快速上手多机多卡的分布式tensorflow
终于又有时间和成果拿出来和大家分享,实在不容易,之前由于临时更换任务加上入职事情多断更了很久,现在主要在做一些KG和KGQA方面的工作。今天要和大家分享的是最近在工作中实现的分布式tensorflow。(BTW打个广告~NLP和DL讨论欢迎加群~二维码在末尾~)
理论在这里就不详细介绍了,说说对一些概念自己的理解吧:
(1)task->server->cluster:
这里其实应该也是分布式计算的一些基本概念,在分布式tensorflow中,采用的主从模式,即master-slave模式。有一个总控服务器来负责传递数据和调度,若干从节点服务器负责计算。在这里,我们所说的每一个服务器也就对应一个server。在tensorflow中,总控服务器其实叫做参数服务器(Parameter Server),在实际操作中负责参数的更新,但是并不负责图的计算。那么负责计算的是什么呢?在这里就是工作节点(工作服务器)。在每个工作服务器上,tensorflow都会保存整张计算图并且独立的进行计算。不过值得注意的是,尽管叫server级别,但是不一定一个节点就只能是一个服务器,他仅仅对应服务器上的一个端口,使用某个服务器的一部分资源(或者所有资源),同时若干个工作节点也可以放在一个资源足够的服务器上,在后面的代码中你会看到我就是这么做的。注意到之前说的参数服务器和工作服务器都是server级别的,在这个级别下,每个服务器可以有若干个task,每个task对应一个具体的计算操作。在这个级别之上,若干个工作节点可以构成一个计算集群,而若干个参数服务器可以构成一个参数服务器集群。
(2)gRPC:
这里主要放一些干货,介绍一些谷歌自己开发的通信协议gRPC,这也是分布式tensorflow用来做多机进程间通信的协议。额外想提以下的其实是一些tradeoff,由于现在只是跑通了demo而没有在大的模型上做实验,有一个需要验证的问题就是:在没有足够多台服务器的情况下,到底是使用两台服务器,将参数更新和图计算分开,降低整个服务器的压力,还是应该单机多卡,减少任务之间的通信开销,这个问题需要在后面的工作中验证,也希望有经验的同学给出意见。
gRPC是一个高性能、开源和通用的RPC框架,面向移动和HTTP/2设计。目前提供C、Java和Go语言版本,分别是grpc、grpc-java、grpc-go。gRPC基于HTTP/2标准设计,带来诸如双向流、流控、头部压缩、单TCP连接上的多复用请求等特性。这些特性使得其在移动设备上表现更好,更省电和节省空间占用。gRPC由google开发,是一款语言中立、平台中立、开源的远程过程调用系统。在gRPC里客户端应用可以像调用本地对象一样直接调用另一台不同机器上服务端应用的方法,使得你能够更容易地创建分布式应用和服务。与许多RPC系统类似,gRPC也是基于以下理念:定义一个服务,指定其能够被远程调用的方法(包括参数和返回类型)。在服务端实现这个接口,并运行一个gRPC服务器来处理客户端调用。在客户端拥有一个存根能够像服务端一样的方法。
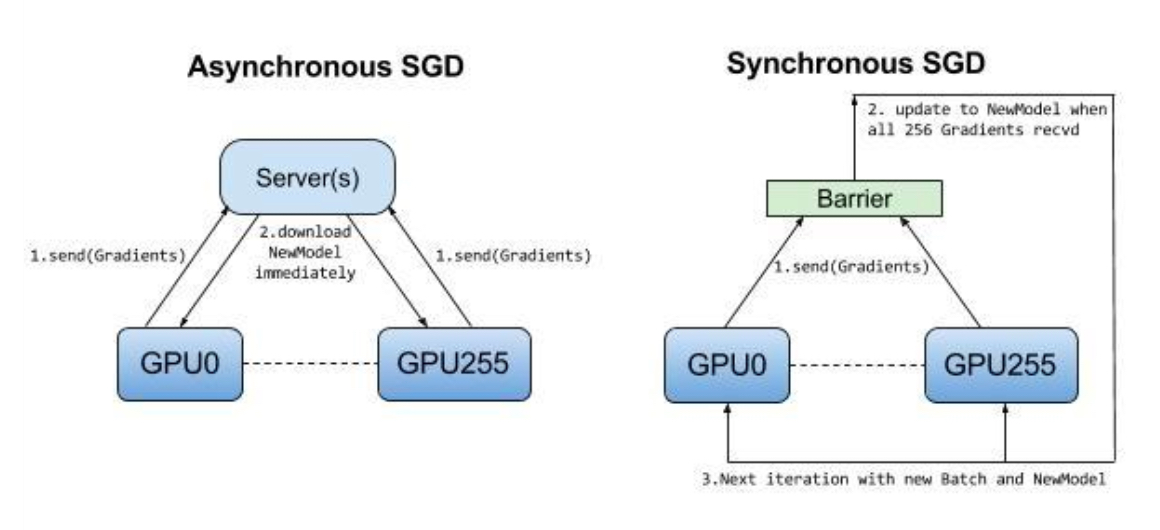
好了,理论说完了,现在要展现我和其他博主不一样的地方了:直接上能跑的代码!对于代码的解释直接见注释部分。注意:运行代码需要在每一个节点分别运行一次,并不是一劳永逸的哦(虽然我最开始也是这么觉得的)运行的命令如下:(demo修改自https://github.com/TracyMcgrady6/Distribute_MNIST,特别感谢)
python distributed.py --job_name=ps --task_index=0 #在参数服务器上运行,启动参数服务器 python distributed.py --job_name=worker --task_index=0 #在工作节点上运行,启动工作节点0 python distributed.py --job_name=worker --task_index=1 #在工作节点上运行,启动工作节点1
上代码~这个代码其实是用来训练minist的,我用的是两个RTX2080(有木有很羡慕~),速度有多快呢?大概不到30秒就训练完了10000步,差点没来得及给同事看~如果有同学跑下面的代码遇到问题可以找我要源码~邮箱见上一条~
# encoding:utf-import math import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" import tempfile import time import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import os flags = tf.app.flags IMAGE_PIXELS = 28 # 定义默认训练参数和数据路径 #tf.flags其实就是定义一些命令行参数 flags.DEFINE_string('data_dir', '/tmp/mnist-data', 'Directory for storing mnist data') flags.DEFINE_integer('hidden_units', 