SQL Server 2019 深度解读:微软数据平台的野望
本文为笔者在InfoQ首发的原创文章,主要利用周末时间陆续写成,也算近期用心之作。现转载回自己的博客,请大家多多指教。
11 月 4 日,微软正式发布了其新一代数据库产品 SQL Server 2019,带来了大数据集群、数据虚拟化等重磅特性。本次发布距离上一个大版本 SQL Server 2017 不过短短两年时间,这样的迭代速度对于高度复杂的数据库系统而言颇为惊人。两年前 InfoQ 曾刊登长文《SQL Server 2017 正式发布,微软老牌数据库如何继往开来?》,此次我们再度与该文作者合作,为大家深度解读 SQL Server 2019 的进展与特色。
21 世纪以来,数据平台的战场上烽火连天、精彩纷呈。所谓江山代有才人出,以 MongoDB、Redis、Neo4j 等为代表的 NoSQL 数据库和 Hive、Impala、Presto 等 Hadoop 体系大数据解决方案风头一时无两。在这些年轻后辈们的冲击之下,关系数据库作为数据架构的中坚力量,不但没有节节败退,近年反倒有王者归来、愈战愈勇之势。在如今各类关键系统的设计和架构中,关系型数据库仍然以稳定的表现和丰富的特性占据着核心地位。
SQL Server是关系数据库中的杰出代表,是与 Oracle、DB2 齐名的企业级商用数据库“三巨头”之一。长达数十年的发展和磨砺,已让它非常成熟稳定;而跟随时代发展不断地融合技术新趋势,又使它非常全面。尤其上一个版本 SQL Server 2017 更是将此款传奇数据库带入了广阔的 Linux 世界,进一步拓展了它的潜在客户群体和使用场景。
我们大可先简单回顾 SQL Server 琳琅满目的丰富特性。在两年前的文章中我们提到,SQL Server 已经集传统行存储、可更新的列存储、内存表、图数据库、机器学习等十八般武艺于一身。这其中许多先进的特性,有些是开源数据库仍在苦苦追赶的领域,或是无法在同一个数据库中进行完美的集成。这正是商业数据库的价值所在:以高稳定性、高性能与高集成度赢得青睐,在帮助客户支撑解决关键业务问题的同时,亦能简化技术架构、减轻维护负担。
仅仅两年的时间,微软就在上一代的基础上发展构建出了全新的 SQL Server 2019,这样的迭代速度对于高度复杂的数据库系统而言颇为惊人。快节奏发布固然和如今业界普遍激进的版本策略有关,但大家也一定好奇,一个已经高度成熟的商业数据库系统,在这样短的时间里究竟能取得怎样的进步?又在哪些方面针对变幻莫测的市场作出了自己的回应呢?本文将与大家一同探索。
结合 SQL Server 2019 的新特性,我们接下来分别从核心引擎增强、数据虚拟化以及此版本最大亮点 SQL Server 大数据集群三个方面来进行分析和探讨。
核心引擎增强
我们首先从核心引擎部分说起。HTAP (Hybrid transaction/analytical processing) 混合负载能力是当今数据库世界的趋势,SQL Server 在这方面是行业引领者之一,之前版本已通过在单一引擎中完美集成行存储和列存储实现了对 OLTP 和 OLAP 工作负载的同时支撑。用户不但可以同时查询和连接行存和列存表,甚至可以为一个行存储表添加非聚集的列存储索引,使得单表能够同时较好地支持 OLTP 和 OLAP 两种工作模式和查询场景。
SQL Server 2019 中继续强化了对于混合负载能力的支持,通过润物细无声式的改进让相关引擎进一步成熟,也使得日常使用更为便捷。例如在列存储索引方面,现已允许在线地创建或重新构建 (REBUILD) 聚集列存储索引——这将大大方便生产环境中大型列存储表的维护和使用,既能节省存储空间,又能提高后续查询性能。在笔者接触的生产环境中就常有列存储表由于部分行的更新导致碎片问题,但为了保障线上业务的连续性,一直只能使用相对轻量的 REORGANIZE 命令进行简单的维护。该问题有望在数据库升级后彻底解决。
