
常见索引介绍
日常开发工作中,涉及到的数据存储,要做查询优化或想深入了解存储引擎,需要对索引知识有个起码的了解,下面介绍下最常见的四种索引结构。
-
-
哈希索引
-
BTREE索引
-
倒排索引
1、位图索引(BitMap)
位图索引适用于字段值为可枚举的有限个数值的情况
下图1 为用户表,存储了性别和婚姻状况两个字段。
图2中 分别为性别和婚姻状态建立了两个位图索引;
例如:性别->男对应索引为:101110011,表示第1、3、4、5、8、9个用户为男性。其他属性以此类推。

-
男性 并且已婚 的记录 = 101110011 & 11010010 = 100100010,即第1、4、8个用户为已婚男性。
-
女性 或者未婚的记录 = 010001100 | 001010100 = 011011100, 即第2、3、5、6、7个用户为女性或者未婚。
注:位图索引查询主要进行“与/或”操作,性能非常高;并且空间占用少;一个常见的场景就是用着统计标签化用户上,对用户进行分类;Redis提供了方便的位图操作命令,使用很方便;但位图“位资源”的回收不方便,且稀松的位图会浪费空间,位图进行非运算较困难
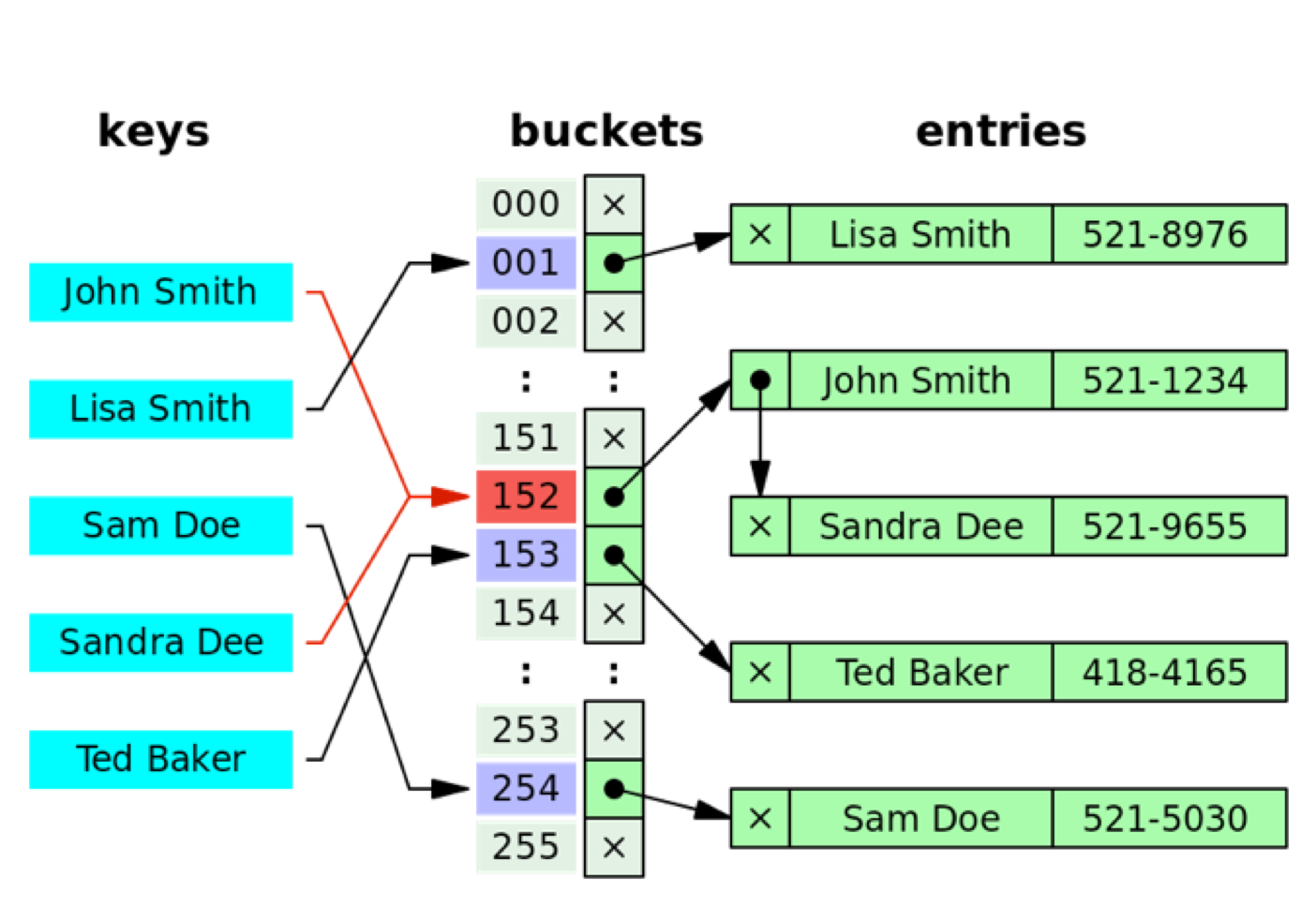
BTREE: 有序平衡N叉树, 每个节点有N个键值和N+1个指针, 指向N+1个子节点
一棵BTREE的简单结构如下图4所示,为一棵2层的3叉树,有7条数据:
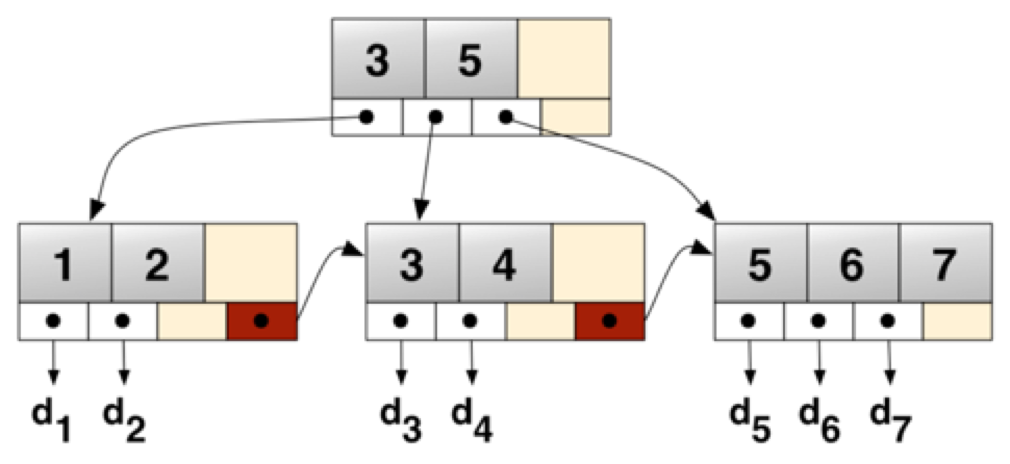
图4
以Mysql最常用的InnoDB引擎为例,描述下BTREE索引的应用。
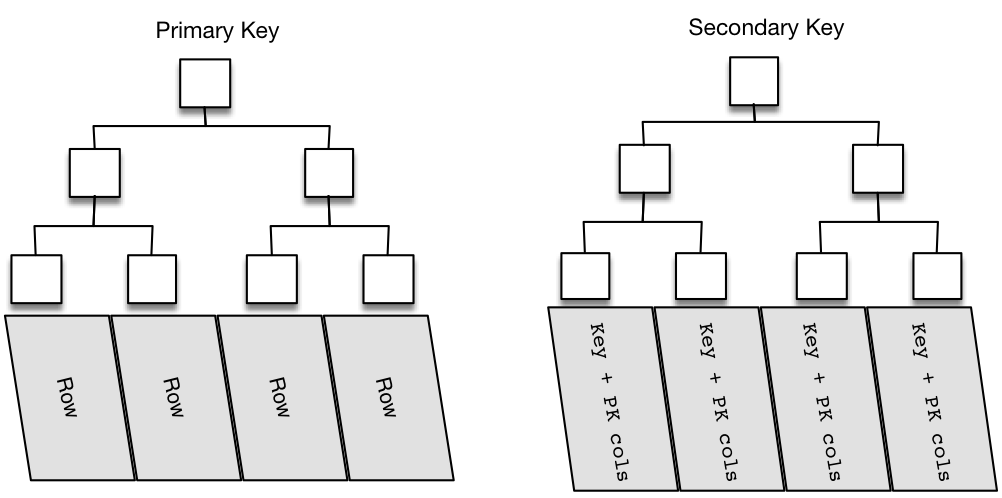
图5
