神经机器翻译-NMT
论文:
Neural Machine Translation by Jointly Learning to Align and Translate

提出背景:
机器翻译又称为自动翻译,是利用计算机将一种自然语言(源语言)转换成另外一种自然(目标语言)语言的过程,本质问题是如何实现两种不同语言之间的等价转换。它是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。机器翻译是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用价值。随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。机器翻译的趋势是让机器更“自主”的学习如何翻译,大致可以分为三个阶段:1980到1990年之间,大多都是基于规则的翻译,包含了转化法(transfer-based)、中间语法(interlingual)、以及辞典法(dictionary-based)等;1990年到2013年之间,开始使用了基于统计的翻译,利用数学统计规律进行翻译;2013年之后,主流的方法开始使用基于神经网络的翻译,主要是使用深度学习的方法。
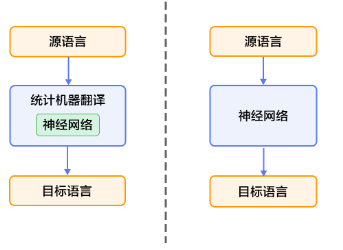
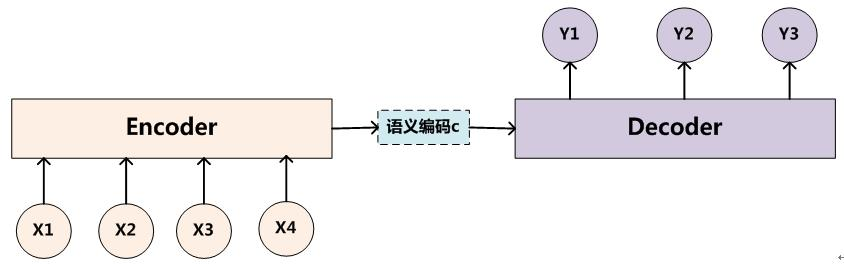
目前为止,在机器翻译中性能最好的是2014年提出神经机器翻译模型(NMT),其相对于传统的基于句子的统计模型翻译模型更加方便,输入一个源句子,构造一个单一的比较大的神经网络对源语言进行学习,最终输出目标语言即可,如上图所示。而这其中,大多数的模型都是基于2014年Cho和Sutskever等人提出的Encoder-Decoders的模型,利用一个encoder将输入的源语言编码成一个固定的向量,然后将其在网络中学习之后利用decoder对该向量进行解码,最终得到目标语言。但是这里面作者发现了一些问题,当encoder将源语言压缩成固定的向量时,意味着将所有的重要信息进行了压缩,那么当输入的源语言越来越长时,就会丢失一些重要信息,最终导致翻译的性能下降。因此为了解决这个问题,作者就提出了基于联合学习对齐和翻译的神经翻译模型,大致思想是:将输入的源语言不再压缩成固定的向量,而是将他们编码成一系列灵活的向量,当decoder对每一个单词进行翻译时,会考虑与该单词相关的向量,自适应的选择这些重要的信息,然后基于上下文和这些重要信息来对该单词进行翻译。这样做就更符合我们人类翻译的步骤,先对每个单词进行翻译,然后根据上下文进行调整,最终得到我们满意的结果。
回顾神经机器翻译(NMT):