上一代 SQL Server 2017 中引入的图数据引擎在 SQL Server 2019 中也得到了相当幅度的增强。其改进既包括在存储层面支持图数据表和索引使用多 filegroup 进行分区,还新增了极为重要的任意长度模式 (Arbitrary Length Pattern) 支持,用户终于可以表达节点间任意次数的跳跃连通关系了。我们来看一个针对人物关系图的官方查询样例:
SELECT PersonName, Friends FROM ( SELECT Person1.name AS PersonName, STRING_AGG(Person2.name, '->') WITHIN GROUP (GRAPH PATH) AS Friends, LAST_VALUE(Person2.name) WITHIN GROUP (GRAPH PATH) AS LastNode FROM Person AS Person1, friendOf FOR PATH AS fo, Person FOR PATH AS Person2 WHERE MATCH(SHORTEST_PATH(Person1(-(fo)->Person2)+)) AND Person1.name = 'Jacob' ) AS JacobReach WHERE JacobReach.LastNode = 'Alice'
容易理解的是,该查询将能够帮助判断 Jacob 与 Alice 两人是否连通,并给出他们之间的最短关系路径,而这条路径的长度是不确定的。T-SQL 语法上的关键点在于 MATCH 子句:其中使用了一个 SHORTEST_PATH 方法来寻找计算图中两个给定节点间的最短距离。需注意该方法的输入参数支持类似正则表达式语法的不定长模式,通过一个 + 号巧妙地表达了通过 friendOf 关系多次连续寻路,被加号括起的 -(fo)->Person2 即为可多次重复的部分。
上述特性是图数据库应用最常见的高级查询场景之一,数学上被称为传递闭包 (transitive closure)。该特性的加入意味着 SQL Server 2019 在图查询能力方面终于登堂入室,开始逐渐具备与专用图数据库竞争的实力。
商用数据库一向对于硬件领域发展较为关注,不断通过最新的硬件最大化性能潜力。持久性内存 (Persistent Memory, 常缩写为 PMEM) 以其远优于 SSD 硬盘的 IO 能力,成为了当下服务器端硬件的热点之一,英特尔等厂商纷纷大力规划发展如 Optane DC 这样的企业级持久性内存硬件产品。为此,SQL Server 2019 不失时机地推出了混合缓冲池 (Hybrid Buffer Pool) 特性,可让持久性内存作为间于 DRAM 内存和 SSD 硬盘的存储层,在性能攸关的页面缓冲池上发挥显著的加速作用。用户选择开启此特性后,页面缓冲池可扩展到 PMEM 设备上的存储空间,SQL Server 则直接通过内存映射 IO 访问位于 PMEM 设备上的数据页。在许多情况下这样可避免数据页频繁地从传统磁盘拷贝到 DRAM,进行页访问时也能够绕过操作系统的存储协议栈开销,从而取得巨大的性能提升。
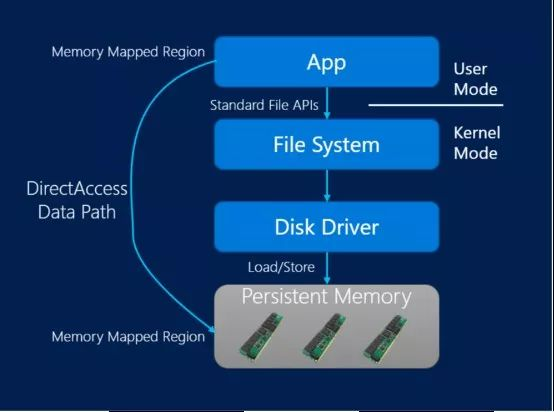
值得一提的是,甲骨文将于明年发布的全新一代 Oracle 20c,同样会提供对于持久性内存的支持——在这一点上,可谓与 SQL Server 英雄所见略同。
