


寻觅Azure上的Athena和BigQuery (二):神奇的PolyBase

前情回顾
在“数据湖”概念与理论逐渐深入人心的今天,面向云存储的交互式查询这个需求场景显得愈发重要。这是因为原生的云存储(主要指S3这样的对象存储)既能够容纳大容量的明细数据,又能在性能和成本间取得一个很好的平衡——如果它同时再支持复杂的即席分析查询,那么云原生存储就将成为数据湖的最佳载体,对于实现数据分析人员的自由探索和应用系统的查询集成都有着非常重要的意义。
因此,在上一篇文章中,我们围绕着这个重要需求场景如何在Azure进行实现详细地展开了我们的探索。首先作为参照,我们在AWS环境中利用S3和Athena成功地对一个csv文件进行了SQL查询。随后,我们主要使用Azure Data Lake Analytics (ADLA)配合Azure Data Lake Storage (ADLS)作存储来实现了同样的分析需求。值得注意的是,ADLA支持的查询语言是U-SQL,一种混合了C#与SQL语法的独特语言。
然而,也如前文所提到,ADLA还是存在一些固有局限,也并未在Azure中国区上线。故而我们有必要考虑和寻找Azure体系内的其他选择。今天的参赛选手,是源自SQL Server体系的PolyBase。
初识PolyBase
其实PolyBase这个称谓最早出现于SQL Server 2012 Parallel Data Warehouse(PDW)中,该版本本质上是一个软硬一体化的分布式MPP数据库。PolyBase组件赋予了在数据库层面定义指向Hadoop/HDFS数据的外部表的能力,是帮助打通MPP数据库与Hadoop大数据生态系统的重要桥梁。
而PolyBase真正变得成熟并且广为人知,是自SQL Server 2016起,PolyBase技术正式地出现在了标准SQL Server中,毕竟PDW版本的受众不够广泛。此举大大提升了SQL Server在大数据时代的综合竞争力,使得微软体系内的用户通过T-SQL即可轻松地访问和获取Hadoop集群中的数据。
那么,说了一大圈,源自SQL Server的PolyBase和Azure有什么关系,和我们今天的话题有什么关系呢?这就得说到在微软全面云化的战略之下,SQL Server其实也以多种不同形式迁移到了Azure云端,形成了若干款不同的云端数据服务产品(详情参见笔者介绍SQL Server 2017的文章)。而PolyBase自然也一起被带到了云端,并在支持访问HDFS的基础上还添加了访问云存储的能力,这样我们就可以通过PolyBase和大家熟悉的T-SQL语言来轻松实现面向云存储的交互式查询了。
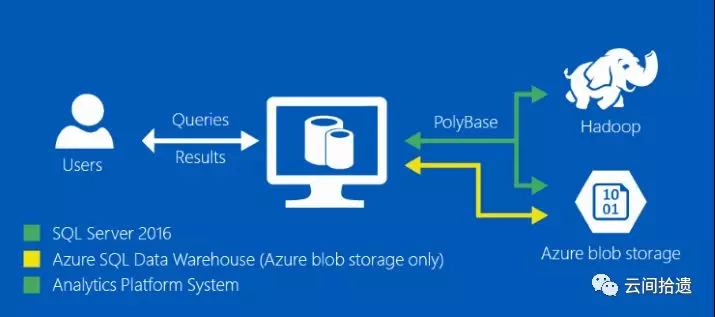
(图片来源:微软PolyBase官方文档)
动手体验
让我们进入实践环节。首先我们需要寻找一个Azure上PolyBase技术的载体。SQL Server的Azure变体中有SQL Database、SQL Managed Instance、SQL Data Warehouse等相关产品,但支持通过PolyBase访问云存储的目前仅有SQL Data Warehouse(下简称SQL DW)这一款。我们就选择它作为查询引擎。
首先我们准备一下实验所需的数据,我们同样沿用上篇文章中的包含信用卡借贷数据的csv文件,把它放置到存储账户的Blob中。我们确认一下它的位置是在cloudpickersa这个存储账户的sampledata容器中:
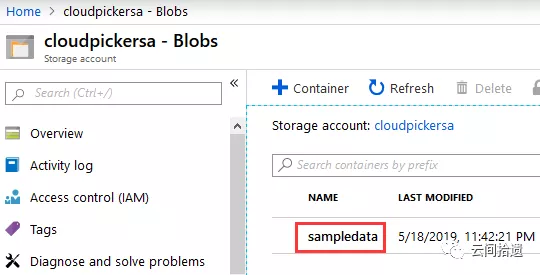

接下来让我们请出今天的主角,创建一个SQL DW数据库(本实验使用美国西区资源,但相关服务均已在Azure中国上线),使用最新的Gen2版本:

