生成对抗网络GAN
简介:
前面学到的网络比如CNN、RNN这些都是基于有监督式的学习,训练模型时我们需要输入样本和对应的label,给定损失函数,利用网络来学习数据的模式和特征。那么我们就不禁提出一个想法,有没有一种网络,对于给定的输入,且输入的数据无指定label,通过一个网络对这些数据进行学习,自动得出损失函数,从而学习数据的分布呢?答案肯定是有的,这就是16年非常火热的无监督式的学习下的生成对抗GAN网络,被一些学者认为是20年来机器学习领域最酷的想法。本文只是记录对该网络的个人理解,仅供个人学习和参考。
- 论文:Generative Adversarial Net(2014)
- GAN论文集合:这里
- GAN代码集合:这里
GAN的基本概念:
GAN的思想是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我们两人的总空间是一定的,这就是二人博弈,但是呢总利益是一定的。引申到GAN里面就是可以看成,GAN中有两个这样的博弈者,一个是生成模型(G),一个是判别模型(D),他们各自有各自的功能。
- 生成模型(伪装者角色):在GAN网络中生成器扮演伪装者角色,我希望生成的数据伪装度特别高,可以以假乱真,我的目的就达到了。所以生成器的作用就是找出观测数据内部的统计规律,生成相似数据,并逐渐提高造样本的能力,使判别网络无法判断我产生的数据与真实数据谁为真谁为假,最好这样的概率是0.5,我们认为这就是一个非常好的生成器。
- 判别模型(警察角色):在GAN网络中判别器扮演警察角色,我希望我有很强的鉴别能力,对于传入的真样本,我一眼可以判断出其为真,对于长得很像真样本的加样本(生成器产生的样本),我一眼可以判断出其为假,我的目的就达到了。所以判别器的作用就是判断输入数据是来自真实样本集还是假样本集,一个完美的判别器,若输入样本是真样本,网络输出就接近1,输入是假样本,网络输出接近0,我们认为这就是一个非常好的判别器。
附上一张图可以很好的理解:
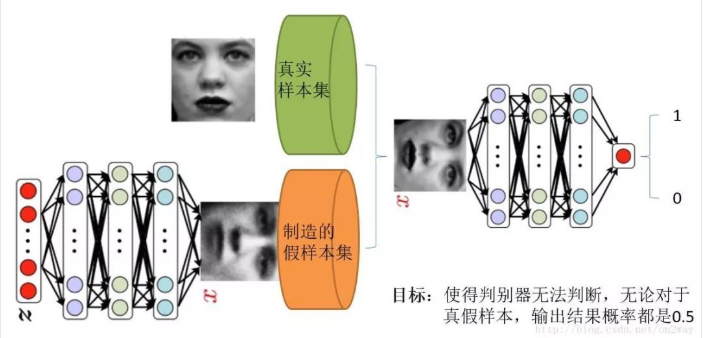
上图中,右边就是判别器,可以看出他其实就是一个二分类器,对于输入最终输出结果是0或1的概率值,然而输入却有两种,一种是真实的样本数据,这对应的输出肯定为1的概率高,另一种是由生成器生成的假样本。而对于左边下方的生成器,其输入是一组随机数Z,输出是一个图像,不再是一个数值。由此可以看出训练一个GAN网络我们需要真实采集而来的样本数据集,仅此而已,而且很关键的一点是我们连数据集的label都没有。而我们要得到的在最原始的GAN网络中通过输入一个噪声,模拟得到一个人脸图像,这个图像可以非常逼真以至于以假乱真。而对抗网络的过程就是判别网络说,我很强,来一个样本我就知道它是来自真样本集还是假样本集。生成网络就不服了,说我也很强,我生成一个假样本,虽然我生成网络知道是假的,但是你判别网络不知道呀,我包装的非常逼真,以至于判别网络无法判断真假,那么用输出数值来解释就是,生成网络生成的假样本进去了判别网络以后,判别网络给出的结果是一个接近0.5的值,极限情况就是0.5,也就是说判别不出来了,这就是纳什平衡了。由这个分析可以发现,生成网络与判别网络的目的正好是相反的,一个说我能判别的好,一个说我让你判别不好。所以叫做对抗,叫做博弈。那么最后的结果到底是谁赢呢?这就要归结到设计者,也就是我们希望谁赢了。作为设计者的我们,我们的目的是要得到以假乱真的样本,那么很自然的我们希望生成样本赢了,也就是希望生成样本很真,判别网络能力不足以区分真假样本。
GAN的训练过程:
知道了GAN大概的目的与设计思路,那么一个很自然的问题来了就是我们该如何用数学方法解决这么一个对抗问题。这就涉及到如何训练这样一个生成对抗网络模型了,还是先上一个图,用图来解释最直接:
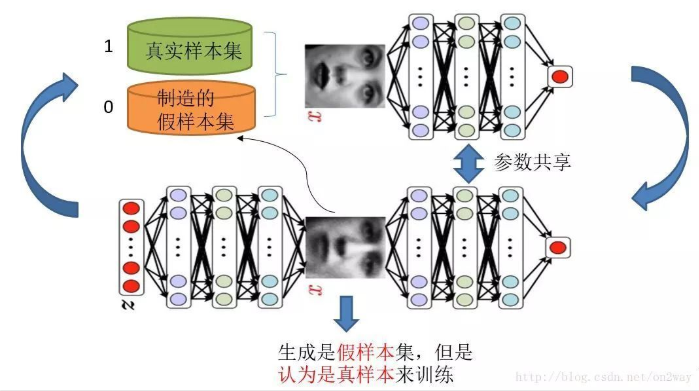
需要注意的是生成模型与对抗模型可以说是完全独立的两个模型,好比就是完全独立的两个神经网络模型,他们之间没有什么联系。而训练他们的方法就是单独交替迭代训练,假设现在生成网络模型已经有了(当然可能不是最好的生成网络),那么给一堆随机数组,就会得到一堆假的样本集(因为不是最终的生成模型,那么现在生成网络可能就处于劣势,导致生成的样本就不咋地,可能很容易就被判别网络判别出来了说这货是假冒的),但是先不管这个,假设我们现在有了这样的假样本集,真样本集一直都有,现在我们人为的定义真假样本集的label,因为我们希望真样本集的输出尽可能为1,假样本集为0,很明显这里我们就已经默认真样本集所有的label都为1,而假样本集的所有label都为0。有人会说,在真样本集里面的人脸中,可能张三人脸和李四人脸不一样呀,对于这个问题我们需要理解的是,我们现在的任务是什么,我们是想分样本真假,而不是分真样本中那个是张三label、那个是李四label。况且我们也知道,原始真样本的label我们是不知道的。回过头来,我们现在有了真样本集以及它们的label(都是1)、假样本集以及它们的label(都是0),这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。假设训练完了,下面我们来看生成网络。
对于生成网络,想想我们的目的,是生成尽可能逼真的样本。那么原始的生成网络生成的样本你怎么知道它真不真呢?就是送到判别网络中,所以在训练生成网络的时候,我们需要联合判别网络一起才能达到训练的目的。什么意思?就是如果我们单单只用生成网络,那么想想我们怎么去训练?误差来源在哪里?细想一下没有,但是如果我们把刚才的判别网络串接在生成网络的后面,这样我们就知道真假了,也就有了误差了。所以对于生成网络的训练其实是对生成-判别网络串接的训练,就像图中显示的那样。好了那么现在来分析一下样本,原始的噪声数组Z我们有,也就是生成了假样本我们有,此时很关键的一点来了,我们要把这些假样本的标签都设置为1,也就是认为这些假样本在生成网络训练的时候是真样本。那么为什么要这样呢?我们想想,是不是这样才能起到迷惑判别器的目的,也才能使得生成的假样本逐渐逼近为正样本。好了,重新顺一下思路,现在对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),是不是就可以训练了?有人会问,这样只有一类样本,训练啥呀?谁说一类样本就不能训练了?只要有误差就行。还有人说,你这样一训练,判别网络的网络参数不是也跟着变吗?没错,这很关键,所以在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数,这样就完成了生成网络的训练了。
在完成生成网络训练好,那么我们是不是可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本了,没错,并且训练后的假样本应该是更真了才对。然后又有了新的真假样本集(其实是新的假样本集),这样又可以重复上述过程了。我们把这个过程称作为单独交替训练。我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。看完了这个过程是不是感觉GAN的设计真的很巧妙,个人觉得最值得称赞的地方可能在于这种假样本在训练过程中的真假变换,这也是博弈得以进行的关键之处。
训练中的优化问题:
原始论文中给定了优化函数如下,D为判别器,G为生成器,x是真实样本,z为随机噪声样本:

该式被称为极大极小化博弈,其实是两个优化问题合在一起了,现在我们分开看这两个优化问题。
