Redis 缓存穿透 + 缓存雪崩 + 缓存击穿的原因和解决方案
在生产环境中,会因为很多的原因造成访问请求绕过了缓存,都需要访问数据库持久层,
虽然对Redsi缓存服务器不会造成影响,但是数据库的负载就会增大,使缓存的作用降低
一、缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和持久层都不会命中。在日常工作中出于容错的考虑,
如果从持久层查不到数据则不写入缓存层,缓存穿透将导致不存在的数据每次请求都要到持久层去查询,失去了缓存保护后端持久的意义
缓存穿透示意图:

缓存穿透问题可能会使后端存储负载加大,由于很多后端持久层不具备高并发性,甚至可能造成后端存储宕机。通常可以在程序中统计总调用数、缓存层命中数、如果同一个Key的缓存命中率很低,可能就是出现了缓存穿透问题。
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题(例如:set 和 get 的key不一致),第二,一些恶意攻击、爬虫等造成大量空命中(爬取线上商城商品数据,超大循环递增商品的ID)
解决方案:
1. 缓存空对象
缓存空对象:是指在持久层没有命中的情况下,对key进行set (key,null)
缓存空对象会有两个问题:第一,value为null 不代表不占用内存空间,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间,比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象
2. 布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,当收到一个对key请求时先用布隆过滤器验证是key否存在,如果存在在进入缓存层、存储层。可以使用bitmap做布隆过滤器。这种方法适用于数据命中不高、数据相对固定、实时性低的应用场景,代码维护较为复杂,但是缓存空间占用少。
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
算法描述:
初始状态时,BloomFilter是一个长度为m的位数组,每一位都置为0。
添加元素x时,x使用k个hash函数得到k个hash值,对m取余,对应的bit位设置为1。
判断y是否属于这个集合,对y使用k个哈希函数得到k个哈希值,对m取余,所有对应的位置都是1,则认为y属于该集合(哈希冲突,可能存在误判),否则就认为y不属于该集合。可以通过增加哈希函数和增加二进制位数组的长度来降低错报率。
错报原因:
