【转载】看StackOverflow如何用25台服务器撑起5.6亿的月PV
问答社区网络 StackExchange 由 100 多个网站构成,其中包括了 Alexa 排名第 54 的 StackOverflow。StackExchang 有 400 万用户,每月 5.6 亿 PV,但只用 25 台服务器,并且 CPU 负荷并不高。
它没有使用云计算,因为云计算可能会拖慢速度,更难优化和更难排除系统故障。
StackOverflow 仍然使用微软的架构,它非常实际,微软的基础设施能有效工作,又足够廉价,没有令人信服的理由需要做出改变。但这并不表示它不使用 Linux,它将 Linux 用在有意义的地方。
它的 Windows 服务器运行的操作系统版本是 Windows 2012 R2,Linux 服务器运行 Centos 6.4。
网站数据库 MS SQL 大小 2TB,全都储存在 SSD 上,它有 11 台运行 IIS 的 Web 服务器,2 台运行 HAProxy 的负载均衡服务器,2 台运行 Redis 的缓存服务器。
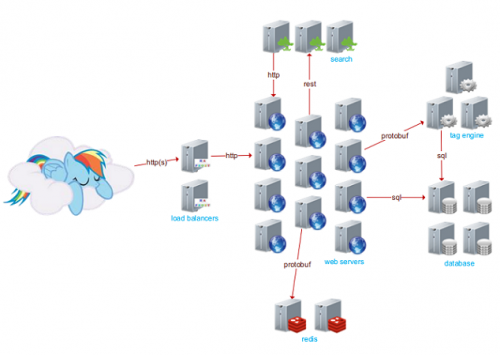
StackOverflow 是一个 IT 技术问答网站,用户可以在网站上提交和回答问题。当下的 StackOverflow 已拥有 400 万个用户,4000 万个回答,月 PV5.6 亿,世界排行第 54。然而值得关注的是,支撑他们网站的全部服务器只有 25 台,并且都保持着非常低的资源使用率,这是一场高有效性、负载均衡、缓存、数据库、搜索及高效代码上的较量。近日,High Scalability 创始人 Todd Hoff 根据 Marco Cecconi 的演讲视频“ The architecture of StackOverflow”以及 Nick Craver 的博文“ What it takes to run Stack Overflow”总结了 StackOverflow 的成功原因。
意料之中,也是意料之外,Stack Overflow 仍然重度使用着微软的产品。他们认为既然微软的基础设施可以满足需求,又足够便宜,那么没有什么理由去做根本上的改变。而在需要的地方,他们同样使用了 Linux。究其根本,一切都是为了性能。
另一个值得关注的地方是,Stack Overflow 仍然使用着纵向扩展策略,没有使用云。他们使用了 384GB 的内存和 2TB 的 SSD 来支撑 SQL Servers,如果使用 AWS 的话,花费可想而知。没有使用云的另一个原因是 Stack Overflow 认为云会一定程度上的降低性能,同时也会给优化和排查系统问题增加难度。此外,他们的架构也并不需要横向扩展。峰值期间是横向扩展的杀手级应用场景,然而他们有着丰富的系统调整经验去应对。该公司仍然坚持着 Jeff Atwood 的名言——硬件永远比程序员便宜。
Marco Ceccon 曾提到,在谈及系统时,有一件事情必须首先弄明白——需要解决问题的类型。首先,从简单方面着手,StackExchange 究竟是用来做什么的——首先是一些主题,然后围绕这些主题建立社区,最后就形成了这个令人敬佩的问答网站。
其次则是规模相关。StackExchange 在飞速增长,需要处理大量的数据传输,那么这些都是如何完成的,特别是只使用了 25 台服务器,下面一起追根揭底:
状态
- StackExchange 拥有 110 个站点,以每个月 3 到 4 个的速度增长。
- 400 万用户
- 800 万问题
- 4000 万答案
- 世界排名 54 位
- 每年增长 100%
- 月 PV 5.6 亿万
- 大多数工作日期间峰值为 2600 到 3000 请求每秒,作为一个编程相关网站,一般情况下工作日的请求都会高于周末
- 25 台服务器
- SSD 中储存了 2TB 的 SQL 数据
- 每个 web server 都配置了 2 个 320G 的 SSD,使用 RAID 1