主键索引为图5的左半部分(如果没有显式定义自主主键,就用不为空的唯一索引来做聚簇索引,如果也没有唯一索引,则innodb内部会自动生成6字节的隐藏主键来做聚簇索引),叶子节点存储了完整的数据行信息(以主键 + row_data形式存储)。
二级索引也是以B+tree的形式进行存储,图5右半部分,与主键不同的是二级索引的叶子节点存储的不是行数据,而是索引键值和对应的主键值,由此可以推断出,二级索引查询多了一步查找数据主键的过程。
维护一颗有序平衡N叉树,比较复杂的就是当插入节点时节点位置的调整,尤其是插入的节点是随机无序的情况;而插入有序的节点,节点的调整只发生了整个树的局部,影响范围较小,效率较高。
可以参考红黑树的节点的插入算法:https://en.wikipedia.org/wiki/Red%E2%80%93black_tree
因此如果innodb表有自增主键,则数据写入是有序写入的,效率会很高;如果innodb表没有自增的主键,插入随机的主键值,将导致B+tree的大量的变动操作,效率较低。这也是为什么会建议innodb表要有无业务意义的自增主键,可以大大提高数据插入效率。
Mysql Innodb使用自增主键的插入效率高。
使用类似Snowflake的ID生成算法,生成的ID是趋势递增的,插入效率也比较高。
正向索引反映了一篇文档与文档中关键词之间的对应关系;给定文档标识,可以获取当前文档的关键词、词频以及该词在文档中出现的位置信息,如图6 所示,左侧是文档,右侧是索引。

图6

图7
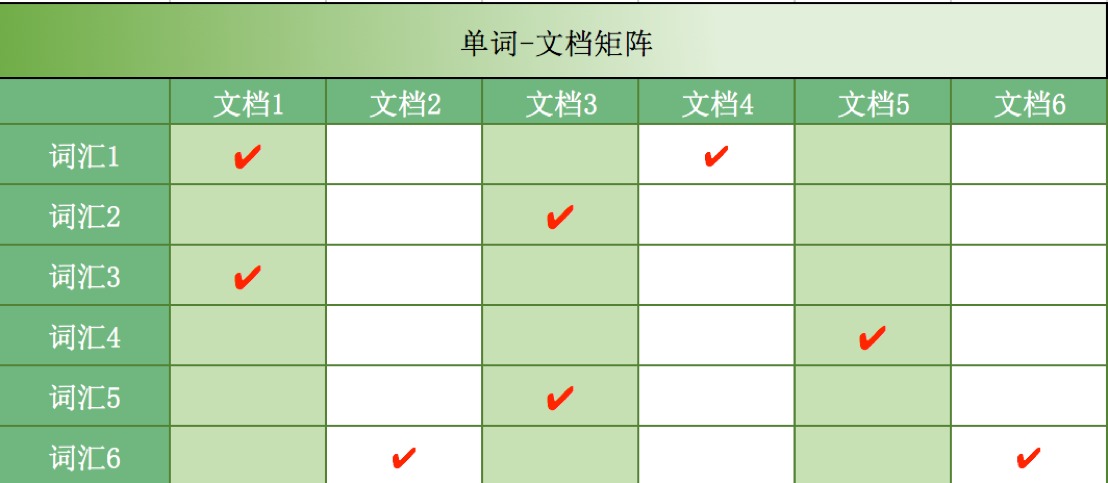
图8
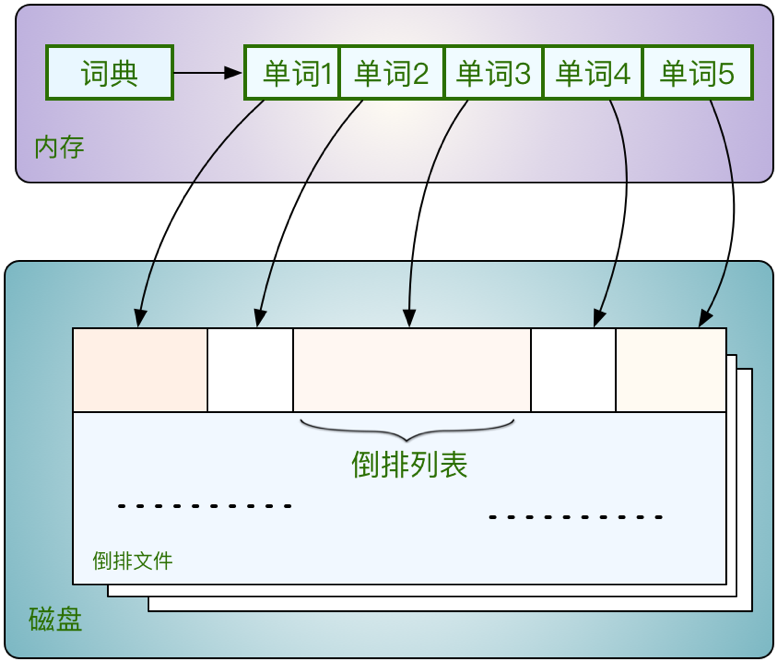
图9
如图10,共存在5个文档,第一列为文档编号,第二列为文档的文本内容。
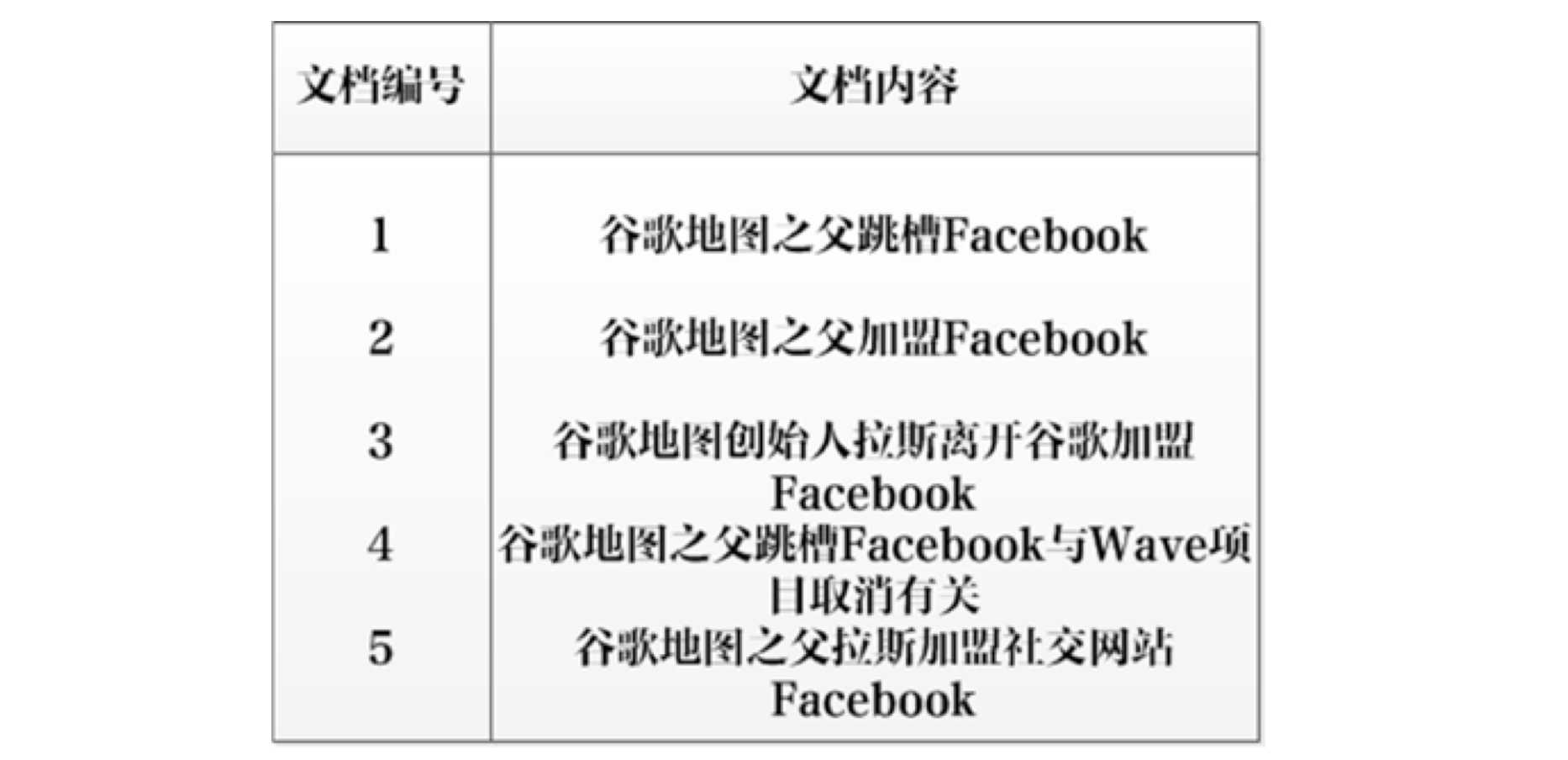
图10
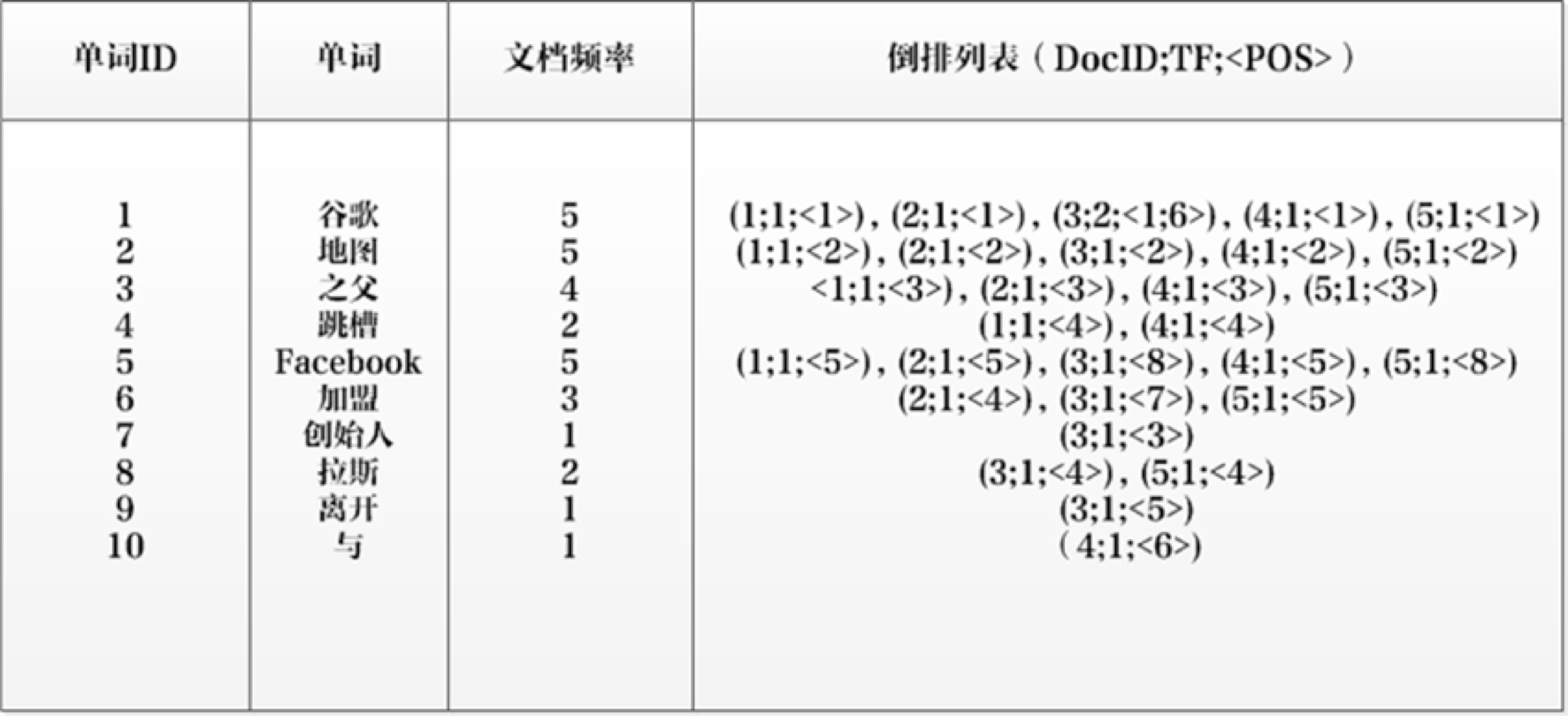