100, 'Number of units in the hidden layer of the NN') flags.DEFINE_integer('train_steps', 10000, 'Number of training steps to perform') flags.DEFINE_integer('batch_size', 100, 'Training batch size ') flags.DEFINE_float('learning_rate', 0.01, 'Learning rate') # 定义分布式参数 # 参数服务器parameter server节点 flags.DEFINE_string('ps_hosts', '192.168.6.156:22223', 'Comma-separated list of hostname:port pairs') # 两个worker节点 flags.DEFINE_string('worker_hosts', '192.168.6.164:22221,192.168.6.164:22220', 'Comma-separated list of hostname:port pairs') # 设置job name参数 flags.DEFINE_string('job_name', None, 'job name: worker or ps') # 设置任务的索引 flags.DEFINE_integer('task_index', None, 'Index of task within the job') # 选择异步并行,同步并行,在本程序中其实没有用到 flags.DEFINE_integer("issync", None, "是否采用分布式的同步模式,1表示同步模式,0表示异步模式") FLAGS = flags.FLAGS def main(unused_argv): mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) if FLAGS.job_name is None or FLAGS.job_name == '': raise ValueError('Must specify an explicit job_name !') else: print ('job_name : %s' % FLAGS.job_name) if FLAGS.task_index is None or FLAGS.task_index == '': raise ValueError('Must specify an explicit task_index!') else: print ('task_index : %d' % FLAGS.task_index) ps_spec = FLAGS.ps_hosts.split(',') worker_spec = FLAGS.worker_hosts.split(',') # 创建集群 num_worker = len(worker_spec) cluster = tf.train.ClusterSpec({'ps': ps_spec, 'worker': worker_spec}) server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index) if FLAGS.job_name == 'ps': server.join() is_chief = (FLAGS.task_index == 0) # worker_device = '/job:worker/task%d/cpu:0' % FLAGS.task_index #难点其实在这里,通过worker_device指定在同一台服务器上的不同显卡作为工作节点 with tf.device(tf.train.replica_device_setter( worker_device = '/job:worker/task:%d/gpu:%d' %(FLAGS.task_index, FLAGS.task_index), ps_device = '/job:ps/cpu:0', cluster=cluster )): global_step = tf.Variable(0, name='global_step', trainable=False) # 创建纪录全局训练步数变量 hid_w = tf.Variable(tf.truncated_normal([IMAGE_PIXELS * IMAGE_PIXELS, FLAGS.hidden_units], stddev=1.0 / IMAGE_PIXELS), name='hid_w') hid_b = tf.Variable(tf.zeros([FLAGS.hidden_units]), name='hid_b') sm_w = tf.Variable(tf.truncated_normal([FLAGS.hidden_units, 10], stddev=1.0 / math.sqrt(FLAGS.hidden_units)), name='sm_w') sm_b = tf.Variable(tf.zeros([10]), name='sm_b') x = tf.placeholder(tf.float32, [None, IMAGE_PIXELS * IMAGE_PIXELS]) y_ = tf.placeholder(tf.float32, [None, 10]) hid_lin = tf.nn.xw_plus_b(x, hid_w, hid_b) hid = tf.nn.relu(hid_lin) y = tf.nn.softmax(tf.nn.xw_plus_b(hid, sm_w, sm_b)) cross_entropy = -tf.reduce_sum(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))) opt = tf.train.AdamOptimizer(FLAGS.learning_rate) train_step = opt.minimize(cross_entropy, global_step=global_step) # 生成本地的参数初始化操作init_op init_op = tf.global_variables_initializer() train_dir = tempfile.mkdtemp() sv = tf.train.Supervisor(is_chief=is_chief, logdir=train_dir, init_op=init_op, recovery_wait_secs=1, global_step=global_step) if is_chief: print ('Worker %d: Initailizing session...' % FLAGS.task_index) else: print ('Worker %d: Waiting for session to be initaialized...' % FLAGS.task_index) #sess = sv.prepare_or_wait_for_session(server.target) #第二个坑在这里,必须要设置allow_soft_placement为True让tensorflow可以自动找到最适合的设备,否则会说不存在gpu的kernel,同时建议运行时只安装tensorflow_gpu config = tf.ConfigProto(allow_soft_placement = True) sess = sv.prepare_or_wait_for_session(server.target, config=config) print ('Worker %d: Session initialization complete.' % FLAGS.task_index) time_begin = time.time() print ('Traing begins @ %f' % time_begin) local_step = 0 while True: batch_xs, batch_ys = mnist.train.next_batch(FLAGS.batch_size) train_feed = {x: batch_xs, y_: batch_ys} _, step = sess.run([train_step, global_step], feed_dict=train_feed) local_step += 1 now = time.time() print ('%f: Worker %d: traing step %d dome (global step:%d)' % (now, FLAGS.task_index, local_step, step)) if step >= FLAGS.train_steps: break time_end = time.time() print ('Training ends @ %f' % time_end) train_time = time_end - time_begin print ('Training elapsed time:%f s' % train_time) val_feed = {x: mnist.validation.images, y_: mnist.validation.labels} val_xent = sess.run(cross_entropy, feed_dict=val_feed) print ('After %d training step(s), validation cross entropy = %g' % (FLAGS.train_steps, val_xent)) sess.close() if __name__ == '__main__': tf.app.run()
如果你喜欢博主的分享或者觉得这个分享对你有用,可以支持博主一下,以便他写出更好的文章~

NLP讨论群二维码~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号