从概率学的角度来看,机器翻译其实就是对给定源语言x的条件下,寻找输出为y的目标语言的最大概率,即$argmax_yp(y|x)$。而现在效果最好的是基于RNN的长短时记忆网络(LSTM)的Encoder-Decoder模型,而本文作者也是与该模型进行了对比实验,验证了作者提出模型的优越性能。
假设源语言的输入为$1,2,3,...,T_x$,源语言转换成的向量模式为$x=(x_{1},...,x_{T_x})$,通过RNN网络要得到隐藏状态,而当前的隐藏状态是由上一个隐藏状态和当前的输入所共同决定,即

获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后该句子的上下文的向量c
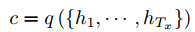
其中$h_{t} \in R^n$表示t时刻的隐藏状态,f和q是非线性激活函数。一种简单的方法是将最后的隐藏层作为上下文向量c
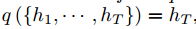
解码阶段可以看做编码的逆过程,decoder根据给定的上下文向量c和已经生成的单词${y_{1},...,y_{t-1}}$来预测下一个生成的单词$y_t$
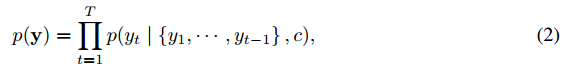
其中$y=(y_{1},...,y_{T_y})$,其中的条件概率模型也可以写成
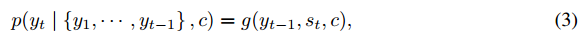
其中g是非线性激活函数,$y_{t-1}$表示上一个阶段隐藏层的输出,$s_t$表示当前RNN的隐藏层的状态,c表示前面提到的上下文向量。最终句子的输出其实就是求该条件概率的最大乘积,即$argmaxp(y_t)$
基于attention的NMT:
Attention模型

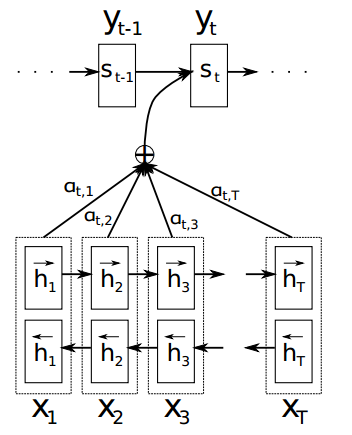
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。在这篇文章中,作者提出了一个用于翻译任务的结构。解码部分使用了attention模型,而在编码部分,则使用了BiRNN(bidirectional RNN,双向RNN)。
Encoder
作者使用双向RNN(BiRNN),对每一个输入的源语言的单词不仅保留该单词前面的信息,也保留该单词后面的信息,输入与前面一样,定义前向传播RNN的隐藏层$\vec f$为$(\vec{h_1},...,\vec{h_{T_x}})$,后向传播的RNN的隐藏层$\overleftarrow f$为$(\overleftarrow{h_1},...,\overleftarrow{h_{T_x}})$。所以将二者结合第j个单词的隐藏层表示就是$(\vec{h_j ^\top};\overleftarrow{h_j ^\top})$,由此得出的$h_j$的向量就代表着$x_j$单词的集中信息,然后将其传到Decoder。
