

全图化引擎(AI·OS)中的编译技术
全图化引擎又称算子执行引擎,它的介绍可以参考从HA3到AI OS -- 全图化引擎破茧之路。本文从算子化的视角介绍了编译技术在全图化引擎中的运用。主要内容有:
1. 通过脚本语言扩展通用算子上的用户订制能力,目前这些通用算子包括scorer算子,filter算子等。这一方面侧重于编译前端,我们开发了一种嵌入引擎的脚本语言cava,解决了用户扩展引擎功能的一些痛点,包括插件的开发测试效率,兼容性,引擎版本升级效率等。
2. 通过codegen技术优化全图化引擎性能,由于全图化引擎是基于tensorflow开发,它天生具备tensorflow xla编译能力,利用kernel的fuse提升性能,这部分内容可以参考XLA Overview。xla主要面向tensorflow内置的kernel,能发挥的场景是在线预测模型算分。但是对于用户自己开发的算子,xla很难发挥作用。本文第二部分主要介绍对于自定义算子我们是如何做codegen优化的。
通用算子上的脚本语言cava
由于算子开发和组图逻辑对普通用户来说成本较高,全图化引擎内置了一些通用算子,比如说scorer算子,filter算子。这些通用算子能加载c++插件,也支持用cava脚本写的插件。关于cava可以参考这篇文章了解一下。
和c++插件相比,cava插件有如下特点:
- 1. 类java的语法。扩大了插件开发的受众,让熟悉java的同学能快速上手使用引擎。
- 2. 性能高。cava是强类型,编译型语言,它能和c++无损交互。这保证了cava插件的执行性能,在单值场景使用cava写的插件和c++的插件性能相当。
- 3. 使用pool管理内存。cava的内存管理可定制,服务端应用每个请求一个pool是最高效的内存使用策略。
- 4. 安全。对数组越界,对象访问,除零异常做了保护。
- 5. 支持jit,编译快。支持upc时编译代码,插件的上线就和上线普通配置一样,极大的提升迭代效率
- 6. 兼容性:由于cava的编译过程和引擎版本是强绑定的,只要引擎提供的cava类库接口不变,cava的插件的兼容性很容易得到保证。而c++插件兼容性很难保证,任何引擎内部对象内存布局的变动就可能带来兼容性问题。
scorer算子中的cava插件
cava scorer目前有如下场景在使用
- 1. 主搜海选场景,算法逻辑可以快速上线验证
- 2. 赛马引擎2.0的算分逻辑,赛马引擎重构后引入cava算分替代原先的战马算分
package test;
import ha3.*;
/*
* 将多值字段值累加,并乘以query里面传递的ratio,作为最后的分数
* /
class DefaultScorer {
MInt32Ref mref;
double ratio;
boolean init(IApiProvider provider) {
IRefManager refManger = provider.getRefManager();
mref = refManger.requireMInt32("ids");
KVMapApi kv = provider.getKVMapApi();
ratio = kv.getDoubleValue("ratio");//获取kvpair内参数
return true;
}
double process(MatchDoc doc) {
int score = 0;
MInt32 mint = mref.get(doc);
for (int i = 0; i < mint.size(); i++) {
score = score + mint.get(i);
}
return score * ratio;
}
}其中cava scorer的算分逻辑(process函数)调用次数是doc级别的,它的执行性能和c++相比唯一的差距是多了安全保护(数组越界,对象访问,除零异常)。可以说cava是目前能嵌入c++系统执行的性能最好的脚本语言。
filter算子中cava插件
filter算子中主要是表达式逻辑,例如filter = (0.5 * a + b) > 10。以前表达式的能力较弱,只能使用算术,逻辑和关系运算符。使用cava插件可进一步扩展表达式的能力,它支持类java语法,可以定义变量,使用分支循环等。
计算 filter = (0.5 * a + b) > 10,用cava可定义如下:
class MyFunc {
public boolean init(FunctionProvider provider) {
return true;
}
public boolean process(MatchDoc doc, double a, double b) {
return (0.5 * a + b) > 10;
}
}
filter = MyFunc(a, b)
另外由于cava是编译执行的,和原生的解释执行的表达式相比有天然的性能优势。
关于cava前端的展望
cava是全图化引擎上面向用户需求的语言,有用户定制扩展逻辑的需求都可以考虑用通用算子+cava插件配合的模式来支持,例如全图化sql上的udf,规则引擎的匹配需求等等。
后续cava会进一步完善语言前端功能,完善类库,尽可能兼容java。依托suez和全图化引擎支持更多的业务需求。
自定义算子的codegen优化
过去几年,在OLAP领域codegen一直是一个比较热门的话题。原因在于大多数数据库系统采用的是Volcano Model模式。