- 每个 ElasticSearch 主机都配备了 300GB 的机械硬盘,同时也使用了 SSD
- Stack Overflow 的读写比是 40:60
- DB Server 的平均 CPU 利用率是 10%
- 11 个 web server,使用 IIS
- 2 个负载均衡器,1 个活跃,使用 HAProxy
- 4 个活跃的数据库节点,使用 MS SQL
- 3 台实现了 tag engine 的应用程序服务器,所有搜索都通过 tag
- 3 台服务器通过 ElasticSearch 做搜索
- 2 台使用了 Redis 的服务器支撑分布式缓存和消息
- 2 台 Networks(Nexus 5596 + Fabric Extenders)
- 2 Cisco 5525-X ASAs
- 2 Cisco 3945 Routers
- 主要服务 Stack Exchange API 的 2 个只读 SQL Servers
- VM 用于部署、域控制器、监控、运维数据库等场合
平台
- ElasticSearch
- Redis
- HAProxy
- MS SQL
- Opserver
- TeamCity
- Jil——Fast .NET JSON Serializer,建立在 Sigil 之上
- Dapper——微型的 ORM
UI
- UI 拥有一个信息收件箱,用于新徽章获得、用户发送信息、重大事件发生时的信息收取,使用 WebSockets 实现,并通过 Redis 支撑。
- 搜索箱通过 ElasticSearch 实现,使用了一个 REST 接口。
- 因为用户提出问题的频率很高,因此很难显示最新问题,每秒都会有新的问题产生,从而这里需要开发一个关注用户行为模式的算法,只给用户显示感兴趣的问题。它使用了基于 Tag 的复杂查询,这也是开发独立 Tag Engine 的原因。
- 服务器端模板用于生成页面。
服务器
- 25 台服务器并没有满载,CPU 使用率并不高,单计算 SO(Stack Overflow)只需要 5 台服务器。
- 数据库服务器资源利用率在 10% 左右,除下执行备份时。
- 为什么会这么低?因为数据库服务器足足拥有 384GB 内存,同时 web server 的 CPU 利用率也只有 10%-15%。
- 纵向扩展还没有遇到瓶颈。通常情况下,如此流量使用横向扩展大约需要 100 到 300 台服务器。
- 简单的系统。基于 .Net,只用了 9 个项目,其他系统可能需要 100 个。之所以使用这么少系统是为了追求极限的编译速度,这点需要从系统开始时就进行规划,每台服务器的编译时间大约是 10 秒。
- 11 万行代码,对比流量来说非常少。
- 使用这种极简的方式主要基于几个原因。首先,不需要太多测试,因为 Meta.stackoverflow 本来就是一个问题和 bug 讨论社区。其次,Meta.stackoverflow 还是一个软件的测试网站,如果用户发现问题的话,往往会提出并给予解决方案。
- 纽约数据中心使用的是 Windows 2012,已经向 2012 R2 升级(Oregon 已经完成了升级),Linux 系统使用的是 Centos 6.4。
SSD
- 默认使用的是 Intel 330(Web 层等)
- Intel 520 用于中间层写入,比如 Elastic Search
- 数据层使用 Intel 710 和 S3700
- 系统同时使用了 RAID 1 和 RAID 10(任何4+ 以上的磁盘都使用 RAID 10)。不畏惧故障发生,即使生产环境中使用了上千块 2.5 英寸 SSD,还没碰到过一块失败的情景。每个模型都使用了 1 个以上的备件,多个磁盘发生故障的情景不在考虑之中。
- ElasticSearch 在 SSD 上表现的异常出色,因为 SO writes/re-indexes 的操作非常频繁。
- SSD 改变了搜索的使用方式。因为锁的问题,Luncene.net 并不能支撑 SO 的并发负载,因此他们转向了 ElasticSearch。在全 SSD 环境下,并不需要围绕 Binary Reader 建立锁。
