第一次个人编程作业
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 10min | 10min |
| · Estimate | · 估计这个任务需要多少时间 | 10min | 10min |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 10min | 10min |
| · Design Spec | · 生成设计文档 | 5h | 3h |
| · Design Review | · 设计复审 | 2h | 20min |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0min | 0min |
| · Design | · 具体设计 | 10h | 5h |
| · Coding | · 具体编码 | 5h | 15h |
| · Code Review | · 代码复审 | 3h | 2h |
| · Test | · 测试(自我测试,修改代码,提交修改) | 5h | 10h |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ||
| · 合计 | 30h30min | 35h50min |
二、计算模块接口
计算模块接口的设计与实现过程
第一思路就是由敏感词列表生成一个字典树,以['法拉利','fuck']为例,其实就是列出除了谐音字以外的所有可能性
{
"法": {
"拉": {
"利": {
"word": 0 /*word的值表示当前节点所在路径对应的敏感词在敏感词列表中的索引*/
},
"l": {
"i": {
"word": 0,
"end": true /*end为true表示当前分支是一个字拼音的最后一个字母*/
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"l": {
"a": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
},
"end": true
},
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"扌": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"才": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
}
},
"f": {
"a": {
"拉": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"l": {
"a": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
},
"end": true
},
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"扌": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"才": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"end": true
},
"拉": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"l": {
"a": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
},
"end": true
},
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"扌": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"才": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"u": {
"c": {
"k": {
"word": 1
}
}
}
},
"氵": {
"去": {
"拉": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"l": {
"a": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
},
"end": true
},
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
},
"扌": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
},
"才": {
"立": {
"利": {
"word": 0
},
"l": {
"i": {
"word": 0,
"end": true
},
