


(虚)函数 指针类型转换+指针和数组+各种默认值


class A { public: void f() {cout << "A" << " ";} }; class B : public A { public: void f() {cout << "B" << " ";} }; int main(){ A *pa = new A(); pa->f(); B *pb=(B *)pa; pb->f(); delete pa, pb; pa=new B(); pa->f(); pb=(B *)pa; pb->f(); return 0; }//输出A B A B
2. 当父类里的是虚函数时
class A { public: void virtual f() //看清楚virtual的位置 在返回值oid的后面 {cout << "A" << " ";} }; class B : public A { public: void virtual f() {cout << "B" << " ";} }; int main(){ A *pa = new A(); pa->f(); B *pb=(B *)pa; pb->f(); delete pa, pb; pa=new B(); pa->f(); pb=(B *)pa; pb->f(); return 0; }//输出A A B B
3. 举例
using namespace std; class A{ public: virtual void f() { cout << "A::f() "; } void f() const { cout << "A::f() const "; } }; class B : public A { public: void f() { cout << "B::f() "; } void f() const { cout << "B::f() const "; } }; void g(const A* a) { a->f(); } int main(int argc, char *argv[]) { A* p = new B(); p->f(); g(p); delete(p); return 0; } // B::f() A::f() const /*g(p); 执行的是父类的f() const ,因为他不是虚函数 由于f()在基类中声明为虚的,则p->f()根据对象类型(B)调用B::f(),此时编译器对虚方法使用动态联编,输出B::f()。 由于f() const在基类中未声明为虚的,故p->f() const 根据指针类型(A)调用A::f() const,此时编译器对非虚方法使用静态联编,输出A::f() const。*/
规律如下:https://www.cnblogs.com/mu-tou-man/p/3925433.html
当父类子类有同名非虚函数的时候,调用的是转换后的指针类型的函数;当父类子类有同名虚函数的时候呢,调用的是指针转换前指向的对象类型的函数。
#include <iostream> using namespace std; class Base { public: virtual void f() { cout << "Base::f" << endl; } virtual void g() { cout << "Base::g" << endl; } void h() { cout << "Base::h" << endl; } }; class Derived:public Base { public: virtual void f(){cout<<"Derived::f"<<endl;} void g(){cout<<"Derived::g"<<endl;} void h(){cout<<"Derived::h"<<endl;} }; void main() { Base *pB=new Base(); cout<<"当基类指针指向基类对象时:"<<endl; pB->f(); pB->g(); pB->h(); cout<<endl; Derived *pD=(Derived*)pB; cout<<"当父类指针被强制转换成子类指针时:"<<endl; pD->f(); pD->g(); pD->h(); cout<<endl; Derived *pd=new Derived(); cout<<"当子类指针指向子类时候"<<endl; pd->f(); pd->g(); pd->h(); cout<<endl; Base *pb=(Base *)pd; cout<<"当子类指针被强制转换成父类指针时:"<<endl; pb->f(); pb->g(); pb->h(); cout<<endl; Base *pp=new Derived(); cout<<"父类指针指向子类对象时候:"<<endl; pp->f(); pp->g(); pp->h(); cout<<endl; }
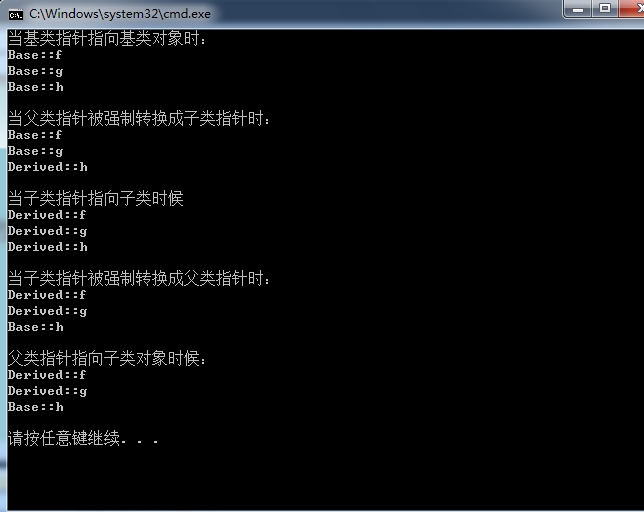
https://blog.csdn.net/u011939264/article/details/52175504
https://blog.csdn.net/u014464706/article/details/22726659
int * p[4]和int(*p)[4] 数组指针和指针数组
int *p[4]; //定义一个指针数组,该数组中每个元素是一个指针,每个指针指向哪里就需要程序中后续再定义了。
int (*p)[4]; //定义一个数组指针,该指针指向含4个元素的一维数组(数组中每个元素是int型)。
区分int *p[n]; 和int (*p)[n]; 就要看运算符的优先级了。
int *p[n]; 中,运算符[ ]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组。
int (*p)[n]; 中( )优先级高,首先说明p是一个指针,指向一个整型的一维数组。
main() { int a[5]={1,2,3,4,5}; int *ptr=(int *)(&a+1); printf("%d,%d",*(a+1),*(ptr-1)); }
输出为:2,5 https://blog.csdn.net/weixin_45905650/article/details/122121016
&a :代指数组的整体的地址,这里的a是数组整体 a+1:代指数组的第一个成员,这里的a是数组首地址
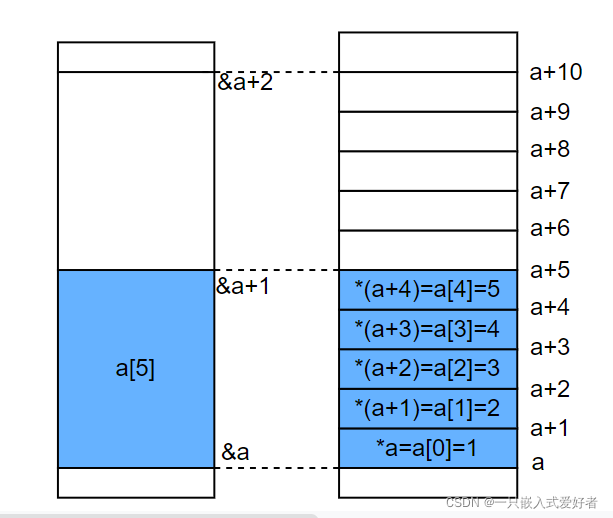
&a和a做右值时的区别:
如上图,&a是整个数组的首地址,而a是数组首元素的首地址。这两个在数字上是相等的,但是意义不相同。意义不相同会导致他们在参与运算的时候有不同的表现。
&a是数组指针,其类型为int(* )[5]; 所以 &a+1就是int (* )[5]+1,如上图所示,&a+1就是相当于整个数组指针加1,执行&a+1后,ptr的偏移量相当于 a + sizeof(int) * 5 * 1。&a+2就是相当于整个数组指针加2,执行&a+2后,ptr的偏移量相当于 a + sizeof(int) * 5 * 2;这里之所以需要强制类型转换,因为类型不匹配:&a是int(* )[5];ptr是 int *类型; 要是输出*(ptr)====a[5]那就是个任意值了
struct xx{ int a; int b; }; void func1(void){ int a; cout<<a<<endl; } void func2(void){ static int a; cout<<a<<endl; } int b; int main() { //func1();//随机数 //func2();//0 //cout<<b;//0 //xx t; cout<<t.a<<" "<<t.b<<endl; //两个随机值 //xx t={2}; cout<<t.a<<" "<<t.b<<endl;//2 0 //xx t={1}; cout<<t.a/t.b<<endl; //不输出 //全局变量和静态变量都是会自动初始化为0,堆和栈中的局部变量不会初始化而拥有不可预测的值。
struct str{ char c; int a; }; union uni{ char c; int a; }; void func(str arr[2]){ char *str1="hello"; char str2[]="hello"; char str3[20]="hello"; int p[5]={0,1,2,3,4}; str st={0}; uni un={0}; cout<<sizeof(str1)<<endl;//4 表示的是指针的大小 占四个字节 cout<<sizeof(str2)<<endl;//6 +'\0' cout<<sizeof(str3)<<endl;//20 :sizeof(指针和数组名的区别) cout<<sizeof(p)<<endl;//20 4x5!! cout<<sizeof(st)<<endl;//8 对齐 cout<<sizeof(un)<<endl;//4 只按成员中最大的类型分配空间,所有成员共享这个内存空间 //https://blog.csdn.net/weixin_44536482/article/details/89789278 还得是整数倍哦 cout<<sizeof(arr)<<endl;//4 如果我们使用数组名作为函数参数,那么数组名会立刻转换为指向该数组第一个元素的指针。 //C语言会自动的将作为参数的数组声明转换为相应的指针声明。 //如果想得到数组的真实大小的话:将数组的引用作为参数int (&a)[] } int main() { str *arr1=new str[2]; //cout<<sizeof(arr1)<<endl;//4 表示的是指针的大小 占四个字节 //cout<<sizeof("hello")<<endl;//6 +'\0' func(arr1); return 0; }
关于union的sizeof
new的初始化
https://blog.csdn.net/u012494876/article/details/76222682 https://blog.csdn.net/aloneingchild/article/details/104600465
int *p = new int[5];//都已经被初始化:错误
int *p = new int[5]();//都已经被初始化:正确
int* buffer = new int[512]; //在默认情况下,new是不会对分配的int进行初始化的。要想使分配的int初始化为0,需要显式地调用其初始化函数: int* buffer = new int(); // 分配的一个int初始化为0 int* buffer = new int(0); // 分配的一个int初始化为0 int* buffer = new int[512](); // 分配的512个int都初始化为0 //对于单个int,也可以初始化为非0值: int* buffer = new int(5); // 分配的一个int初始化为5 //但是无法将分配的所有元素同时初始化为非0值,以下代码是不合法的: int* buffer = new int[512](0); // 语法错误!!! int* buffer = new int[512](5); // 语法错误!!! //C++11 //C++11 中增加了初始化列表功能,所以也可以使用以下的方式进行初始化: int* buffer = new int{}; // 初始化为0 int* buffer = new int{0}; // 初始化为0 int* buffer = new int[512]{}; // 512个int都初始化为0 int* buffer = new int{5}; // 初始化为5 //与上面不同的是,如下写法是合法的: int* buffer = new int[512]{5}; // 第一个int初始化为5,其余初始化为0 /*8仅仅是将第一个int初始化为5,其余的511个仍然初始化为0! 而且正如初始化列表中“列表”两字所指出的,我们实际上可以用一个列表来初始化分配的内存:*/ int* buffer = new int[512]{1, 2, 3, 4}; // 前4个int分别初始化为1、2、3、4,其余int初始化为0
C++在new时的初始化的规律可能为:对于有构造函数的类,不论有没有括号,都用构造函数进行初始化;如果没有构造函数,则不加括号的new只分配内存空间,不进行内存的初始化,而加了括号的new会在分配内存的同时初始化为0。()不等于(0)
int *p = new int[10]; // 每个元素都没有初始化 有随机值不等于被初始化 int *p = new int[10] (); // 每个元素初始化为0 int *p = new int(7); // 元素初始化为7 int *p = new int(); // 元素初始化为0 int *p = new int; // 元素没有初始化 string *p = new string[10]; // 每个元素调用默认构造函数初始化 string *p = new string[10](); // 每个元素调用默认构造函数初始化