高可用性
- 异地备份——主数据中心位于纽约,备份数据中心在 Oregon。
- Redis 有两个从节点,SQL 有 2 个备份,Tag Engine 有 3 个节点,elastic 有 3 个节点,冗余一切,并在两个数据中心同时存在。
- Nginx 是用于 SSL,终止 SSL 时转换使用 HAProxy。
- 并不是主从所有,一些临时的数据只会放到缓存中
- 所有 HTTP 流量发送只占总流量的 77%,还存在 Oregon 数据中心的备份及一些其他的 VPN 流量。这些流量主要由 SQL 和 Redis 备份产生。
数据库
- MS SQL Server
- Stack Exchange 为每个网站都设置了数据库,因此 Stack Overflow 有一个、Server Fault 有一个,以此类推。
- 在纽约的主数据中心,每个集群通常都使用 1 主和 1 只读备份的配置,同时还会在 Oregon 数据中心也设置一个备份。如果是运行的是 Oregon 集群,那么两个在纽约数据中心的备份都会是只读和同步的。
- 为其他内容准备的数据库。这里还存在一个“网络范围”的数据库,用于储存登陆凭证和聚合数据(大部分是 stackexchange.com 用户文件或者 API)。
- Careers Stack Overflow、stackexchange.com 和 Area 51 等都拥有自己独立的数据库模式。
- 模式的变化需要同时提供给所有站点的数据库,它们需要向下兼容,举个例子,如果需要重命名一个列,那么将非常麻烦,这里需要进行多个操作:增加一个新列,添加作用在两个列上的代码,给新列写数据,改变代码让新列有效,移除旧列。
- 并不需要分片,所有事情通过索引来解决,而且数据体积也没那么大。如果有 filtered indexes 需求,那么为什么不更高效的进行?常见模式只在 DeletionDate = Null 上做索引,其他则通过为枚举指定类型。每项 votes 都设置了 1 个表,比如一张表给 post votes,1 张表给 comment votes。大部分的页面都可以实时渲染,只为匿名用户缓存,因此,不存在缓存更新,只有重查询。
- Scores 是非规范化的,因此需要经常查询。它只包含 IDs 和 dates,post votes 表格当下大约有 56454478 行,使用索引,大部分的查询都可以在数毫秒内完成。
- Tag Engine 是完全独立的,这就意味着核心功能并不依赖任何外部应用程序。它是一个巨大的内存结构数组结构,专为 SO 用例优化,并为重负载组合进行预计算。Tag Engine 是个简单的 windows 服务,冗余的运行在多个主机上。CPU 使用率基本上保持在2-5%,3 个主机专门用于冗余,不负责任何负载。如果所有主机同时发生故障,网络服务器将把 Tag Engine 加载到内存中持续运行。
- 关于 Dapper 无编译器校验查询与传统 ORM 的对比。使用编译器有很多好处,但在运行时仍然会存在 fundamental disconnect 问题。同时更重要的是,由于生成 nasty SQL,通常情况还需要去寻找原始代码,而 Query Hint 和 parameterization 控制等能力的缺乏更让查询优化变得复杂。
编码
- 流程
- 大部分程序员都是远程工作,自己选择编码地点
- 编译非常快
- 然后运行少量的测试
- 一旦编译成功,代码即转移至开发交付准备服务器
- 通过功能开关隐藏新功能
- 在相同硬件上作为其他站点测试运行
- 然后转移至 Meta.stackoverflow 测试,每天有上千个程序员在使用,一个很好的测试环境
- 如果通过则上线,在更广大的社区进行测试
- 大量使用静态类和方法,为了更简单及更好的性能
- 编码过程非常简单,因为复杂的部分被打包到库里,这些库被开源和维护。.Net 项目数量很低,因为使用了社区共享的部分代码。