"word": 0
},
"禾": {
"刂": {
"word": 0
}
}
}
}
}
}
}
本次项目的主要类是Filter,构造如下
class Filter(object):
def __init__(self) -> None:
super().__init__()
self.trees = {} # 敏感词树
self.words = [] # 敏感词列表
self.maxChars = 20
def add(self, i_words, i_word, root):
"""
i_words: 当前敏感词在self.words中的索引
i_word: 当前单字在敏感词中的位置
root: 前一个单字所在分支
"""
def parse(self, path):
with open(path, 'r', encoding='UTF-8') as words:
self.words = words.read().split('\n')
for i in range(len(self.words)):
self.add(i, 0, self.trees)
def filter(self, words_path, org_path, ans_path):
"""
文档检测:
设待检测文档当前指向x,
检测的过程主要有四个分支:
1. x有没有在字典树当前节点的某个分支中
2. x若是汉字,那它的某个拼音是不是字典树当前节点的某个分支的谐音
3. x有没有在字典树根节点的某个分支中
4. x是不是插在中文敏感词里的字母或者数字
"""
计算模块接口部分的性能改进
-
一开始用的拆字模块拆字拆得非常细,并且拆的不只是左右结构的汉字,严重影响生成字典树的效率,因此用了最笨的方法——手动修改数据,对于同样的三百多个敏感词,使用原始的拆字模块需要29秒左右的时间来生成字典树,而更新数据后只需10来秒(不知道这算什么水平的速度)
-
文档检测基本上没有什么性能上的改进,按照一开始的思路从头扫到尾,敏感词一多起来,程序运行的时间就集中在生成字典树上。不过后来发现题目的某些要求我没理解到位,做了一些简单的修改。
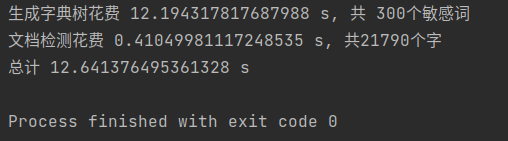
-
用Pycharm自带的性能分析工具生成的性能分析图
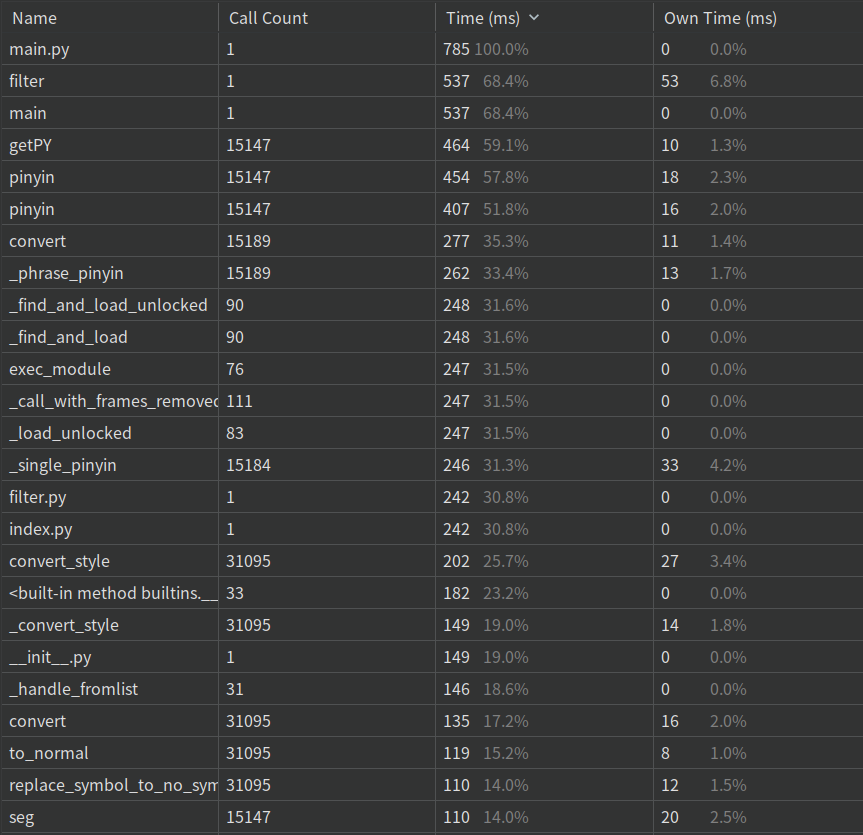
在敏感词数量较少的情况下,上图显示消耗最大的是filter函数
def filter(self, words_path, org_path, ans_path):
tryIO(words_path)
tryIO(org_path)
self.parse(words_path)
st_ptr_org, prev, res, line, i = 0, 0, [], 1, 0
flag = True # 是否还未找到新敏感词的第一个字
with open(org_path, 'r', encoding='UTF-8') as org_txt:
org_txt = org_txt.read()
root = self.trees
def func():
nonlocal root, i, temp, org_txt, prev
nonlocal st_ptr_org, flag, res, line
if (i - prev - 1 > self.maxChars and not flag) or \
(prev != i - 1 and '0' <= org_txt[i] <= '9'):
flag = True
root = self.trees
else:
root = root[org_txt[i].lower()]
if not flag and 'word' in root: # 找到完整的一个敏感词,做记录
temp = root
if len(root) > 1:
for index in range(i + 1, len(org_txt)):
if org_txt[index] in root:
root = root[org_txt[index]]
else:
if 'word' not in root:
root = temp
else:
i = index - 1
break
if index == len(org_txt) - 1:
i = index
res.append(
f'\nLine{line}: <{self.words[root["word"]]}> {org_txt[st_ptr_org:i + 1]}')
flag = True
root = self.trees
prev = i
while i < len(org_txt):
if org_txt[i] == '\n':
line += 1
flag = True
root = self.trees
elif org_txt[i].lower() in root:
if flag:
st_ptr_org = i