一个key映射数组上多位,一位会被多个key使用,也就是多对多的关系。如果一个key映射的所有位值为1,就判断为存在。但是可能会出现key1 和 key2 同时映射到下标为100的位,key1不存在,key2存在,这种情况下会发生错误率
方案对比:
二、缓存雪崩
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不可用(宕机)或者大量缓存由于超时时间相同在同一时间段失效(大批key失效/热点数据失效),大量请求直接到达存储层,存储层压力过大导致系统雪崩。
解决方案:
可以把缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务。利用sentinel或cluster实现。
采用多级缓存,本地进程作为一级缓存,redis作为二级缓存,不同级别的缓存设置的超时时间不同,即使某级缓存过期了,也有其他级别缓存兜底
缓存的过期时间用随机值,尽量让不同的key的过期时间不同(例如:定时任务新建大批量key,设置的过期时间相同)
三、缓存击穿
系统中存在以下两个问题时需要引起注意:
当前key是一个热点key(例如一个秒杀活动),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
解决方案:
1. 分布式互斥锁
只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。set(key,value,timeout)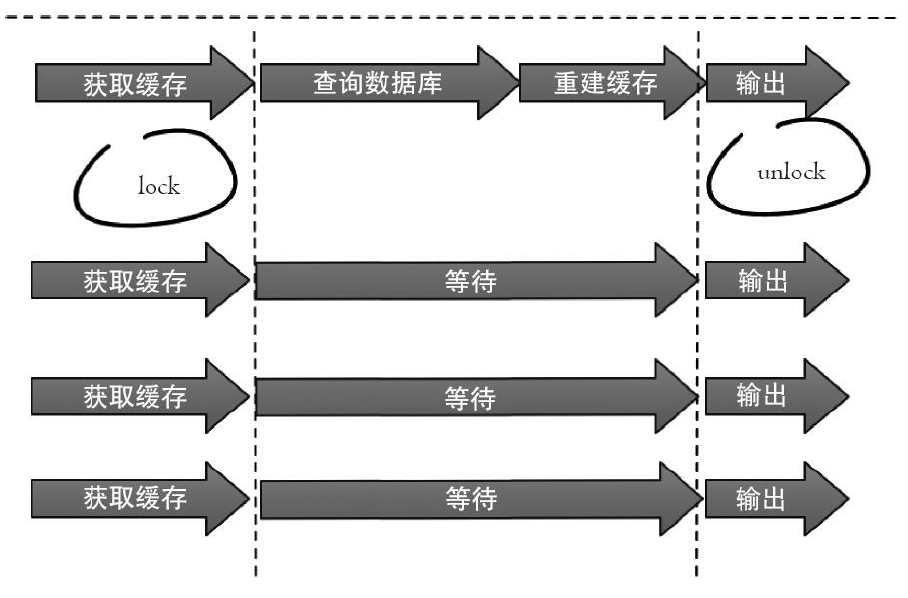
2. 永不过期
- 从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
- 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去更新缓
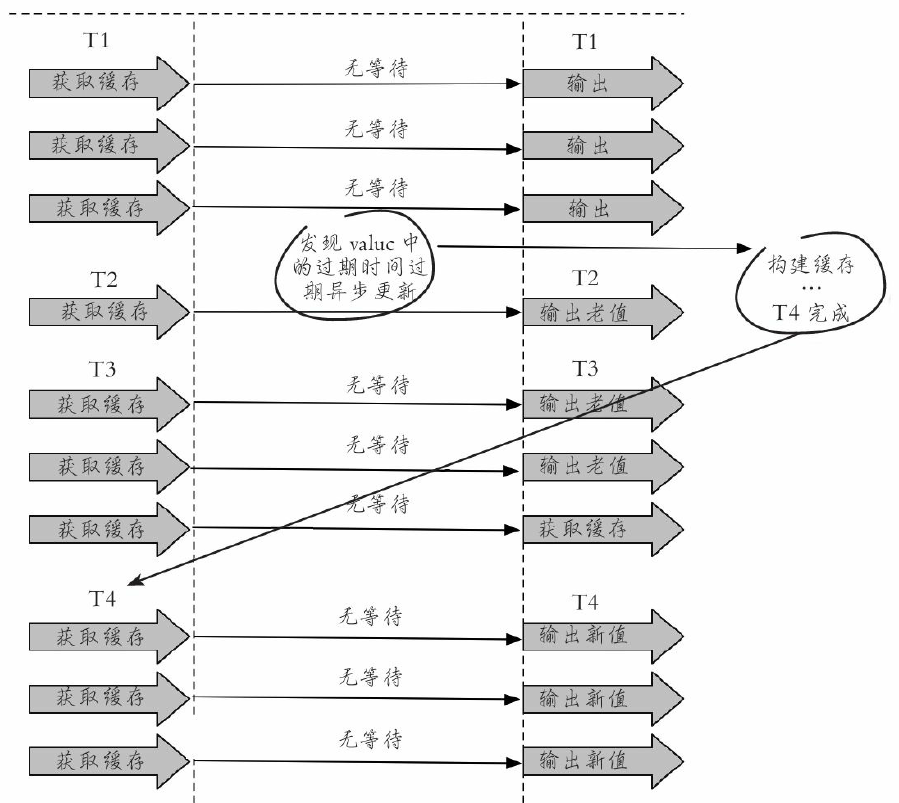
2种方案对比:
分布式互斥锁:这种方案思路比较简单,但是存在一定的隐患,如果在查询数据库 + 和 重建缓存(key失效后进行了大量的计算)时间过长,也可能会存在死锁和线程池阻塞的风险,高并发情景下吞吐量会大大降低!但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
“永远不过期”:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
原文链接:https://blog.csdn.net/womenyiqilalala/article/details/105205532


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律