

1.excel数据量过大该怎么处理好点?
依常规的处理方式,会把导入的excel文件转为流进行处理,但是如果excel数据量达到 几十兆,该怎么处理呢?
几十万的数据导入,直接会崩溃的。
答案:
POI读取Excel有两种模式,一种是用户模式,一种是SAX事件驱动模式,将xlsx格式的文档转换成CSV格式后进行读取。用户模式API接口丰富,使用POI的API可以很容易读取Excel,但用户模式消耗的内存很大,当遇到很大sheet、大数据网格,假空行、公式等问题时,很容易导致内存溢出。POI官方推荐解决内存溢出的方式使用CVS格式解析,即SAX事件驱动模式。
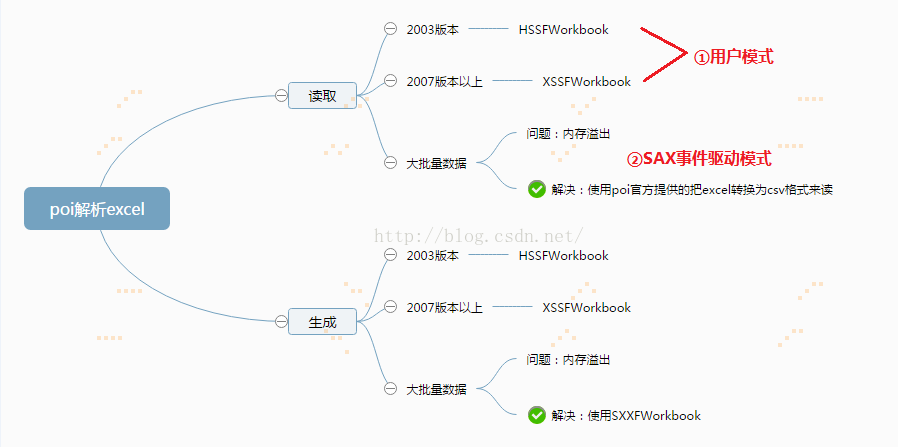
POI以SAX解析excel2007文件
解决思路:通过继承DefaultHandler类,重写process(),startElement(),characters(),endElement()这四个方法。process()方式主要是遍历所有的sheet,并依次调用startElement()、characters()方法、endElement()这三个方法。startElement()用于设定单元格的数字类型(如日期、数字、字符串等等)。characters()用于获取该单元格对应的索引值或是内容值(如果单元格类型是字符串、INLINESTR、数字、日期则获取的是索引值;其他如布尔值、错误、公式则获取的是内容值)。endElement()根据startElement()的单元格数字类型和characters()的索引值或内容值,最终得出单元格的内容值,并打印出来。
具体查看地址:https://www.cnblogs.com/swordfall/p/8298386.html
方式二:
(1)常规的就是把文件存到服务器 MultipartFile.transferTo(new File(path)) 的方法。
这个方法是将文件存在服务器本地,这样方便后续文件内容的读取,用不着一次读取所有的内容从而导致消耗大量的内存。当然这里大家如果有更好的方法希望能留言告知哈。
(2)解析服务器上的文件,也就是上面的SAX解析,然后用SXXFWorkbook 处理数据。
(3)我们需要将读取到的EXCEL数据插入到数据库中,这里为了减小数据库的IO和提高插入的效率,我们采用5000一批的批量插入(注意:如果数据量过大会导致组成的SQL语句无法执行)。
连贯性 (1)(2)(3).
方式三:
基于事件驱动,SAX的方式解析excel(.xlsx是基于OOXML的),CPU和内存消耗非常低,但是只能读不能写,所以数据无法保存起来;
所以,(1)首先按照常规的 方式把文件转存到服务器上去读取;
(2)然后大批量数据由SXXFWorkbook 去处理。