创建完成之后,就可以使用大家所熟悉的SQL Server Management Studio(SSMS)进行连接了,除了个别图标不同,其使用体验与传统SQL Server几乎完全一致。
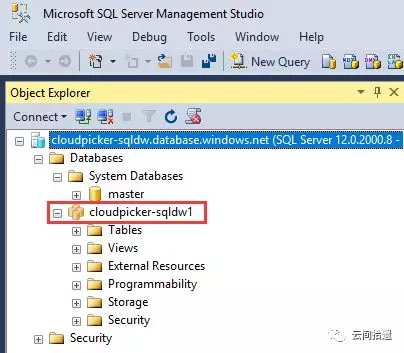
与Athena类似,PolyBase同样是通过定义外部表的方式来对云存储中的数据和格式进行映射的。我们来看一下具体的步骤。
第一步,需要在刚才新建的数据库里建立一个credential用以实现与指定存储账号访问权限的对应:
CREATE MASTER KEY ENCRYPTION BY PASSWORD='MyPassw0rd'; CREATE DATABASE SCOPED CREDENTIAL CloudpickerCredential WITH IDENTITY = 'cloudpickersa' , SECRET = 'j2PJqjIR1IfkDEESjWEIFzcgip...accesskeyismysupersecret...5VeqM2B+1bCWFosyvm4Kg==' ; --此处secret为存储账户设置中生成的access key
第二步,需要创建一个“数据源”用以指向存储账号下的具体容器,并指定数据源的类型。这里会用到第一步创建的credential:
CREATE EXTERNAL DATA SOURCE CloudpickerStorage_SampleData WITH ( LOCATION = 'wasbs://sampledata@cloudpickersa.blob.core.windows.net/' , CREDENTIAL = CloudpickerCredential , TYPE = HADOOP );
这里的参数"TYPE=HADOOP"其实耐人寻味,因为我们实际要连接的是Azure Blob Storage,而非HDFS。这隐含地说明PolyBase事实上是先支持Hadoop,后来才把Azure存储以一种HDFS兼容的方式加入了支持。LOCATION中使用的wasb协议也印证了这一点,因为wasb本来就用于让Azure Blob存储挂载和融入到Hadoop体系中。
第三步,则是先定义数据格式,然后终于可以创建外部表并指向具体的csv文件。这里会用到第二步创建的数据源:
CREATE EXTERNAL FILE FORMAT MyFileFormat_CSV WITH (FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS( FIELD_TERMINATOR = ',', FIRST_ROW = 2, USE_TYPE_DEFAULT = False) ); CREATE EXTERNAL TABLE credit_card_loans( "year" INT, periodicity VARCHAR(20), "quarter" VARCHAR(20), load_type VARCHAR(MAX), loan_value DECIMAL(20,8) ) WITH ( LOCATION='/credit_card_loans.csv', DATA_SOURCE = CloudpickerStorage_SampleData, FILE_FORMAT = MyFileFormat_CSV ) ;
这才算是大功告成。可以看到,在PolyBase中需要层层递进地创建凭据、数据源、外部表这些重要实体,这是与严谨的SQL Server/T-SQL抽象体系相对应的。
我们迫不及待地来尝试一下外部表访问csv的效果。先做一个简单的计数: 
嗯,颇为顺畅。再来一个与前篇文章相同的查询,这次使用T-SQL来表达:

也很快地返回了正确的结果。关于PolyBase的查询性能,由于牵涉到的因素会比较多,需要专题探讨,在此不作重点讨论。就这里的例子而言,第一次的冷查询会相对较慢,之后对同一外部表的各种查询就比较快了,可以秒级返回。
至此,我们已完整地使用Azure SQL DW中的PolyBase能力实现了对Blob Storage的即席查询,实现了与前文例子中相同的效果。
小结
来自关系型数据库世界的PolyBase,赋能用户使用T-SQL直接访问查询Azure云存储中的数据文件,可谓神奇。这也许乍一听上去是“曲线救国”,但真正实操下来其实相当方便,圆满完成了面向云存储的交互式查询的既定任务。
在PolyBase的帮助下,开发者和数据分析师们可以通过熟悉的SSMS或Azure Data Studio等客户端工具随时连接和查询云上大数据了。如果再考虑到SQL Server体系中ADO.NET/JDBC/ODBC等方便而成熟的访问接口,PolyBase还不失为一个生产应用集成云上大数据的优美方式,既可用于数据搬运,也可直查数据湖。PolyBase对于调用方而言也较为友好,因为访问外部表和普通的内部数据表并无二致,间接实现了异构数据源的统一封装和访问。
在本系列文章中,ADLA和PolyBase都已分别登场,各自展现了不逊于Athena的特点和能力。但在Azure上还有第三个选项,同样具备很强的竞争力,我们留待下回分解。
“云间拾遗”专注于从用户视角介绍云计算产品与技术,坚持以实操体验为核心输出内容,同时结合产品逻辑对应用场景进行深度解读。欢迎扫描下方二维码关注“云间拾遗”微信公众号,或订阅本博客。