Decoder
在该架构中,作者引入attention机制,将之前的条件概率写为
![]()
其中$s_i$表示Decoder在i时刻的隐藏状态,其计算公式为
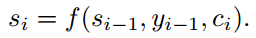
这里可以发现,在计算第i时刻的目标输出$y_i$时,要考虑的是i时刻的上下文$c_i$,而不是之前总的上下文c,i时刻的上下文$c_i$其实就是前面所定义的第i时刻所记录的隐藏层信息的权值和
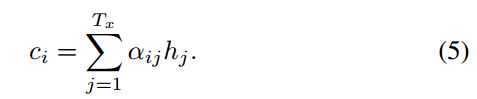
由于Encoder使用了双向RNN,因此可以认为$h_i$中包含了输入序列中第i个词以及前后一些词的信息。将隐藏向量序列按权重相加,表示在生成第j个输出的时候的注意力分配是不同的。$\alpha_ij$的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大,$alpha_ij$又是怎么得到的呢?这个其实是由第i-1个输出隐藏状态$s_{i-1}$和输入中各个隐藏状态共同决定的的softmax函数。
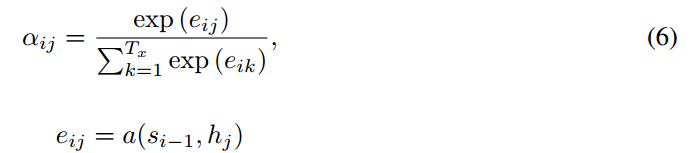
也就是说,$s_{i-1}$先和每个$h$分别计算得到一个值,然后使用softmax得到i时刻在输出$T_x$个输入隐藏状态中的注意力分配向量,这个分配向量也就是计算$c_i$的权重,而这个$c_i$就是attention值。
论文中的model:
Encoder:
作者采用的双向RNN是基于门单元的双向LSTM架构,称为RNNsearch,在文章的公式中略去了偏置项。首先输入1-K个单词的词向量
![]()
输出为1-K个单词的词向量
![]()
其中$K_x$和$K_y$分别表示源语言和目标语言的词汇量的大小,$T_x$和$T_y$分别表示源语言和目标语言的长度。
首先计算双向RNN前向传播的结果
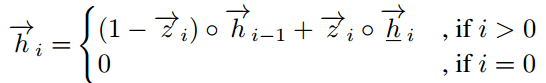
其中
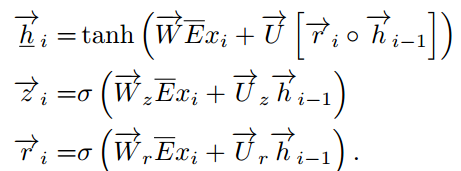
![]() 是词嵌入矩阵,
是词嵌入矩阵,![]() 都是权重矩阵,m是词嵌入的维度,n是隐藏层的单元个数,$sigma$是sigmoid函数。
都是权重矩阵,m是词嵌入的维度,n是隐藏层的单元个数,$sigma$是sigmoid函数。
反向的RNN和前面计算类似,从而得出$h_i$
