数据结构做题一些总结
- 概念
- 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图。
- 联通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
- 能够输入计算机并能被计算机处理的符号统称为 数据。
- 顺序循环队列:判断顺序循环队列是空还是满的三种方法:
- 令设置一个标志位,以区别列队是 “ 空 ” 的,还是 “ 满 ” 的.
- 设置一个计数器记录队列中的元素个数.
- 少用一个元素空间,约定入队前,测试尾指针在循环意义下加1后是否等于头指针,若相等则认为队列慢,即尾指针Q.rear所指向的单位始终为空。(判断堆满:(Q.rear+1)%QueueSize==Q.front)
- 填空
- 数据中具有独立含义的最小标识单位是 : 数据项 。
- 抽象数据类型 是指抽象数据的组织和与之相关的操作。
- 有向图中的极大联通子图称作有向图的 强连通分量。
- 数据的四种基本储存方法是:顺序储存,链接存储,索引存储,散列储存。
- 递归求解过程中最小子问题称为:递归的终止条件。
- 邻接表保存n个顶点和e条边的无向图,邻接表中指针的个数是 n+2e 。
- 不易用链式存储的是数组 。
- n个叶 子结点的哈夫曼树共有2n-1个结点。
- 具有n个不同的关键字的序列进行冒泡排序,在元素无序的情况下比较次数最多为:n * ( n - 1 ) / 2 。
- 按路径长度递增的顺序产生诸顶点的最短路径算法是:迪杰斯特拉(Dijkstra)算法。
- 折叠法分为 移位叠加 和 边界叠加。 移位叠加 是将各段的最低位对齐,然后相加;边界叠加 则是将两个相邻的段沿边界来回折叠,然后对齐相加。
- 广度优先搜索(BFS)按层级搜索(父级搜索先搜索那个下面就先显示那个结点的子集) ,深度优先搜索(DFS)一条路走完,跟回溯类似,这两种搜索的结果都不是唯一的
- 深度优先搜索遍历类似于树的 中序遍历。
- n个结点的线索二叉树上含有的线索树为n+1。
- 常用的解决冲突的方法有两大类,即 开放定址法 和 拉链法 。
- 开放定址法分为 线性探查法,二次探查法,双重散列 三种。
- 归并排序算法需要的辅助空间为 O(n).
- 常用的构造散列函数的方法有 直接地址法,数字分析法,除余数法,平方取中法,折叠法。
- 图G在任何情况下都是连通的,需要的边数最少为:( n - 1 ) ( n - 2 ) / 2 + 1 。
- 公式
- 一个二叉树度为2的结点有 n2 个,则叶子节点 = n2 + 1。
- 二叉树的深度和高度
- 二叉树的深度是从根节点开始(其深度为1)自顶向下逐层累加的;
- 二叉树高度是从叶节点开始(其高度为1)自底向上逐层累加的。
- 虽然树的深度和高度一样,但是具体到树的某个节点,其深度和高度是不一样的。
- 已知二维数组为arr[ m , n ], 基地址为a0, 求二维数组LOC[ x ,y ]的地址值
- 按行优先顺序:LOC[ x , y ] = a0 + d * [ n * ( x - 1 ) + ( y - 1) ]。
- 按列优先存储:LOC[ x , y ] = a0 + d * [ m * ( y - 1 ) + ( x - 1) ]。
- 一个具有n个节点的完全二叉树,其叶子节点的个数n0为:n / 2 向上取整,或(n+1) / 2 向下取整 。
- 存储密度 = (结点数据本身所占的存储量)/(结点结构所占的存储总量)。
- 在容量是M的循环队列中,front为队头指针,rear为队尾指针,则队列中元素的个数是:( rear - front + M ) % M 。
- 无向图的顶点个数为n,则该图最多有 n*(n-1)/2 条边.
- 有向图G为n个顶点,则图中最多有 n(n-1) 条边。
- 有 n(n-1)/2 条边 的是无向完全图。
- 二叉树
- 二叉排序树
- 删除时候重新排序:二叉排序树根据中序遍历得到他的(直接前驱,直接后继)用来顶替需要删除的位置。
- 树转化为二叉树
- 加线。就是在所有兄弟结点之间加一条连线;
- 抹线。就是对树中的每个结点,只保留他与第一个孩子结点之间的连线,删除它与其它孩子结点之间的连线;
- 旋转。就是以树的根结点为轴心,将整棵树顺时针旋转一定角度,使之结构层次分明。
- 二叉树转化为树
- 先把每棵树转换为二叉树;
- 第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子结点,用线连接起来。当所有的二叉树连接起来后得到的二叉树就是由森林转换得到的二叉树。
- 转化二叉树中右子树的结点个数等于=(除去第一颗树)树结点之和。
- 二叉排序树
- 散列表
- 哈希表解决冲突方式:
- 二次探查法:当前位置重复的话,按下面的次序依次寻找 1^2, -1^2, 2^2, -2^2, 3^2,……
- 哈希表解决冲突方式:
- 图
- 拓扑序列:(这里得到的排序并不是唯一的!就好像你早上穿衣服可以先穿上衣也可以先穿裤子,只要里面的衣服在外面的衣服之前穿就行。)
- 选择一个入度为0的顶点并输出之;
- 从网中删除此顶点及所有出边。
- 拓扑序列:(这里得到的排序并不是唯一的!就好像你早上穿衣服可以先穿上衣也可以先穿裤子,只要里面的衣服在外面的衣服之前穿就行。)
- 排序算法
- 算法复杂度

