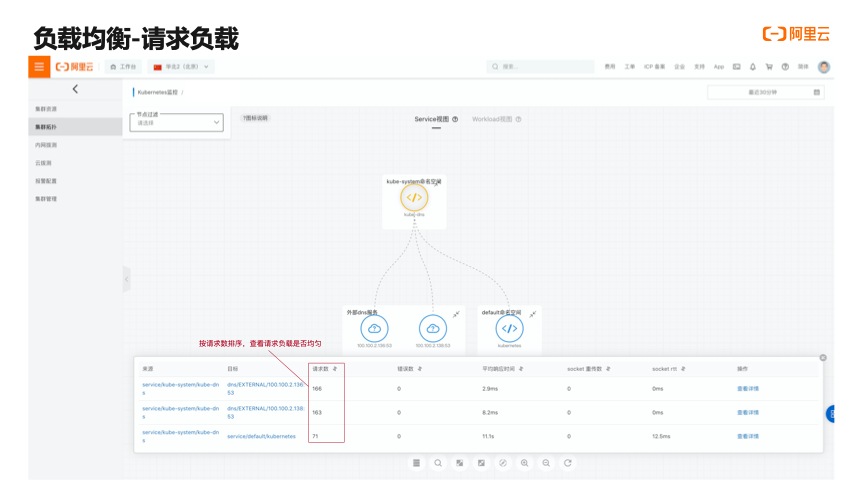
那么,我们如何快速发现问题、解决问题呢? 针对这一问题,我们可以从服务负载、请求负载这两个方面对客户端、服务端进行问题发现,判断各个组件实例服务负载和对外请求负载是否均衡。
(1)服务端负载

(2)客户端负载
对于客户端负载均衡问题排查,Kubernetes 监控提供集群拓扑功能,对于任意特定的 Service,Deployment,DaemonSet,StatefulSet,我们都可以查看其关联的拓扑,当选定关联关系之后,点击表格化会列出所有与问题实体关联的网络拓扑,表格每一项都是应用服务节点对外请求的拓扑关系,在表格中我们会展示每一对拓扑关系在选择时间段内的请求数聚合值和请求数时序,通过对请求数一列进行排序,可以清楚地看到特定节点作为客户端对特定的服务端访问是否流量均匀。
系统架构面临的挑战二:集群调度
在 Kubernetes 集群部署场景下,将 Pod 分发到某个节点的过程称之为调度,对于每个 Pod 来说,其调度过程包含了“根据过滤条件找候选节点”以及“找最好的节点”两个步骤,“根据过滤条件找候选节点”除了根据 Pod 和 node 的污点,忍受关系来过滤节点,还有一点非常重要的就是根据资源预留的量来过滤,比如节点的 CPU 只有 1 核的预留,那么对于一个请求 2 核的 Pod 来说该节点将被过滤。“找最好的节点”除了根据 Pod 和 node 的亲和性来选择,一般是在过滤出来的节点里面选择最空闲的。

- 为什么集群资源使用率很低却无法调度 Pod?
- 为什么部分节点资源使用率显著高于其他节点?
- 为什么只有部分节点资源无法调度?
- …
我们在实际工作实践中会遇到的典型场景就是资源热点问题,特定节点频繁发生 Pod 调度问题,整个集群资源利用率极低但是无法调度 Pod。如图,我们可以看到 Node1、Node2 已经调度满了 Pod,Node3 没有任何 Pod 调度上去,这个问题对跨 region 容灾高可用,整体的性能都有影响。我们通常在 Pod 调度失败会进入到该场景。
那么,我们该如何处理呢?

- 节点有 Pod 数量调度上限
- 节点有 CPU 请求调度上限
- 节点有内存请求调度上限

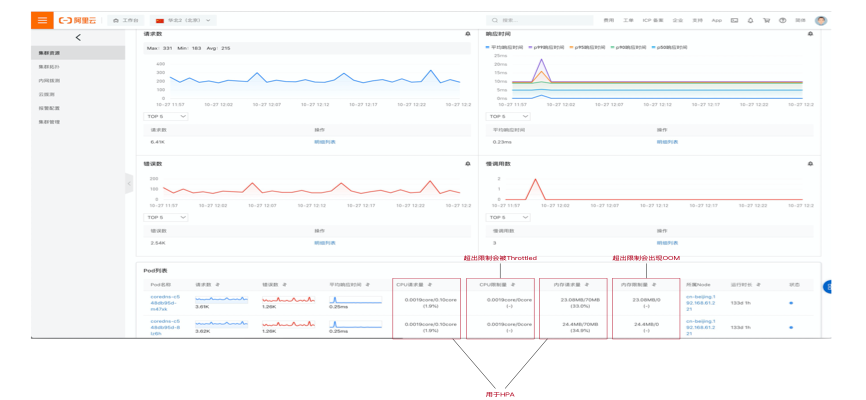
除了节点有资源热点问题之外,容器也有资源热点问题。如图,对于一个多副本服务来说,其容器的资源使用分布也可能有资源热点问题,主要体现在 CPU 和内存使用上,CPU 在容器环境中是可压缩资源,达到上限之后只会限制,不会对容器本身生命周期造成影响,而内存在容器环境中是不可压缩资源,达到上限之后会出现 OOM,由于每个节点运行的时候虽然处理的请求量一致,但是不同请求不同参数导致的 CPU 和内存消耗可能不一样,那么这样会导致部分容器的资源出现热点,对生命周期和自动扩缩容都会造成影响。
针对容器的资源热点问题,通过理论分析,我们需要关注的要点如下:
- CPU 是可压缩资源
- 内存是不可压缩资源
- Requests 用于调度
- Limits 用于运行时资源限制隔离
系统架构面临的挑战三:单点问题
对于单点问题而言,其本质就是高可用问题。高可用问题解法只有一个,就是冗余,多节点,多 region,多 zone,多机房,越分散越好,越冗余越好。除此之外,在流量增长,组件压力增大的情况下,系统各组件是否可以水平扩展也成为一个重要的议题。

通过上面的介绍我们可以看到 Kubernetes 监控可以从服务端,客户端多视角支持多语言多通信协议场景下的负载均衡问题排查,与此同时容器,节点,服务的资源热点问题排查,最后通过副本数检查和流量分析支持单点问题排查。在后续的迭代过程中,我们会将这些检查点作为场景开关,一键开启之后自动检查,报警。
原文链接
本文为阿里云原创内容,未经允许不得转载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2019-11-08 Ververica Platform-阿里巴巴全新Flink企业版揭秘