图11
-
单词词典查询优化
对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词,这直接影响搜索时的响应速度,其中的优化方案就是为单词词典建立索引,有以下几种方案可供参考:
-
词典Hash索引
Hash索引简单直接,查询某个单词,通过计算哈希函数,如果哈希表命中则表示存在该数据,否则直接返回空就可以;适合于完全匹配,等值查询。如图12,相同hash值的单词会放在一个冲突表中。
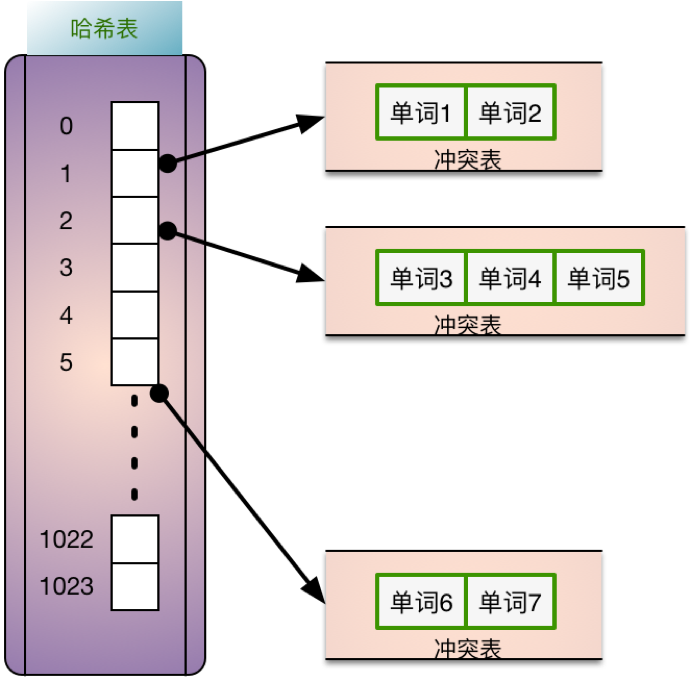
-
类似于Innodb的二级索引,将单词按照一定的规则排序,生成一个BTree索引,数据节点为指向倒排索引的指针。
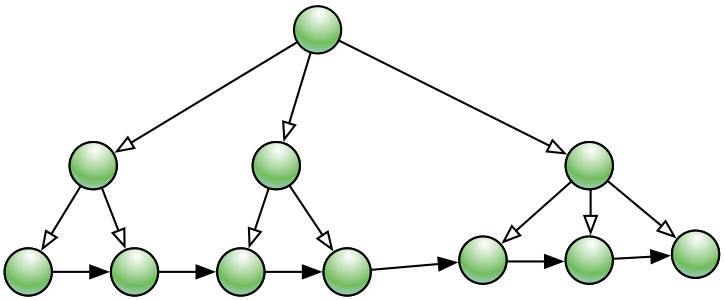
图13
