以浏览器解析机制来理解XSS载荷的编码转换
0x00 前言
之前在学习XSS的时候总感觉不是很系统,许多技巧背后原理都没有理解,光是会用罢了,如部分绕过编码技巧。
今天打算花时间来补补基础。
0x00 基础知识
HTML基础
常见的字符实体
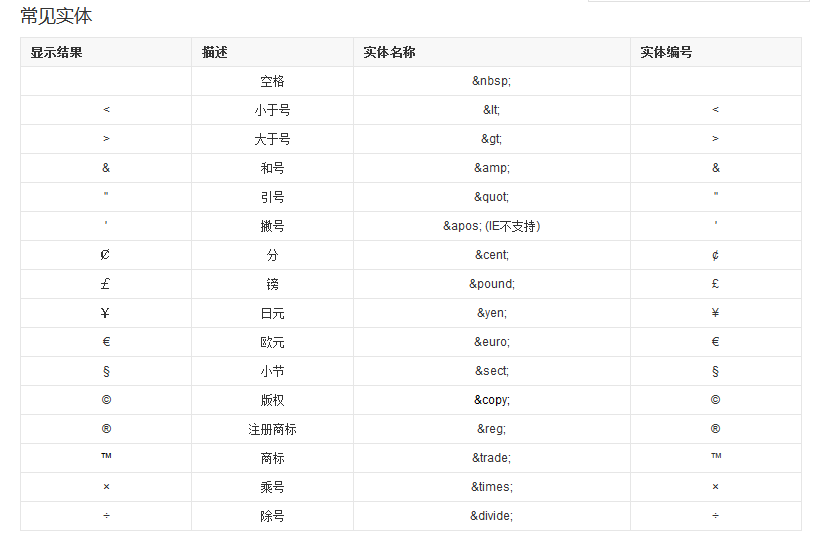
部分具有特定名称的字符实体
而对于其他没有特定名称的实体来说:
- 十进制:对应符号的Ascii的值前加上&#,后以;结尾
- 十六进制:对应符号的Ascii的值换算成16进制前加上&#x,后以;结尾
注意:字符实体解码后得到的值为字符串型,HTML解析器只将其当做字符串文本处理。
HTML元素
共有5种元素:空元素、原始文本元素、RCDATA元素、外来元素以及常规元素。
- 空元素:area、base、br、col、command、embed、hr、img、input、keygen、link、meta、param、source、track、wbr
- 原始文本元素:script、style
- RCDATA元素:textarea、title
- 外来元素:来自MathML命名空间和SVG命名空间的元素。
- 常规元素:其他HTML允许的元素都称为常规元素。
原始文本、RCDATA以及常规元素都有一个开始标签来表示开始,一个结束标签来表示结束。某些元素的开始和结束标签是可以省略的,如果规定标签不能被省略,那么就绝对不能省略它。空元素只有一个开始标签,且不能为空元素设置结束标签。外来元素可以有一个开始标签和配对的结束标签,或者只有一个自闭合的开始标签,且后者情况下该元素不能有结束标签。
元素内容限制
空元素不能有任何内容(因为空元素没有结束标签,自然没办法在开始标签和结束标签之间放内容)。
原始文本元素只可以包含文本
RCDATA元素可以包含文本和字符引用,但是文本中不能包含意义不明的符号。
对于外来元素,当开始标签自闭合时,不能包含任何内容(因为没有结束标签,所以不能在开始标签和结束标签之间放内容)。当开始标签不自闭合时,其内容可以包含文本、字符引用、CDATA块、其他元素和注释,但是文本不能包含编码为U+003C的小于符号(<)或者意义不明的符号。
浏览器显示页面流程:
先逐行加载页面,并将引用的外部文件下载下来->接着逐行解析页面,解析一部分后会将已解析的部分进行渲染,实现边解析边渲染。
浏览器解析机制
一个HTML解析器作为一个状态机,它从输入流中获取字符并按照转换规则转换到另一种状态。在解析过程中,任何时候它只要遇到一个'<'符号(后面没有跟'/'符号)就会进入"标签开始状态(Tag open state)"。然后转变到"标签名状态(Tag name state)","前属性名状态(before attribute name state)"......最后进入"数据状态(Data state)" 并释放当前标签的token。当解析器处于"数据状态(Data state)"时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
1.标签a解析例子
<a href="http://www.0x002.com">0x002</a>
1)起始标签a
范围:<a href="http://www.0x002.com">
DataState:碰到<,进入TagOpenState状态
TagOpenState:碰到a,进入TagNameState状态(HTMLToken的type为StartTag)
TagNameState:碰到空格,进入BeforeAttributeNameState状态(HTMLToken的m_data为a)
BeforeAttributeNameState:碰到h,进入AttributeNameState状态
AttributeNameState:碰到=,进入BeforeAttributeValueState状态(HTMLToken属性列表中加入一个属性,属性名为href)
BeforeAttributeValueState: 碰到",进入AttributeValueDoubleQuotedState状态
AttributeValueDoubleQuotedState:碰到b,保持状态,提取属性值
AttributeValueDoubleQuotedState:碰到",进入AfterAttributeValueQuotedState(HTMLToken当前属性的值为http://www.0x002.com).