其中的next()通常为虚函数调用,开销较大。全图化引擎中也有类似的codegen场景,例如统计算子,过滤算子等。此外,和xla类似,全图化引擎中也有一些场景可以通过算子融合优化性能。目前我们的codegen工作主要集中在cpu上对局部算子做优化,未来期望能在SQL场景做全图编译,并且在异构计算的编译器领域有所发展。
单算子的codegen优化
- 1. 统计算子
例如统计语句:group_key:key,agg_fun:sum(val)#count(),按key分组统计key出现的次数和val的和。在统计算子的实现中,key的取值有一次虚函数调用,sum和count的计算是两次虚函数调用,sum count计算出来的值又需要通过matchdoc存取,而matchdoc的访问有额外的开销:一次是定位到matchdoc storage,一次是通过偏移定位到存取位置。
那么统计codegen是怎么去除虚函数调用和matchdoc访问的呢?在运行时,我们可以根据用户的查询获取字段的类型,需要统计的function等信息,根据这些信息我们可以把通用的统计实现特化成专用的统计实现。例如统计sum和count只需定义包含sum count字段的AggItem结构体,而不需要matchdoc;统计function sum和count变成了结构体成员的+=操作。
假设key和val字段的类型都是int,那么上面的统计语句最终codegen成的cava代码如下:
class AggItem {
long sum0;
long count1;
int groupKey;
}
class JitAggregator {
public AttributeExpression groupKeyExpr;
public IntAggItemMap itemMap;
public AggItemAllocator allocator;
public AttributeExpression sumExpr0;
...
static public JitAggregator create(Aggregator aggregator) {
....
}
public void batch(MatchDocs docs, uint size) {
for (uint i = 0; i < size; ++i) {
MatchDoc doc = docs.get(i); //由c++实现,可被inline
int key = groupKeyExpr.getInt32(doc);
AggItem item = (AggItem)itemMap.get(key);
if (item == null) {
item = (AggItem)allocator.alloc();
item.sum0 = 0;
item.count1 = 0;
item.groupKey = key;
itemMap.add(key, (Any)item);
}
int sum0 = sumExpr0.getInt32(doc);
item.sum0 += sum0;
item.count1 += 1;
}
}
}
这里sum count的虚函数被替换成sum += 和count += ,matchdoc的存取变成结构体成员的读写item.sum0和item.count0。经过llvm jit编译优化之后生成的ir如下:
define void @_ZN3ha313JitAggregator5batchEP7CavaCtxPN6unsafe9MatchDocsEj(%"class.ha3::JitAggregator"* %this,
%class.CavaCtx* %"@cavaCtx@", %"class.unsafe::MatchDocs"* %docs, i32 %size)
{
entry:
%lt39 = icmp eq i32 %size, 0
br i1 %lt39, label %for.end, label %for.body.lr.ph
for.body.lr.ph: ; preds = %entry
%wide.trip.count = zext i32 %size to i64
br label %for.body
for.body: ; preds = %for.inc, %for.body.lr.ph
%lsr.iv42 = phi i64 [ %lsr.iv.next, %for.inc ], [ %wide.trip.count, %for.body.lr.ph ]
%lsr.iv = phi %"class.unsafe::MatchDocs"* [ %scevgep, %for.inc ], [ %docs, %for.body.lr.ph ]
%lsr.iv41 = bitcast %"class.unsafe::MatchDocs"* %lsr.iv to i64*
// ... prepare call for groupKeyExpr.getInt32
%7 = tail call i32 %5(%"class.suez::turing::AttributeExpressionTyped.64"* %1, i64 %6)
// ... prepare call for itemMap.get