- 开发者同时使用 2 到 3 个显示器,多个屏幕可以显著提高生产效率。
缓存
- 缓存一切
- 5 个等级的缓存
- 1 级是网络级缓存,缓存在浏览器、CDN 以及代理服务器中。
- 2 级由 .Net 框架 HttpRuntime.Cache 完成,在每台服务器的内存中。
- 3 级 Redis,分布式内存键值存储,在多个支撑同一个站点的服务器上共享缓存项。
- 4 级 SQL Server Cache,整个数据库,所有数据都被放到内存中。
- 5 级 SSD。通常只在 SQL Server 预热后才生效。
- 举个例子,每个帮助页面都进行了缓存,访问一个页面的代码非常简单:
- 使用了静态的方法和类。从 OOP 角度来看确实很糟,但是非常快并有利于简洁编码。
- 缓存由 Redis 和 Dapper 支撑,一个微型 ORM
- 为了解决垃圾收集问题,模板中 1 个类只使用 1 个副本,被建立和保存在缓存中。监测一切,包括 GC 操。据统计显示,间接层增加 GC 压力达到了某个程度时会显著的降低性能。
- CDN Hit 。鉴于查询字符串基于文件内容进行哈希,只在有新建立时才会被再次取出。每天 3000 万到 5000 万 Hit,带宽大约为 300GB 到 600GB。
- CDN 不是用来应对 CPU 或I/O负载,而是帮助用户更快的获得答案
部署
- 每天 5 次部署,不去建立过大的应用。主要因为
- 可以直接的监视性能
- 尽可能最小化建立,可以工作才是重点
- 产品建立后再通过强大的脚本拷贝到各个网页层,每个服务器的步骤是:
- 通过 POST 通知 HAProxy 下架某台服务器
- 延迟 IIS 结束现有请求(大约 5 秒)
- 停止网站(通过同一个 PSSession 结束所有下游)
- Robocopy 文件
- 开启网站
- 通过另一个 POST 做 HAProxy Re-enable
- 几乎所有部署都是通过 puppet 或 DSC,升级通常只是大幅度调整 RAID 阵列并通过 PXE boot 安装,这样做非常快速。
协作
- 团队
- SRE (System Reliability Engineering):5 人
- Core Dev(Q&A site)6-7 人
- Core Dev Mobile:6 人
- Careers 团队专门负责 SO Careers 产品开发:7 人
- Devops 和开发者结合的非常紧密
- 团队间变化很大
- 大部分员工远程工作
- 办公室主要用于销售,Denver 和 London 除外
- 一切平等,些许偏向纽约工作者,因为面对面有助于工作交流,但是在线工作影响也并不大
- 对比可以在同一个办公室办公,他们更偏向热爱产品及有才华的工程师,他们可以很好的衡量利弊
- 许多人因为家庭而选择远程工作,纽约是不错,但是生活并不宽松
- 办公室设立在曼哈顿,那是个人才的诞生地。数据中心不能太偏,因为经常会涉及升级
- 打造一个强大团队,偏爱极客。早期的微软就聚集了大量极客,因此他们征服了整个世界
- Stack Overflow 社区也是个招聘的地点,他们在那寻找热爱编码、乐于助人及热爱交流的人才。
编制预算
- 预算是项目的基础。钱只花在为新项目建立基础设施上,如此低利用率的 web server 还是 3 年前数据中心建立时购入。
测试
- 快速迭代和遗弃
- 许多测试都是发布队伍完成的。开发拥有一个同样的 SQL 服务器,并且运行在相同的 Web 层,因此性能测试并不会糟糕。
- 非常少的测试。Stack Overflow 并没有进行太多的单元测试,因为他们使用了大量的静态代码,还有一个非常活跃的社区。
- 基础设施改变。鉴于所有东西都有双份,所以每个旧配置都有备份,并使用了一个快速故障恢复机制。比如,keepalived 可以在负载均衡器中快速回退。
- 对比定期维护,他们更愿意依赖冗余系统。SQL 备份用一个专门的服务器进行测试,只为了可以重存储。计划做每两个月一次的全数据中心故障恢复,或者使用完全只读的第二数据中心。