同样将单词按照一定的规则排序,建立一个有序单词数组,在查找时使用二分查找法;二分查找法可以映射为一个有序平衡二叉树,如图14这样的结构。
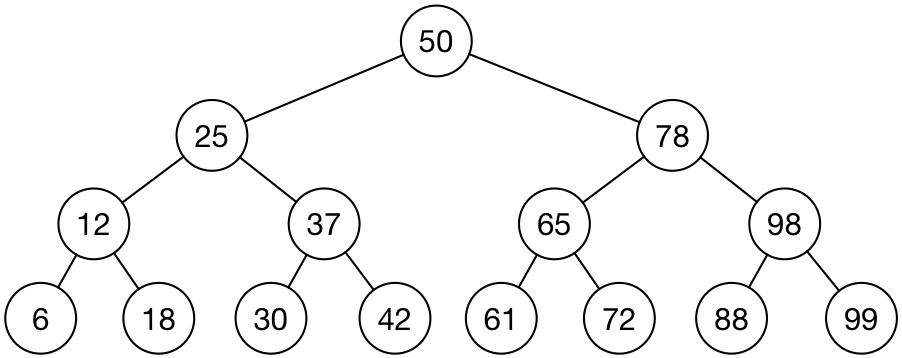
图14
4. FST(Finite State Transducers )实现
FST为一种有限状态转移机,FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。
以插入“cat”、 “deep”、 “do”、 “dog” 、“dogs”这5个单词为例构建FST(注:必须已排序)。
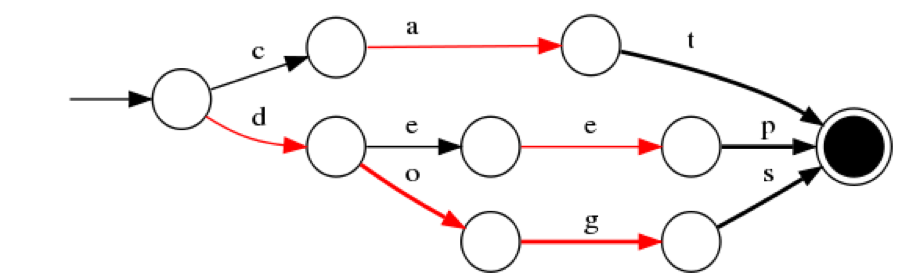
图15
当然还有其他的优化方式,如使用Skip List、Trie、Double Array Trie等结构进行优化,不再一一赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号