- 优化判别器D:
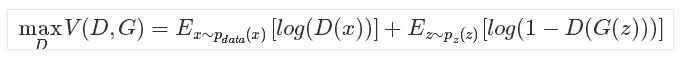
可以看到,优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好。对于假样本,需要优化使得其结果越小越好(接近0),也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这不矛盾了,所以呢把第二项改成1-D(G(z))(因为D(G(z))输出是一个介于(0,1)的概率值,所以1-D(G(z))最大为1,最小为0,而其值越小,log值越接近负无穷),这样两者合起来就是越大越好,想一个极端的例子,对于每个输入真样本x,前面都为1,与真实样本期望一样,对于每个输入假样本z,后面都是0,1-D(G(z))是1,与假样本的期望也一样,两个期望都是最大,所以和也是最大。
- 优化生成器G:
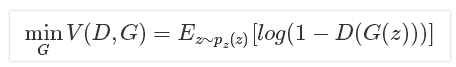
在优化G的时候,这个时候没有真样本什么事,所以把第一项直接却掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z)),本质上没有区别,只是为了形式的统一。
最终将二者合起来就是原始的最大最小目标函数。回过头来我们来看这个最大最小目标函数,里面包含了判别模型的优化,包含了生成模型的以假乱真的优化,完美的阐释了这样一个优美的理论。
进一步理解:
一开始说生成器的作用是为了学习真实数据中的统计规律,或者说学习真实数据的数据分布,那么这里怎么理解呢?我们知道,传统的机器学习方法,我们一般都会定义一个什么模型让数据去学习。比如说假设我们知道原始数据属于高斯分布,只是不知道高斯分布的参数,这个时候我们定义高斯分布,然后利用数据去学习高斯分布的参数得到我们最终的模型。再比如说我们定义一个分类器,比如SVM,然后强行让数据进行东变西变,进行各种高维映射,最后可以变成一个简单的分布,SVM可以很轻易的进行二分类分开,其实SVM已经放松了这种映射关系了,但是也是给了一个模型,这个模型就是核映射(什么径向基函数等等),说白了其实也好像是你事先知道让数据该怎么映射一样,只是核映射的参数可以学习罢了。所有的这些方法都在直接或者间接的告诉数据你该怎么映射一样,只是不同的映射方法能力不一样。那么我们再来看看GAN,生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律了,有了这个规律,想生成人脸还不容易。然而这个规律我们开始知道吗?显然不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
原始论文中是这样解释的:
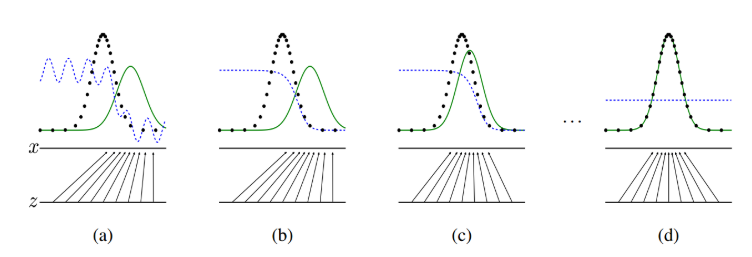
这张图表明的是GAN的生成网络如何一步步从均匀分布学习到正太分布的。原始数据x服从正太分布,这个过程你也没告诉生成网络说你得用正太分布来学习,但是生成网络学习到了。假设你改一下x的分布,不管什么分布,生成网络可能也能学到。这就是GAN可以自动学习真实数据的分布的强大之处。如上图所示,生成对抗网络会训练并更新判别分布(即 D,蓝色的虚线),更新判别器后就能将数据真实分布(黑点组成的线)从生成分布 P_g(G)(绿色实线)中判别出来。下方的水平线代表采样域 Z,其中等距线表示 Z 中的样本为均匀分布,上方的水平线代表真实数据 X 中的一部分。向上的箭头表示映射 x=G(z) 如何对噪声样本(均匀采样)施加一个不均匀的分布 P_g。
- (a)考虑在收敛点附近的对抗训练:P_g 和 P_data 已经十分相似,D 是一个局部准确的分类器。
