ceph若干关键问题
1. ceph群集里pg存在的意义?
PG是一种间址,PG的数量有限,记录PG跟OSD间的映射关系可行,而记录object到OSD之间的映射因为数量巨大而实际不可行或效率太低。从用途来说,搞个映射本身不是目的,让故障或者负载均衡变得可操作是目的;
ceph实现了两种了字符串hash,
一种是Linux dcache采用的hash算法,比较简洁;
另一种是RJenkins hash 算法,根据object name计算hash 采用的Rjenkins hash 算法。
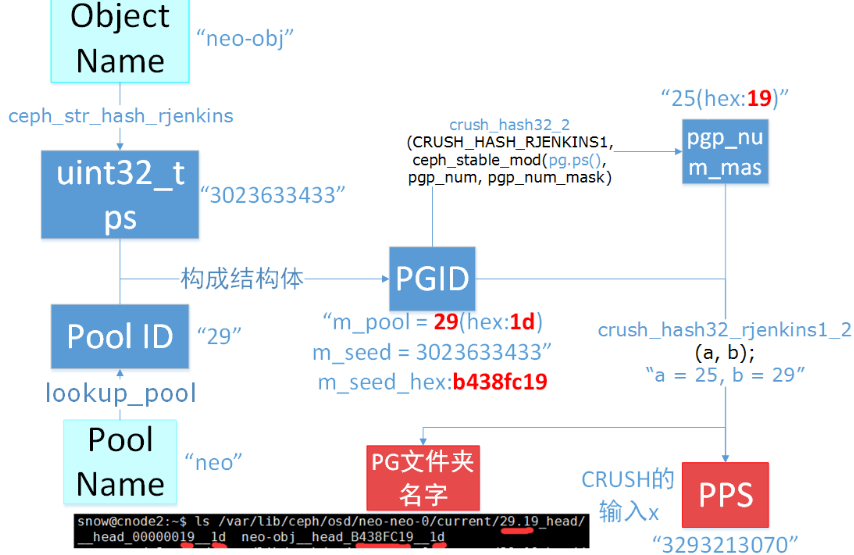
计算x的过程:
1.对象name进行hash算出一个uint的值ps;
2.ps与pgp_number进行mod后得到余数b;
3.b于pool id进行hash,得到一个值,即X,作为do_crush_rule()的入参;
2. weight和reweight
ceph osd crush reweight” 设置了OSD的权重
weight :这个重量为任意值(通常是磁盘的TB大小,1TB设置为1),并且控制系统尝试分配到OSD的数据量。
reweight :reweight将覆盖了weight量。这个值在0到1的范围,并强制CRUSH重新分配数据。它不改变buckets 的权重,并且是CRUSH不正常的情况下的纠正措施。(例如,如果你的OSD中的一个是在90%以上,其余为50%,可以减少权重,进行补偿。)
通常情况下,当OSD上面数据相对不平衡时,我们应该使用ceph osd reweight 命令修改reweight值,而不应该使用ceph osd crush reweight 命令修改weight值。
原因在于,修改reweight值将不会改变bucket的weight,而如果修改weight值就会改变整个bucket的weight,bucket weight 一旦改变,就会导致数据在bucket之间进行迁移,而不是在bucket内部进行迁移,这能最小化数据的交换量。
通过ceph osd reweight 设置权重,更新了什么?
ceph osd reweight 命令仅仅更新了OSDMap中osd_weights的值,而crush下面的item_weight值并不改变。从命令行传入的 [0.0 ~ 1.0] 的值会被系统归一化,将值乘个乘数(0x10000)并将其截整,所以osd_weigth下面的最大值为 0x10000,这对于下面解释osd_weights如何起作用时候,至关重要。
归一化算式:weigth = (int)input_weight * 0x10000 (65536)
从算式可知,当weight 被截整后,精度能够到0.000015,如果权重值变化差异小于该值的,可能的结果是weigth截整后数值没有变化,这也限定了weight的精度值。
简单来说,bucket weight表示设备(device)的容量,1TB对应1.00。bucket weight是所有item weight之和,item weight的变化会影响bucket weight的变化,也就是osd.X会影响host。
osd weight的取值为0~1。osd reweight并不会影响host。当osd被踢出集群时,osd weight被设置0,加入集群时,设置为1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号