- 每次新功能发布都做单元测试、集成测试盒 UI 测试,这就意味着可以预知输入的产品功能测试后就会推送到孵化网站,即 meta.stackexchange(原 meta.stackoverflow)。
监视/日志
- 当下正在考虑使用 http://logstash.net/做日志管理,目前使用了一个专门的服务将 syslog UDP 传输到 SQL 数据库中。网页中为计时添加 header,这样就可以通过 HAProxy 来捕获并且融合到 syslog 传输中。
- Opserver 和 Realog 用于显示测量结果。Realog 是一个日志展示系统,由 Kyle Brandt 和 Matt Jibson 使用 Go 建立。
- 日志通过 HAProxy 负载均衡器借助 syslog 完成,而不是 IIS,因为其功能比 IIS 更丰富。
关于云
- 还是老生常谈,硬件永远比开发者和有效率的代码便宜。基于木桶效应,速度肯定受限于某个短板,现有的云服务基本上都存在容量和性能限制。
- 如果从开始就使用云来建设 SO 说不定也会达到现在的水准。但毫无疑问的是,如果达到同样的性能,使用云的成本将远远高于自建数据中心。
性能至上
- StackOverflow 是个重度的性能控,主页加载的时间永远控制在 50 毫秒内,当下的响应时间是 28 毫秒。
- 程序员热衷于降低页面加载时间以及提高用户体验。
- 每个独立的网络提交都予以计时和记录,这种计量可以弄清楚提升性能需要修改的地方。
- 如此低资源利用率的主要原因就是高效的代码。web server 的 CPU 平均利用率在5% 到 15% 之间,内存使用为 15.5 GB,网络传输在 20 Mb/s到 40 Mb/s。SQL 服务器的 CPU 使用率在5% 到 10% 之间,内存使用是 365GB,网络传输为 100 Mb/s到 200 Mb/s。这可以带来 3 个好处:给升级留下很大的空间;在严重错误发生时可以保持服务可用;在需要时可以快速回档。
学到的知识
1. 为什么使用 MS 产品的同时还使用 Redis?什么好用用什么,不要做无必要的系统之争,比如 C# 在 Windows 机器上运行最好,我们使用 IIS;Redis 在*nix 机器上可以得到充分发挥,我们使用*nix。
2. Overkill 即策略。平常的利用率并不能代表什么,当某些特定的事情发生时,比如备份、重建等完全可以将资源使用拉满。
3. 坚固的 SSD。所有数据库都建立在 SSD 之上,这样可以获得 0 延时。
4. 了解你的读写负载。
5. 高效的代码意味着更少的主机。只有新项目上线时才会因为特殊需求增加硬件,通常情况下是添加内存,但在此之外,高效的代码就意味着 0 硬件添加。所以经常只讨论两个问题:为存储增加新的 SSD;为新项目增加硬件。
6. 不要害怕定制化。SO 在 Tag 上使用复杂查询,因此专门开发了所需的 Tag Engine。
7. 只做必须做的事情。之所以不需要测试是因为有一个活跃的社区支撑,比如,开发者不用担心出现“Square Wheel”效应,如果开发者可以制作一个更更轻量级的组件,那就替代吧。
8. 注重硬件知识,比如 IL。一些代码使用 IL 而不是C#。聚焦 SQL 查询计划。使用 web server 的内存转储究竟做了些什么。探索,比如为什么一个 split 会产生 2GB 的垃圾。
9. 切勿官僚作风。总有一些新的工具是你需要的,比如,一个编辑器,新版本的 Visual Studio,降低提升过程中的一切阻力。
10. 垃圾回收驱动编程。SO 在减少垃圾回收成本上做了很多努力,跳过类似 TDD 的实践,避免抽象层,使用静态方法。虽然极端,但是确实打造出非常高效的代码。
11. 高效代码的价值远远超出你想象,它可以让硬件跑的更快,降低资源使用,切记让代码更容易被程序员理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号