我们再来看编程语言集成方面。以往扩展 SQL Server 功能是 C#/.NET 的专利,例如用户可以通过 SQL Server 的 CLR 集成调用.NET 编写的 UDF。随着微软近年来的开放策略持续推进,更多语言进入了 SQL Server 的体系。两年前我们曾介绍 SQL Server 2017 中集成了 Python/R 的环境以方便进行机器学习方面工作,而在 SQL Server 2019 中此次 Java 则成为了主要的集成和支持对象。通过全新的语言扩展体系 (SQL Server Language Extensions) 可使得 Java 类与方法直接在 SQL Server 服务器上本地执行。用户只需要实现微软 Java 扩展 SDK (Microsoft Extensibility SDK for Java) 中的抽象类 AbstractSqlServerExtensionExecutor 即可让自己封装的 Java 代码通过 sp_execute_external_script 存储过程在数据库 T-SQL 上下文中调用运行。
一个与 Java 支持相关的话题是,由于 Oracle 对于 Java 的版权控制和使用条款不断收紧,为避免 SQL Server 中内嵌 Oracle Java 环境带来不必要的限制和风险,微软近期与 Java 开源贡献者和发行商 Azul Systems 达成了一系列合作,使用 Azul Zulu JRE/JDK(基于 OpenJDK)作为 Azure 云和 SQL Server 上 Java 的默认选项。这样 Azure 和 SQL Server 的用户就可获得和使用一款免费且受支持的 Java 运行环境,该环境能够提供安全更新和 Bug 修复,免除了后顾之忧。我们预计类似的做法会逐步成为各大厂的必然选择。这个来自 Azul Systems 的 Java 环境不但有助于上述 SQL Server 的 Java 扩展功能,更会为接下来将介绍的 PolyBase 功能和 SQL Server 大数据集群起到至关重要的支撑作用。
上面涉及的各个新功能,只是 SQL Server 2019 引擎新能力的一部分。事实上新版本还有许多可圈可点的改进,如 APPROX_COUNT_DISTINCT 近似聚合函数、TempDB 元数据的内存化 (Memory-Optimized TempDB Metadata)、UTF-8 字符编码支持、针对行存储的批处理模式 (batch mode on rowstore) 支持以及行模式下的内存分配反馈 (row mode memory grant feedback) 等。这些特性分布于存储执行引擎的各个环节,进一步提升了 SQL Server 的能力和深度。
数据虚拟化
前面提到,支持多模型多范式已经成为商业数据库追求的重要目标之一,以求确立和维护在企业整体数据架构中的核心地位。但在实际情况下,异构数据源总会客观存在,所以从另一个思路上来说,如何加强并便利与异构数据源之间的互联互通,也逐渐成为了现代数据库产品中的重要考量和评定标准。
数据互联互通,最容易想到的就是使用类似 SSIS 和 Azure Data Factory 这样的 ETL 工具来进行定时的数据传输。这固然是行之有效的方法,但存在数据时效性和数据重复等局限。如今相较建立 ETL 通道更为先进的一种理念,就是数据虚拟化。所谓数据虚拟化,顾名思义就是不论数据以具体何种格式存放何处,都能以统一的抽象进行管理和访问。技术上来说,以数据库为核心的数据虚拟化体系主要以声明式的外部表来指向和定义底层数据。
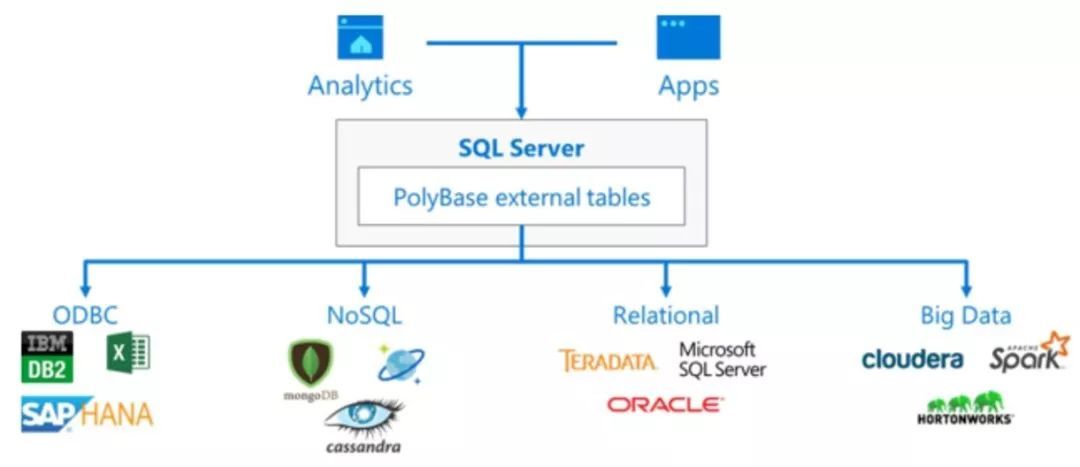