AfterAttributeValueQuotedState: 碰到>,进入DataState,完成解析。
在完成startTag的解析的时候,会在解析器中存储与之匹配的end标签(m_appropriateEndTagName),等到解析end标签的时候,会同它进行匹配(语法解析的时候)。
html,body起始标签类似a起始标签,但没有属性解析
2)a元素内容
DataState:0x002,碰到0,维持原状态,提取元素内容(HTMLToken的type为character)。
DataState:0x002,碰到<,完成解析,不consume'<'。(HTMLToken的m_data为w3c)。
3)a结束标签
DataState:0x002,碰到<,进入TagOpenState。
TagOpenState:0x002,碰到/,进入到EndTagOpenState。(HTMLToken的type为endTag)。
EndTagOpenState:0x002,碰到a,进入到TagNameState。
TagNameState:0x002,碰到>,进入到DataState,完成解析。
这部分设计到状态机的知识,与解析原理有关。
为什么要讲这部分呢?因为他与接下来要讲的XSS载荷字符实体编码有关。
HTML解析器,部分标签在完成解析时,会按照节点类型、节点属性等生成不同的解析器去完成接下来的工作。
如a标签的href属性,HTML解析器会生成一个Url解析器去解析里边的内容。
对于<script>,HTML解析器生成JS解析器去执行标签内容,执行时HTML解析器阻塞、渲染阻塞,等待执行完毕后恢复。
0x02 各种编码讲解
1.字符实体编码
解码操作在HTML解析器中。
有三种情况可以容纳字符实体,"数据状态中的字符引用","RCDATA状态中的字符引用"和"属性值状态中的字符引用"。在这些状态中HTML字符实体将会从&#...形式解码,对应的解码字符会被放入数据缓冲区中。例如,在问题4中,"<"和">"字符被编码为<和>。当解析器解析完<div>并处于"数据状态"时,这两个字符将会被解析。当解析器遇到&字符,它会知道这是"数据状态的字符引用",因此会消耗一个字符引用(例如"<")并释放出对应字符的token。在这个例子中,对应字符指的是<和>。读者可能会想:这是不是意味着<和>的token将会被理解为标签的开始和结束,然后其中的脚本会被执行?答案是脚本并不会被执行。原因是解析器在解析这个字符引用后不会转换到"标签开始状态"。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成"数据"。
简单的说,字符实体编码仅在下列几种情况适用:
- 标签内容(不包括原始文本元素,如
<script>):<>[在这]</> - RCDATA元素内容中(
<textarea>、<title>):<>[在这]</> - 标签属性值内容:
<xx xx="[在这]">(</xx>)
2.URL编码
解码操作在URL解析器中
例子:
对于<a href="javascript:alert%281%29"></a>来说:HTML解析后,把javascript:alert(1)发送给URL解析器,此时URL解析器会先寻找:冒号,以确定该内容的协议。如未找到或无法确定,则默认为http协议,本例中为javascript协议。Url解析器会将协议冒号后边(若无冒号或无法确定协议,则解码的群体为全部内容)的字符全部进行一次url解码,即对alert%281%29进行URL解码,得到alert(1)。
3.Unicode编码
解码操作在Javascript解析器中
JS解析器支持对标识符进行Unicode编码。什么是标识符?简单的说,标识符包括了函数名、字符串常量。主要看编码的字符是构成哪个部分的字符,如:
<script>
Alert('xss');
</script>
对于该例来说,alert(属于函数名部分,是标识符)可进行部分或全部的Unicode编码,xss(属于字符串常量,是标识符)也可进行全部/部分Unicode编码。换句话说,经Unicode解码后的内容只能构成函数名和字符串。
0x03 常见添加编码的XSS载荷讲解
1. <a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
2. <a href="javascript:%61%6c%65%72%74%28%32%29">
3. <a href="javascript%3aalert(3)"></a>
4. <div><img src=x onerror=alert(4)></div>
5. <textarea><script>alert(5)</script></textarea>
6. <textarea><script>alert(6)</script></textarea>
7. <button onclick="confirm('7');">Button</button>
8. <button onclick="confirm('8\u0027);">Button</button>
9. <script>alert(9);</script>
10. <script>\u0061\u006c\u0065\u0072\u0074(10);</script>
11. <script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>