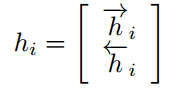
Decoder:
Decoder端的隐藏层$s_i$计算方法为
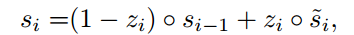
其中

E是目标语言的词嵌入矩阵,![]()
![]() 都是权重,m是词嵌入的维度,n是隐藏层的单元个数,其中$s_0$定义为
都是权重,m是词嵌入的维度,n是隐藏层的单元个数,其中$s_0$定义为![]()
计算第i时刻的上下文$c_i$
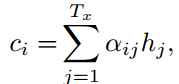
其中
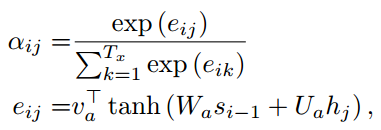
$h_j$表示是源语言j时刻的隐藏层,![]()
![]() 都是权重矩阵。
都是权重矩阵。
条件概率
![]()
其中
![]()
![]() 都是权重矩阵。
都是权重矩阵。
实验:
为了检验性能,作者分别使用传统模型和attention模型在英语-法语的翻译数据集上进行了测验。传统模型的编码器和解码器各有1000个隐藏单元。编码器中还有一个多层神经网络用于实现从隐藏状态到单词的映射。在优化方面,使用了SGD(minibatch stochastic gradient descent)以及Adadelta,前者负责采样,后者负责优化下降方向。得到的结果如下:
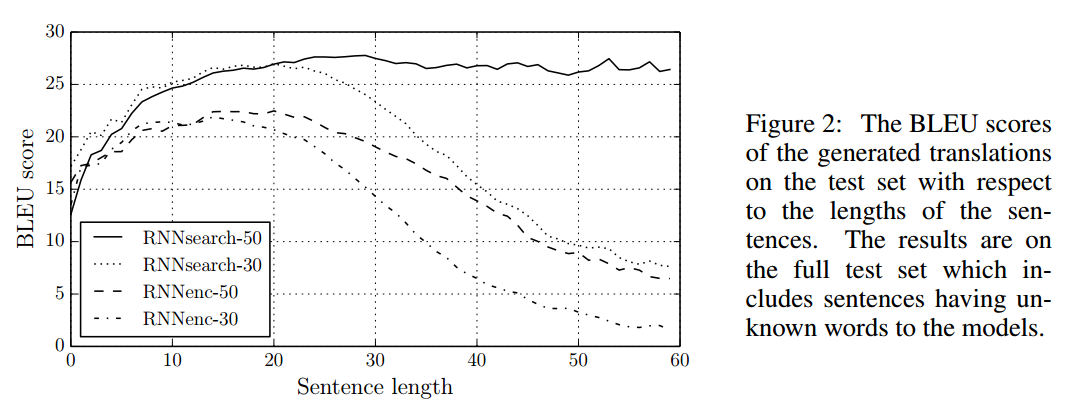
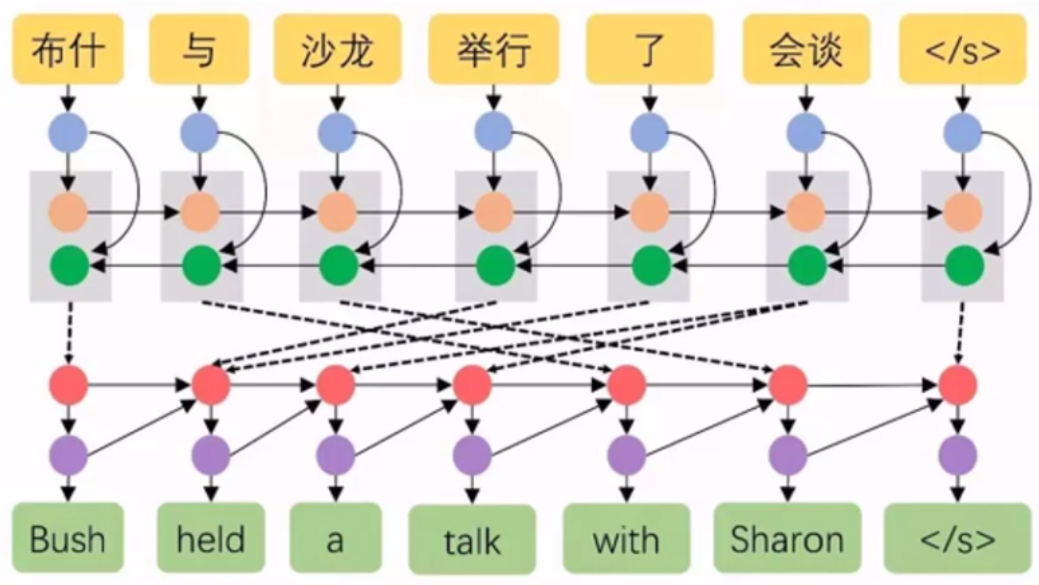
图中RNNenc表示传统的结构,而RNNsearch表示attention模型。后面的数字表示序列的长度。可以看到,不论序列长度,attention模型的性能均优于传统的编码-解码模型。而RNNsearch-50甚至在长文本上的性能也非常的优异。除了准确度之外,还有一个很值得关注的东西:注意力矩阵。之前已经提过,每个输出都有一个长为$T_x$的注意力向量,那么将这些向量合起来看,就是一个矩阵。对其进行可视化,得到如下结果
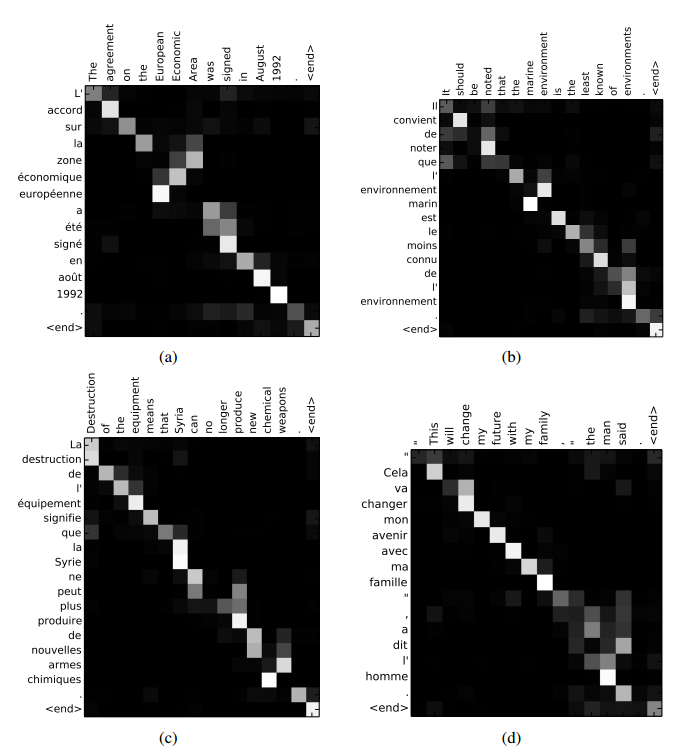
其中x轴表示待翻译的句子中的单词(英语),y轴表示翻译以后的句子中的单词(法语)。可以看到尽管从英语到法语的过程中,有些单词的顺序发生了变化,但是attention模型仍然很好的找到了合适的位置。换句话说,就是两种语言下的单词“对齐”了。因此,也有人把注意力模型叫做对齐(alignment)模型。而且像比于用语言学实现的硬对齐,这种基于概率的软对齐更加优雅,因为能够更全面的考虑到上下文的语境。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号