在 SQL Server 2019 版本中,微软将数据虚拟化作为产品核心概念和主要建设目标提出,并在功能层面通过内置的 PolyBase 技术进行了关键支撑和加强。PolyBase 其实并非一个新面孔,它最早出现于 SQL Server 2012 Parallel Data Warehouse 中,服务于这个软硬一体化的分布式 MPP 数据库版本。PolyBase 组件在功能上赋予了数据库层面定义指向 Hadoop/HDFS 数据的外部表的能力,成为帮助打通关系数据库与 Hadoop 大数据生态系统的重要桥梁。在 SQL Server 2016 中 PolyBase 则真正变得成熟并且广为人知,正式出现在了标准 SQL Server 中,大大地拓展了受众。
Polybase 的外联能力在 SQL Server 2019 版本中进一步得到了强化,除原先支持的 Hadoop 和 Azure Blob Storage 外,新版本额外添加了 SQL Server、Oracle、Teradata、MongoDB 和 ODBC 的支持。如果说 PolyBase 之前只是不起眼的附属功能,在强调数据虚拟化的 SQL Server 2019 中已是位居聚光灯下的核心能力。
不妨来看一个在 SQL Server 2019 中使用 PolyBase 配置远端 MongoDB 数据源的简单例子,以此来理解数据虚拟化的落地形态。
CREATE DATABASE SCOPED CREDENTIAL MongoCredential WITH IDENTITY = 'username', SECRET = 'password'; CREATE EXTERNAL DATA SOURCE MongoDBSource WITH ( LOCATION = 'mongodb://<server>[:<port>]', PUSHDOWN = ON, CREDENTIAL = MongoCredential ); CREATE EXTERNAL TABLE MyMongoCollection( [_id] NVARCHAR(24) NOT NULL, [column1] NVARCHAR(MAX) NOT NULL, [column2] INT NOT NULL -- ..., other columns to be mapped ) WITH ( LOCATION='dbname.collectionname', DATA_SOURCE= MongoDBSource );
可以看到,通过 T-SQL 对凭证 (credential)、数据源 (data source)、外部表 (external table) 这三个核心配置进行定义,就可以轻松地将 MongoDB 中的集合与字段映射到 SQL Server 中来,后续即可对虚拟的外部表进行查询。PolyBase 甚至还支持 MongoDB 中的对象、数组等嵌套结构,允许在外部表定义时将复杂字段打平。另外,虽然此处所举的例子是针对 MongoDB,若需连接其他类型数据源,配置的步骤也大致类似,只是相关参数的含义和形式有所不同。
值得注意的是,PolyBase 加持下的外部表使用起来与一般数据表无异,能够与其他表进行 join 等操作,这大大方便了异构数据源之间的集成,许多情况下能够免除数据搬运的麻烦。当然,对于一些出于性能原因不便直接查询的场景,也可用简单的 SQL 语句将外部表数据方便地同步到 SQL Server 内部。