%9 = tail call i8* @_ZN6unsafe13IntAggItemMap3getEP7CavaCtxi(%"class.unsafe::IntAggItemMap"* %8, %class.CavaCtx* %"@cavaCtx@", i32 %7)
%eq = icmp eq i8* %9, null
br i1 %eq, label %if.then, label %if.end10
// if (item == null) {
if.then: ; preds = %for.body
// ... prepare call for allocator.alloc
%15 = tail call i8* @_ZN6unsafe16AggItemAllocator5allocEP7CavaCtx(%"class.unsafe::AggItemAllocator"* %14, %class.CavaCtx* %"@cavaCtx@")
// item.groupKey = key;
%groupKey = getelementptr inbounds i8, i8* %15, i64 16
%16 = bitcast i8* %groupKey to i32*
store i32 %7, i32* %16, align 4
// item.sum0 = 0; item.count1 = 0;
call void @llvm.memset.p0i8.i64(i8* %15, i8 0, i64 16, i32 8, i1 false)
// ... prepare call for itemMap.add
tail call void @_ZN6unsafe13IntAggItemMap3addEP7CavaCtxiPNS_3AnyE(%"class.unsafe::IntAggItemMap"* %17, %class.CavaCtx* %"@cavaCtx@", i32 %7, i8* %15)
br label %if.end10
if.end10: ; preds = %if.end, %for.body
%item.0.in = phi i8* [ %15, %if.end ], [ %9, %for.body ]
%18 = bitcast %"class.unsafe::MatchDocs"* %lsr.iv to i64*
// ... prepare call for sumExpr0.getInt32
%26 = tail call i32 %24(%"class.suez::turing::AttributeExpressionTyped.64"* %20, i64 %25)
// item.sum0 += sum0; item.count1 += 1;
%27 = sext i32 %26 to i64
%28 = bitcast i8* %item.0.in to <2 x i64>*
%29 = load <2 x i64>, <2 x i64>* %28, align 8
%30 = insertelement <2 x i64> undef, i64 %27, i32 0
%31 = insertelement <2 x i64> %30, i64 1, i32 1
%32 = add <2 x i64> %29, %31
%33 = bitcast i8* %item.0.in to <2 x i64>*
store <2 x i64> %32, <2 x i64>* %33, align 8
br label %for.inc
for.inc: ; preds = %if.then, %if.end10
%scevgep = getelementptr %"class.unsafe::MatchDocs", %"class.unsafe::MatchDocs"* %lsr.iv, i64 8
%lsr.iv.next = add nsw i64 %lsr.iv42, -1
%exitcond = icmp eq i64 %lsr.iv.next, 0
br i1 %exitcond, label %for.end, label %for.body
for.end: ; preds = %for.inc, %entry
ret void
}
codegen的代码中有不少函数是通过c++实现的,如docs.get(i),itemMap.get(key)等。但是优化后的ir中并没有docs.get(i)的函数调用,这是由于经常调用的c++中实现的函数会被提前编译成bc,由cava编译器加载,经过llvm inline优化pass后被消除。
可以认为cava代码和llvm ir基本能做到无损映射(cava中不容易实现逻辑可由c++实现,预编译成bc加载后被inline),有了cava这一层我们可以用常规面向对象的编码习惯来做codegen,不用关心llvm api细节,让codegen门槛进一步降低。
这个例子中,统计规模是100w文档1w个key时,线下测试初步结论是latency大约能降1倍左右(54ms->27ms),有待表达式计算进一步优化。
- 2. 过滤算子
在通用过滤算子中,表达式计算是典型的可被codegen优化的场景。例如ha3的filter语句:filter=(a + 2* b - c) > 0:
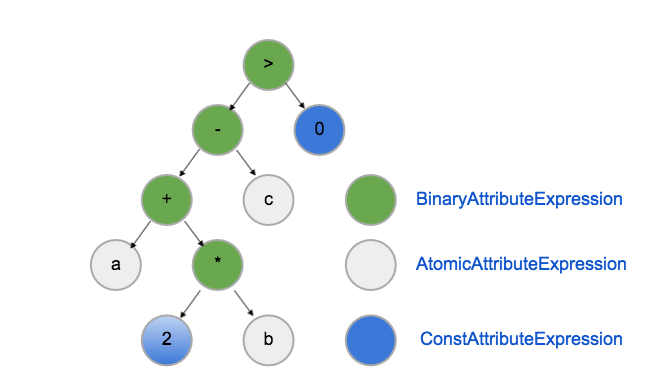