- 堆排序
- 先变为大根堆或小根堆
- 然后把根节点取出来 ,把最后一个节点放上去,重新生成大根堆或小根堆。
- 希尔排序算法
-
希尔排序 //比如 [7, 3, 2, 6, 2, 1, 1] 分组 数组长度n=7 //间隔长度 sap = 3 --> (n/2) // index 0 1 2, 3 4 5 6 // ↓min ↓max // 第一次排序 [6, 3, 2, 7, 2, 1, 1] 比较 arr[3]<arr[0] 换位置 // ↓min ↓max // 第二次排序 [6, 2, 2, 7, 3, 1, 1] 比较 arr[4]<arr[1] 换位置 // ↓min ↓max // 第三次排序 [6, 2, 1, 7, 3, 2, 1] 比较 arr[5]<arr[2] 换位置 // ↓min ↓max // 第四次排序 [6, 2, 1, 1, 3, 2, 7] 比较 arr[6]<arr[3] 换位置 * 当前左边还可以构成一次交换-> 0..3然后继续走 // ↓min ↓max ↓ // ---------- [1, 2, 1, 6, 3, 2, 7] 比较 arr[0]<arr[3] 换位置 //间隔长度 sap = 1 --> (sap/2) // 同上。。。
- 算法复杂度
- 图 最小生成树 算法
- prim算法:此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点
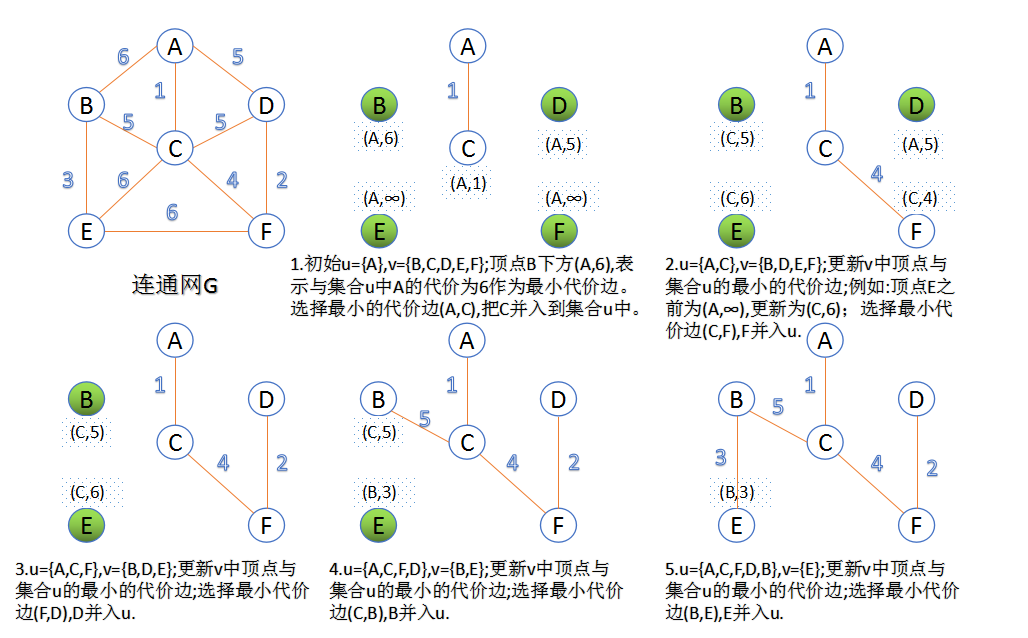
- Kruskal算法:此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。

- prim算法:此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点
。net工程师

 浙公网安备 33010602011771号
浙公网安备 33010602011771号