在技术实现层面,PolyBase 由于脱胎于 MPP 架构场景,所以其实具备很好的并行扩展能力——当远端数据体量巨大时这一特性殊为重要,能够极大地加速查询的执行。用户可以设立多个 SQL Server 实例(分为头节点和计算节点)并编组为 PolyBase Scale-out Group 来协同工作,对外部大数据进行并行读取和处理。从这个层面来看,PolyBase 模块已使 SQL Server 具备了分布式分析型数据库的一些典型特征。
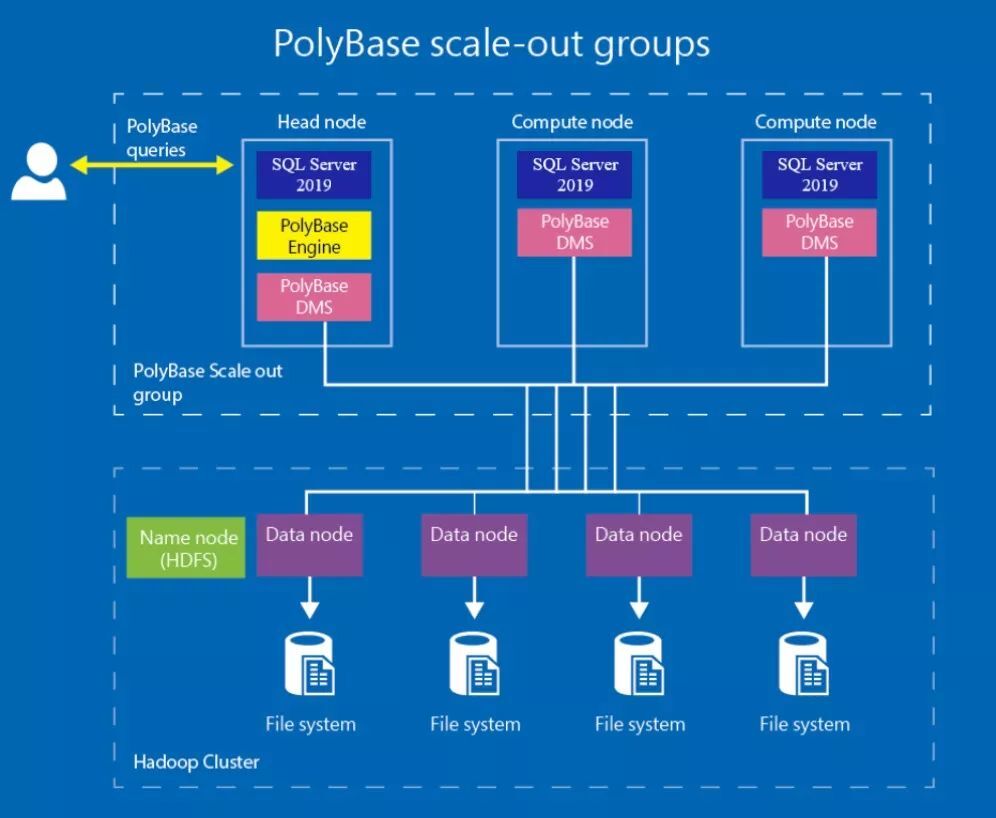
PolyBase 的另一个特点,是具备一定的查询下推 (pushdown) 能力,在远端能够支持的情况下,查询处理器会将符合条件的谓词发送到数据源端进行就近处理,既提高查询性能同时也减轻网络 IO 的负担。例如,在面向 Hadoop 的读取场景下,有时 PolyBase 会根据统计信息选择使用 MapReduce 来读取过滤原始文件,最终只需传回部分结果数据而非全量数据。
综上所述,数据虚拟化的理念和 PolyBase 技术的增强,有望帮助新一代 SQL Server 成为数据架构的中心。通过捏合和集成多种异构数据源,SQL Server 2019 可有效降低企业架构复杂性,还能在数据冷热分层、统一数据湖构建等应用场景中大显身手。
SQL Server 大数据集群
SQL Server 2019 最值得一提的重磅特性,恐怕就要数 SQL Server 大数据集群了(SQL Serve Big Data Cluster)。凭借创造性地将 Hadoop 和 Spark 等开源大数据技术组件直接纳入 SQL Server 并在 Kubernetes 体系下无缝集成的大胆设计,SQL Server 大数据集群在去年一经宣布并开始有限预览后,即引起了广泛关注。因为大家都非常好奇:大数据、Hadoop、Spark、容器化、云原生这些炙手可热的技术热词将如何与一个传统商业数据库发生化学反应呢?
SQL Server 大数据集群本质上既是 SQL Server 2019 的一个新特性,也是一种新的产品形态和部署方式。它具有以下几个重要特点:(1) 将 SQL Server 以多实例形态进行部署和联动,实现数据的分布式存储、处理和计算 (2) 将 SQL Server 完全容器化并以 Kubernetes 为基础架构实现底层计算资源的编排和管理 (3) 在自有分布式存储基础上额外内置提供了标准 HDFS 分布式文件系统 (4) 在计算层面额外提供了标准 Spark 作为分布式计算引擎。其架构概览图如下所示:
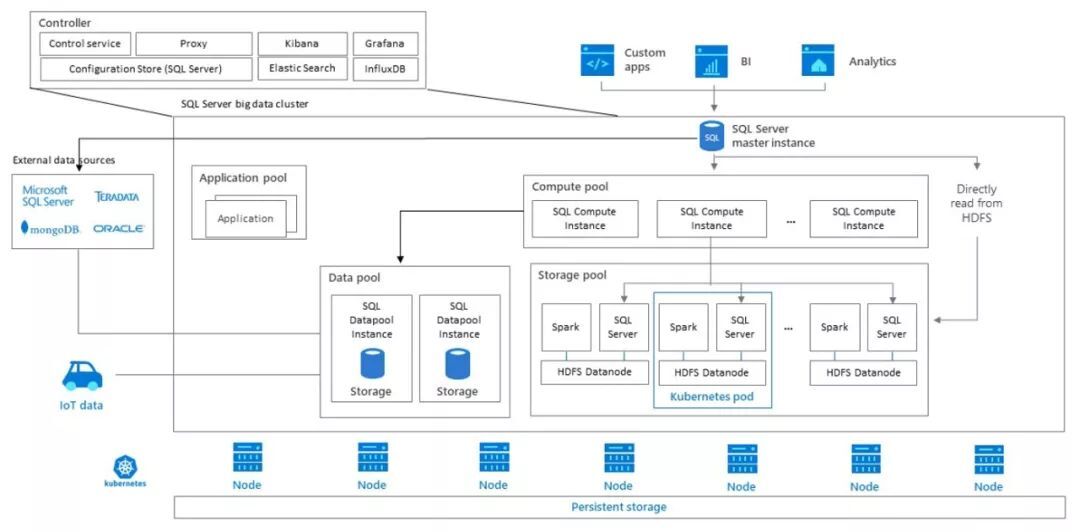
可以看到,SQL Server 大数据集群代表了微软数据平台最新的架构思想,从单纯的与外部互联互通,走向了与开源平台技术的全面融合;从技术对接与兼容,走向了你中有我、我中有你。这不能不说是一个大胆的尝试,也是一个令人拍案叫绝的产品思路。它的好处显而易见:从企业客户角度来说 all-in-one 的设计大幅简化了架构,用户可基于此建设自己的一站式大数据平台,开源与商业技术两者兼得;从微软角度而言,确保了开源工作负载在 SQL Server 集群和体系内顺利运行,类似一个商业 Hadoop 发行版本,无疑有利于其在开源时代继续获得商业上的成功。
如果想体验 SQL Server 2019,最简便的方法是先建立一个 Azure Kubernetes Service(AKS) 集群(当然也支持其他云或本地 K8s 集群),然后借助 azdata 命令行工具即可一键将 SQL Server 大数据集群部署至 Kubernetes。笔者进行了相关的动手实验和架构观察,发现 SQL Server 大数据集群在技术实现上可谓颇具看点,列举部分如下:
- 控制、计算、存储等各节点实现了完全容器化,部署时可自动从微软容器注册表 (Microsoft Container Registry) 下载相应镜像并运行。
- 大数据集群的 master 实例支持多节点部署和高可用,通过结合 K8s 提供的底层故障检测转移能力和 SQL Server 中的可用性组 (Availability Group) 共同实现。
- 分布式存储底层由 VM 集群挂载的磁盘组合构成,向上提供了两种不同选择 Data Pool 和 Storage Pool,分别对应私有和开源技术。使用时通过定义外部表指向 sqldatapool 或 sqlhdfs 协议下的地址进行挂载和访问。两种不同的存储可以结合使用,互相配合。
- Data Pool 提供了 SQL Server 自有的分布式存储能力,一般配合 ROUND-ROBIN 数据分布策略,可提供较高的数据加载性能。实际场景中可作为外部数据接入时的落地选择,也可作为大查询结果集的持久化存储。
- Storage Pool 对应的 Pod 高度集成了 Spark、HDFS DataNode 和 SQL Server 实例,对外提供了一个完整的 HDFS 文件系统,可完美兼容使用 Parquet 等开源体系的列存储格式,还能通过 HDFS tiering 功能挂载使用 Amazon S3、Azure Data Lake Storage Gen2 等云端存储服务;查询时 SQL Server 能够通过 NameNode 提供的信息进行尊重 data locality 的本地高速读取,还能够在许多情况下支持谓词下推 (predicate pushdown)。
- 大数据集群全面集成 Spark 运行环境意义重大,意味着可使用标准 Spark 技术栈读写 Storage Pool,与 SQL Server 就地共享同一份数据。经验证此次发布集成的 Spark 版本为 2.4,是最新的大版本。
- 大数据集群自动安装包含了 Elasticsearch 和 Kibana 组件,帮助监控系统各环节的关键指标与健康状态。
- 工具支持方面可使用跨平台的 Azure Data Studio 连接 SQL Server 大数据集群,SQL Server 2019 专用插件大大方便了自助查询、集群管理、外部表创建等工作。还可在 Azure Data Studio 中使用广受欢迎的 Jupyter Notebook 连接到集群,通过 SQL、Python/PySpark 或 Scala/Spark 脚本进行探索式数据分析和机器学习模型训练。
限于篇幅,更多内容此处不再展开。若大家对其中一些关键细节和动手实操感兴趣,可关注笔者微信公众号“云间拾遗”的后续文章了解更多信息。
在定价方面,虽然 SQL Server 大数据集群仍属商用数据库范畴,且占用 CPU 核心数较多,但用户不必过于担心在授权费用方面的高额支出。SQL Server 团队贴心地设计了成本友好的定价策略,主要体现为除 master 实例需要 Enterprise 或 Standard 版本授权外,其他占大多数的 computer/data/storage 节点只需要按照专门设计且便宜许多的“Big Data Node”的方式进行计费,这会大大减轻用户在选用 SQL Server 大数据集群后的成本负担。
回过头来看,SQL Server 大数据集群虽然是全新的能力,但也许微软其实早早就开始了相关布局。因为容易发现 SQL Server 之前版本的一些成果,恰恰是此次大数据集群得以横空出世的技术前提。比如前面提到的历经多年积累的 PolyBase 技术,正是 SQL Server 得以和大数据技术栈无缝交互的关键;又如 SQL Server 2017 开始引入的 Linux 版本,则是容器化封装得以顺利达成的重要基础条件。