- (b)在算法内部循环中训练 D 以从数据中判别出真实样本,该循环最终会收敛到 D(x)=P_data(x)/(P_data(x)+P_g(x))。
- (c)随后固定判别器并训练生成器,在更新 G 之后,D 的梯度会引导 G(z)流向更可能被 D 分类为真实数据的方向。
- (d)经过若干次训练后,如果 G 和 D 有足够的复杂度,那么它们就会到达一个均衡点。这个时候 P_g=P_data,即生成器的概率密度函数等于真实数据的概率密度函数,也即生成的数据和真实数据是一样的。在均衡点上 D 和 G 都不能得到进一步提升,并且判别器无法判断数据到底是来自真实样本还是伪造的数据,即 D(x)= 1/2。
GAN网络的改进:
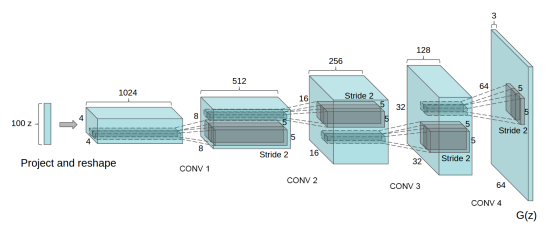
- 深度卷积 GAN(DCGAN)
论文:https://arxiv.org/pdf/1511.06434.pdf
最开始提出的GAN网络遇到的问题是训练不稳定,容易产生梯度消失和训练不收敛等问题,其原因在于其网络内部都是全连接,因此就产生了 使用CNN网络的DCGAN,很好的解决了原始的问题。其改进的地方在与:- 所有的pooling层使用步幅卷积(判别网络)和微步幅度卷积(生成网络)进行替换。
- 在生成网络和判别网络上使用批处理规范化。
- 对于更深的架构移除全连接隐藏层。
- 在生成网络的所有层上使用RelU激活函数,除了输出层使用Tanh激活函数。
- 在判别网络的所有层上使用LeakyReLU激活函数。
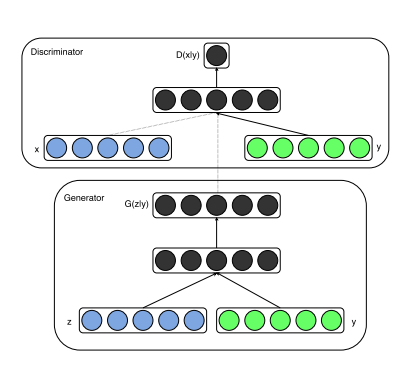
- 条件性 GAN(CGAN)
论文:https://arxiv.org/pdf/1411.1784.pdf
原始的GAN输入的是随机数据,如果我们想将输入改成更有意义的数据,也就是给我们这个随机数据一个前进的方向,让生成网络朝着我们这个方向生成数据,希望GAN的输出与输入具有指定的关系,因此提出了CGAN。
条件生成式对抗网络(CGAN)是对原始GAN的一个扩展,生成器和判别器都增加额外信息y为条件,y可以为任意信息,例如类别信息,或者其他模态的数据。如下图所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。
类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):
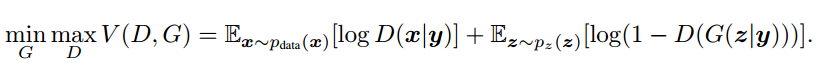
- InfoGAN
论文:https://arxiv.org/pdf/1606.03657.pdf
这是一种无监督式的CGAN,输入包括两部分:C(可解释的隐变量)和Z(初始输入),通过学习使得C中包含有对数据的可解释的信息。InfoGAN生成图像之后,不仅要求生成图像和真实图像难以区分,还要求能够从生成图像中预测出C,这样就为输入和输出建立起了一个联系。
- Wasserstein GAN(WGAN)
论文:https://arxiv.org/pdf/1701.07875.pdf
GAN使用了一个分类器来度量输出分布和期望分布的差异性,但是如果学到的是一个很复杂的分布,就会出现模式奔溃(model collapse)的问题,只能学习其中的一部分。其产生的原因在于GAN的损失函数使判别器假样本的惩罚是巨大的,一旦生成某一类假样本成功骗过判别器,生成器就趋向于生成相似的样本。于是WGAN就提出修改损失函数的计算方法,对失败相对宽容。
参考文章:
详解一:GAN完整理论推导和实现
详解二:详解生成对抗网络(GAN)原理
详解三:DCGAN的实现
详解四:令人拍案叫绝的WGAN