表达式计算是通过AttributeExpression实现的,AttributeExpression的evaluate是虚函数。对于单doc接口我们可以用和统计类似的方式,使用cava对表达式计算做codegen。
对于批量接口,和统计不同的是,表达式的批量计算更容易运用向量化优化,利用cpu的simd指令,使计算效率有成倍的提升。但是并不是所有的表达式都能使用一致的向量化优化方法,比如filter= a > 0 AND b < 0这类表达式,有短路逻辑,向量化会带来不必要的计算。
因此表达式的编译优化需要有更好的codegen抽象,我们发现Halide能比较好的满足我们的需求。Halide的核心思想:算法描述(做什么 ir)和性能优化(怎么做 schedule)解耦。这种解耦能让我们更灵活的定制优化策略,比如某些场景走向量化,某些场景走普通的codegen;更进一步,不同计算平台上使用不同的优化策略也成为可能。
- 3. 倒排召回算子
在seek算子中,倒排召回是通过QueryExecutor实现的,QueryExecutor的seek是虚函数。例如query= a AND b OR c。
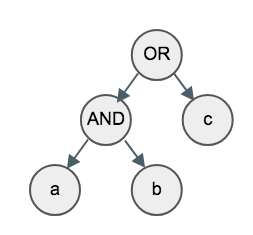
QueryExecutor的And Or AndNot有比较复杂的逻辑,虚函数的开销相对占比没有表达式计算那么大,之前用vtune做过预估,seek虚函数调用开销占比约10%(数字不一定准确,inline效果没法评估)。和精确统计,表达式计算相比,query的组合空间巨大,seek的codegen得更多的考虑对高性价比query做编译优化。
- 4. 海选与排序算子
在ha3引擎中海选和精排逻辑中有大量比较操作。例如sort=+RANK;id字句,对应的compare函数是Rank Compartor和Id Compartor的联合比较。compare的函数调用可被codegen掉,并且还可和stl算法联合inline。std::sort使用非inline的comp函数带来的开销可以参考如下例子:
bool myfunction (int i,int j) { return (i<j); }
int docCount = 200000;
std::random_device rd;
std::mt19937_64 mt(rd());
std::uniform_int_distribution<int> keyDist(0, 200000);
std::vector<int> myvector1;
for (int i = 0 ; i < docCount; i++) {
myvector1.push_back(keyDist(mt));
}
std::vector<int> myvector2 = myvector1;
std::sort (myvector1.begin(), myvector1.end()); // cost 15.475ms
std::sort (myvector2.begin(), myvector2.end(), myfunction); // cost 19.757ms
对20w随机数排序,简单的比较inline带来30%的提升。当然在引擎场景,由于比较逻辑复杂,这部分收益可能不会太多。
算子的fuse和codegen
算子的fuse是tensorflow xla编译的核心思想,在全图化场景我们有一些自定义算子也可以运用这个思想,例如feature generator。
fg特征生成是模型训练中很重要的一个环节。在线fg是以子图+配置形式描述计算,这部分的codegen能使数据从索引直接计算到tensor上,省去了很多环节中间数据的拷贝。目前这部分codegen工作可以参考这篇文章

关于编译优化的展望
- SQL场景全图的编译执行
数据库领域Whole-stage Code Generation早被提出并应用,例如Apache Spark as a Compiler;还有现在比较火的GPU数据库Mapd,把整个执行计划编译成架构无关的中间表示(llvm ir),借助llvm编译到不同的target执行。
从实现上看,SQL场景的全图编译执行对全图化引擎还有更多意义,比如可以省去tensorflow算子执行带来的线程切换的开销,可以去除算子间matchdoc传递(matchdoc作为通用的数据布局性能较差)带来的性能损耗。
- 面向异构计算的编译器
随着摩尔定律触及天花板,未来异构计算一定是一个热门的领域。SQL大规模数据分析和在线预测就是异构计算可以发挥作用的典型场景,比如分析场景大数据量统计,在线预测场景深度模型大规模并行计算。cpu驱动其他计算平台如gpu fpga,相互配合各自做自己擅长的事情,在未来有可能是常态。这需要为开发人员提供更好的编程接口。
全图化引擎已经领先了一步,集成了tensorflow计算框架,天生具备了异构计算的能力。但在编译领域,通用的异构计算编程接口还远未到成熟的地步。工业界和学术界有不少尝试,比如tensorflow的xla编译框架,TVM,Weld等等。
借用weld的概念图表达一下异构计算编译器设计的愿景:让数据分析,深度学习,图像算法等能用统一易用的编程接口充分发挥异构计算平台的算力。

总结
编译技术已经开始在引擎的用户体验,迭代效率,性能优化中发挥作用,后续会跟着全图化引擎的演进不断发展。
原文链接
本文为云栖社区原创内容,未经允许不得转载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?