微软近年来全面拥抱开源之后,正在逐渐获得回报。拥抱开源既能够拉近与社区和用户的距离,也为最新的技术产品发展赢得了更大的设计灵活度。此次彻底容器化、使用 Kubernetes 进行编排并集成 Spark、HDFS 等开源组件的 SQL Server 大数据集群,无疑也是这种“改革开放”和“拿来主义”策略的成功典范。
当然,任何事物都有其两面性。对于 SQL Server 大数据集群这样的一体化架构模式,也有个别业界人士持有不同观点,认为过度整合封装未必是云时代的架构演化方向,他们更倾向于计算存储分离的架构,让每个数据组件专注做好一件事情。这就是一个仁者见仁智者见智的问题了。也许 SQL Server 大数据集群的设计初衷更侧重基于本地部署的大型客户,同时吸引对可迁移性和跨云适配十分敏感的企业解决方案提供商——对这些场景而言,SQL Server 大数据集群不失为极具竞争力的选择。相信市场会给予我们最终的答案。
总结
世界即将跨入新的十年。在 2019 年末发布的 SQL Server 2019,展现了微软在新时代对下一个十年的展望和雄心。尤其是 SQL Server 大数据集群的推出,相信将促成一批全新大数据平台的落地,也会启发业界思考未来大数据的架构模式,以及商业技术与开源世界和谐并存之道。
值得一提的是,SQL Server 2019 与 SQL Server 2017 一样,拥有面向 Linux 的版本,并与 Linux 厂商一起提供官方的支持服务。事实上 SQL Server 对 Linux 的特性覆盖也一直在默默地持续改进,2019 版本为 Linux 带来了数据复制、Active Directory 集成、PolyBase on Linux 等重要特性。如果大家对于两年前的首个 Linux 版本还持观望态度的话,SQL Server 2019 对于 Linux 的兼容性和功能集合已经完善了许多,是一个更好的 SQL Server for Linux,或许是时候可以“上车”了。
以云为先的微软,除了云原生化 SQL Server 2019 本身外,也必然会考虑将新一代版本的新能力逐渐同步到 Azure 云的 PaaS 服务上。其实 Azure SQL Database 已经开始支持 SQL Server 2019 中如 APPROX_COUNT_DISTINCT 等部分新特性了,只需手动设置数据库的兼容性等级 (compatibility level) 为对应 2019 版本的 150 即可。再者如 PolyBase,之前在 Azure 上仅有 SQL Data Warehouse 提供了支持(主要用于访问 Blob Storage),后续该特性很可能会在云端得到相应的更新增强,也期待它拓展到 SQL Databases 或 SQL Managed Instance 等更多数据服务中。
最后,我们简要地总结 SQL Server 2019 的发展策略如下:首先继续夯实了原生支持多种数据架构范式的多模内核,其次是不断改进数据虚拟化技术 PolyBase 以强化外部联接,最后通过拥抱和纳入开源大数据技术体系实现整体融合。这是一个稳步发展、层层递进的产品进化思路。不知作为用户的你,是否已经心动?让我们祝 SQL Server 2019 好运。
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑对应用场景进行深度解读。欢迎扫描下方二维码关注“云间拾遗”微信公众号。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号