12. <script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>
13. <script>alert('13\u0027)</script>
14. <script>alert('14\u000a')</script>
15. <a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
载荷1:
HTML解析器解析a标签,将属性href的内容:%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29
发送给URL编码器,URL编码器找到:的位置,但%6a%61%76%61%73%63%72%69%70%74协议不存在,故无法确定协议,默认为http协议。对整个内容进行url解码,得:javascript:alert(1),最终的结果相当于,载荷无效
载荷2:
HTML解析器在解析a标签,发现属性href的值内存在字符编码,将其转码为:javascript:%61%6c%65%72%74%28%32%29,将结果发送给URL解析器,URL解析器寻找:出现的位置,判断其协议,并将:后边内容进行URL转码,得到:alert(2),由于是javascript协议,URL解析器将内容发送给JS解析器。载荷有效
载荷3:
同载荷1,由于找不到:,URL转码器按照默认http协议进行。结果相当于<a href="http://javascript:alert(3)"></a>
载荷4:
div属于常见元素中的一个,字符实体可以被成功解码,不过此时得到的是字符串型的数据,无法构成标签。
即:<div><img src=x onerror=alert(4)></div>中,=所代表的<转码后得到的值为字符串型,无法被HTML解析器解析成构成的标签起始位的<。若是<div><img src=x onerror=alert(4)></div>的话是可以被成功解析的。
载荷5:
Textarea属于RCDATA元素,无法执行js脚本,虽支持实体字符编码,但此时得到的值为字符串型,也不能被解析,但可正常显示。
载荷6:
Textarea属于RCDATA元素,无法执行js脚本。
载荷7:
经HTML解析器解析,属性onclick的值confirm('7');被Unicode解码得:confirm('7');
由于是事件型属性,HTML编码器直接发送confirm('7');给JS解析器,载荷有效。
载荷8:
经HTML解析器解析,属性onclick的值 confirm('8\u0027);
由于是事件型属性,HTML编码器直接发送confirm('8\u0027);给JS解析器,虽JS解析器支持Unicode解码,但该字符不为标识符(函数名/字符串常量),载荷无效。
载荷9:
script标签属于原始文本元素,不支持字符实体编码。载荷无效。
载荷10:
script标签属于原始文本元素,HTML解析器直接将内容发送给JS解析器,JS解析器支持Unicode编码,且此处\u0061\u006c\u0065\u0072\u0074(10);为alert(10),属于函数名,满足标识符限制,故可解码得到alert(10)。载荷有效。
载荷11:
\u0028\u0031\u0031\u0029 解码后不属于标识符,载荷无效。
载荷12:
\u0031\u0032 解码后为整数型数字,不属于标识符,载荷无效。
载荷13:
同11
载荷14:
14\u000a 解码后,属于字符串型,属于标识符,载荷有效。
载荷15:
javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)
经HTML实体解码得:
javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)
经URL解码得:
javascript:\u0061\u006c\u0065\u0072\u0074(15)
经Unicode解码得:alert(15),载荷有效。
0x04 编码之外
我们知道HTML解析器,在解析时会去掉一些干扰字符,如换行符、回车键、跳格键t等,故我们可以使用这个特性来绕开部分Filter
例子:
<iframe
src
=
"
j
avas
cript
:
aler
t
(
1)
"
>
</iframe>
0x05 参考资料:
- https://www.jianshu.com/p/c0dc4bbab8e8
- https://blog.csdn.net/wh_xmy/article/details/79567070
- https://www.w3.org/html/ig/zh/wiki/HTML5/syntax
- https://www.freebuf.com/articles/web/100675.html
- https://blog.csdn.net/dlmu2001/article/details/5998130
- https://blog.csdn.net/wh_xmy/article/details/79567070
- https://xz.aliyun.com/t/1556
- https://security.yirendai.com/news/share/26
- http://bobao.360.cn/learning/detail/292.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号