prev = i
flag = False
func()
elif isChinese(org_txt[i]):
temp = root
pys = getPY(org_txt[i])[0]
for k in range(len(pys)):
for j in range(len(pys[k])):
if pys[k][j] in root:
root = root[pys[k][j]]
yy = j
else:
yy = j - 1
break
if yy == len(pys[k]) - 1 and 'end' in root and not ('0' <= org_txt[i - 1] <= '9'): # 谐音字
if i - prev - 1 > self.maxChars and not flag:
flag = True
root = self.trees
else:
if flag:
st_ptr_org = i
flag = False
if not flag and 'word' in root: # 找到完整的一个敏感词,做记录
res.append(
f'\nLine{line}: <{self.words[root["word"]]}> {org_txt[st_ptr_org:i + 1]}')
flag = True
root = self.trees
prev = i
break
else:
root = temp
if k == len(pys) - 1:
if not flag:
i -= 1
flag = True
root = self.trees
elif org_txt[i].lower() in self.trees:
root = self.trees
flag = False
st_ptr_org = i
prev = i
func()
elif isChinese(org_txt[st_ptr_org]) and (
'a' <= org_txt[i].lower() <= 'z' or '0' <= org_txt[i] <= '9'):
flag = True
root = self.trees
i += 1
with open(ans_path, 'w', encoding='UTF-8') as res_txt:
res_txt.write(f'Total: {len(res)}')
for x in res:
res_txt.write(x)
计算模块部分单元测试展示
from utils.filter import Filter
def test_filter():
path = '/home/yuneko/Documents/fzu/software_engineering/software-engineering/071803422/test/test_6/'
org_path, words_path = path + 'samples/org.txt', path + 'samples/words.txt'
res_path, ans_path = path + 'res.txt', path + 'samples/ans.txt'
sw_tree = Filter()
sw_tree.filter(words_path, org_path, res_path)
with open(res_path, 'r', encoding='utf-8') as res, open(ans_path, 'r', encoding='utf-8') as ans:
assert res.read() == ans.read()
/* 敏感词 words.txt */
成功
/* 待检测文档 org.txt */
成工力
成工
cgong
cgo
/* 输出 res.txt */
Total: 4
Line1: <成功> 成工力
Line2: <成功> 成工
Line3: <成功> cgong
Line4: <成功> cg
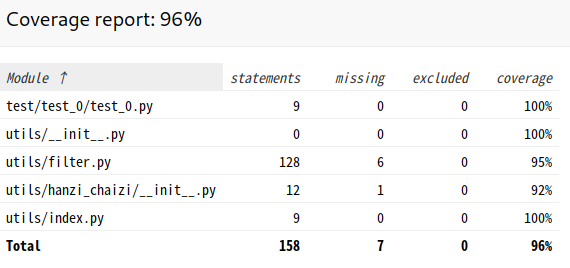
标准样例测试覆盖率
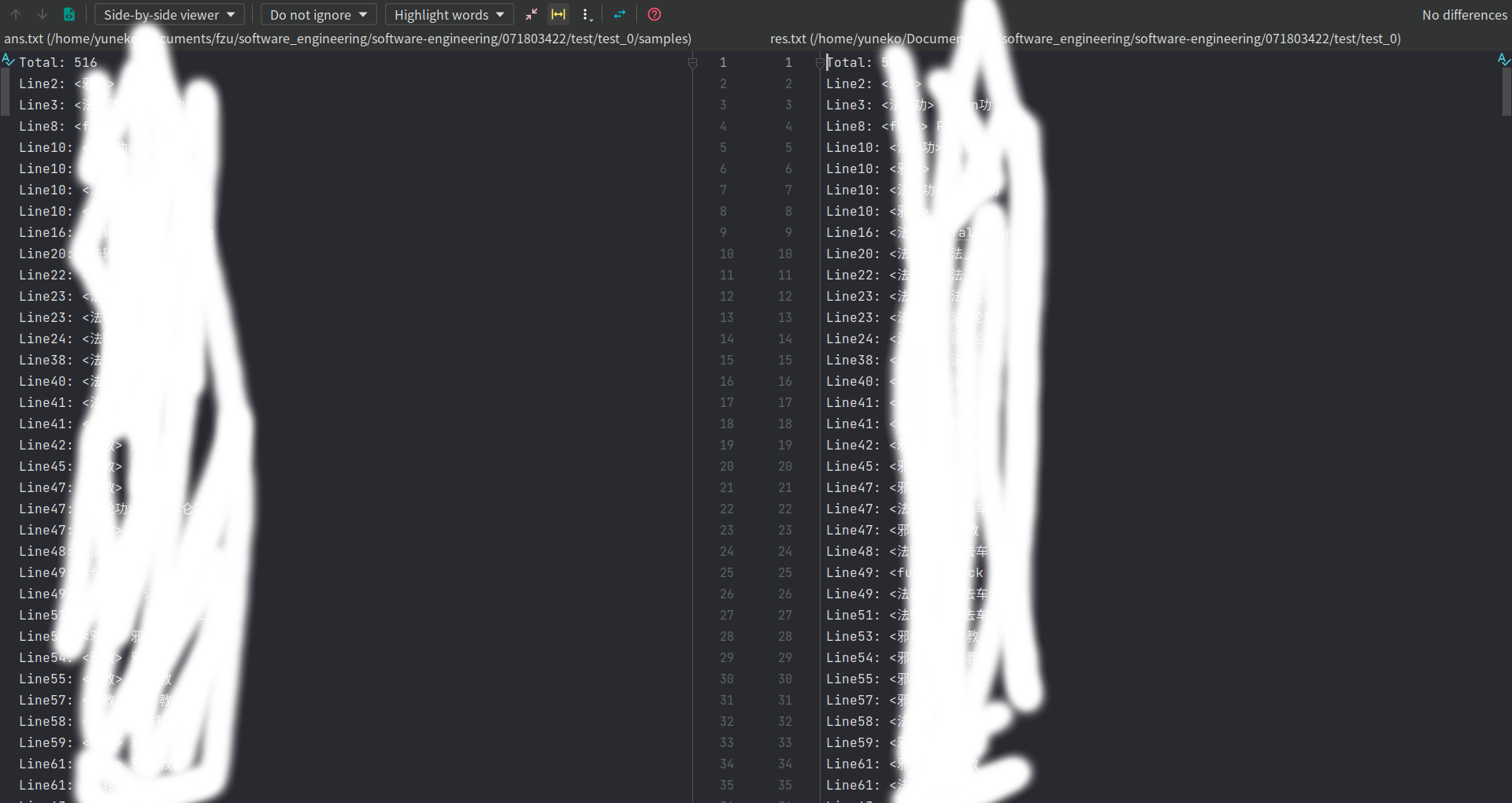
输出结果和更正后的标准答案差异对比
计算模块部分异常处理说明
- 输入文件不存在时
def tryIO(path):
try:
f = open(path, 'r')
except IOError:
print(f'没有找到 {path}')
exit(0)
else:
f.close()
- 命令行参数有误
if len(argv) != 3:
print('参数多于或少于三个!')
exit(0)
三、心得
- 前期设计的时候真的要考虑周全了,不能只想着开始码了就能更好的发现问题。
- 说了不熬夜保命要紧,可是几天下来完全抛弃了“软件工程”的概念,恨不得一夜之间把bug全灭了
- 博客好难写,总结能力还有很大的提升。
写完程序再来整理过程
