


面试c++
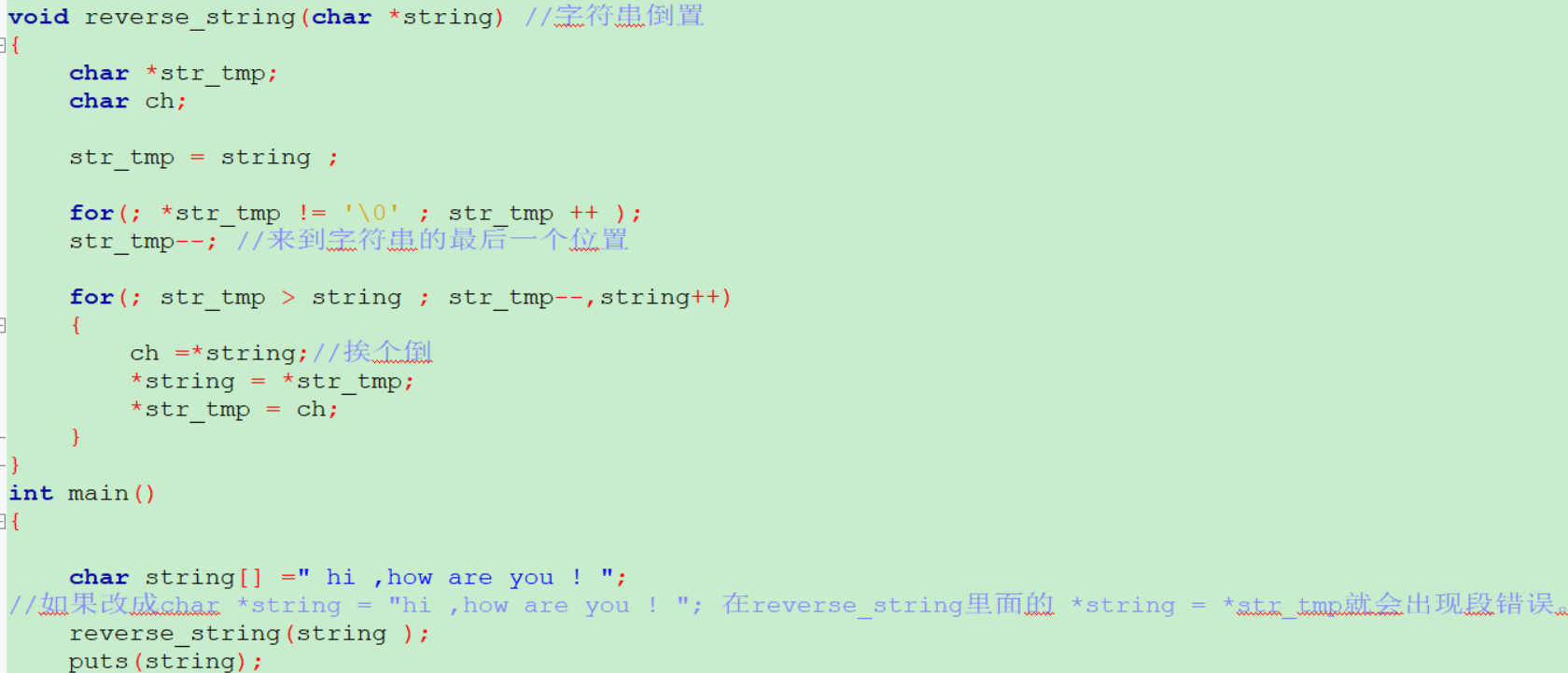
- char* 求某区间最大质数
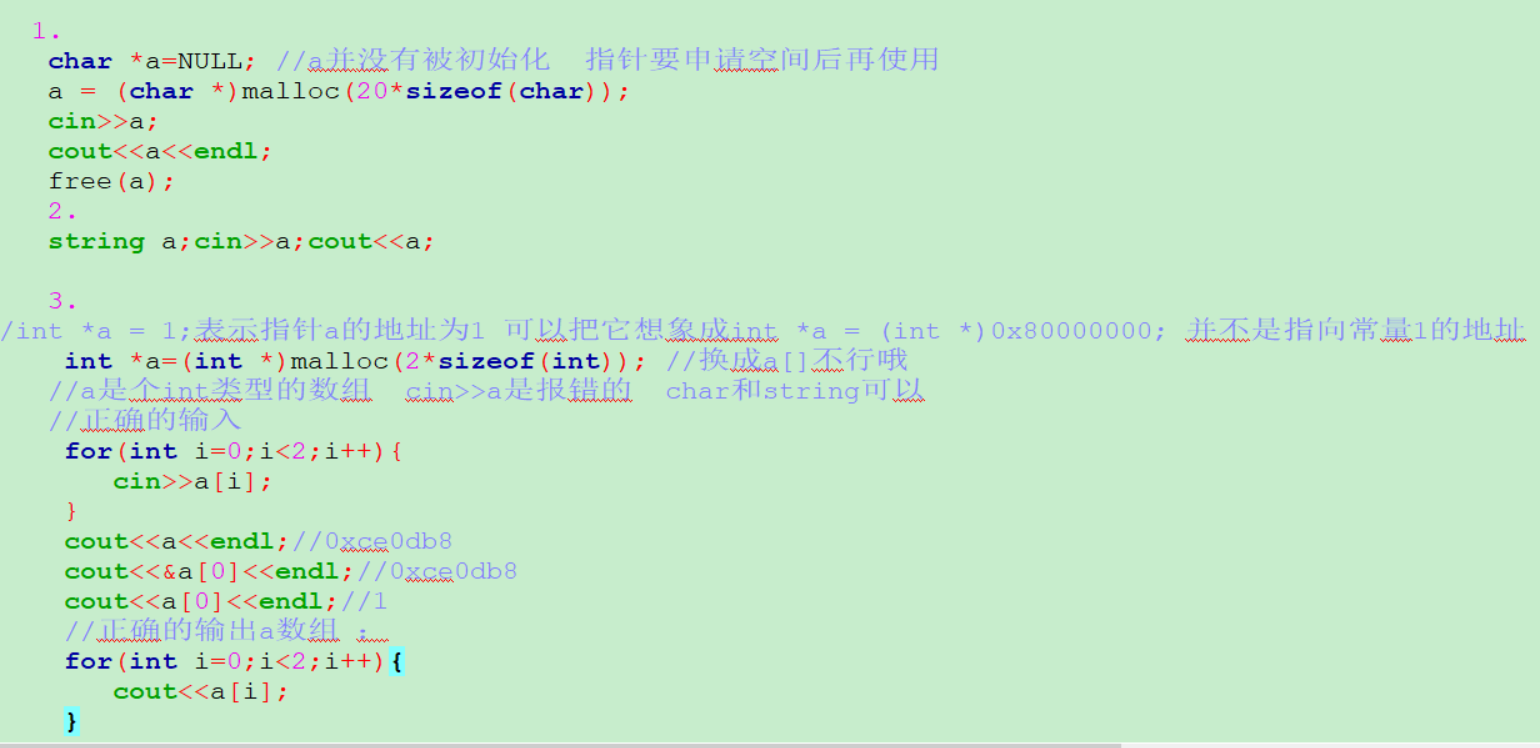
cin>>不可以用于 int型的数组 除非重载操作符 只有字符数组才有\0的概念
关于数组和指针指向常量时:

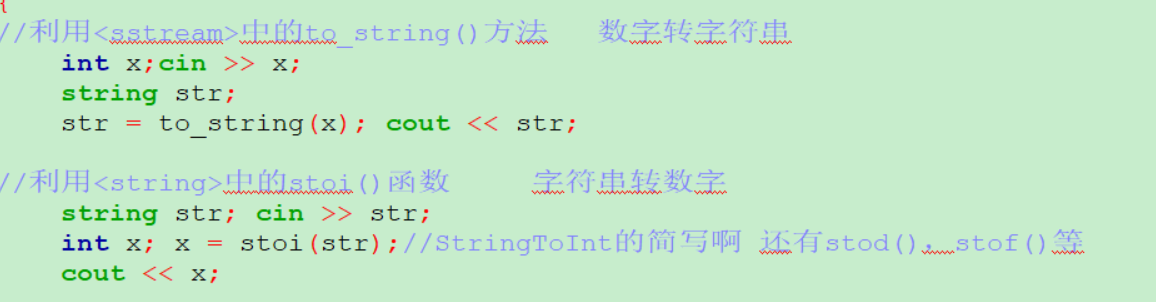
数字与字符串互转
方法1: :c++中引入了流的概念,通过流来实现字符串和数字的转换
方法2:to_string()和stoi()
方法3:

string字符串拼接:1.str.append() 2.str.push_back() 3.str+= 4.sprintf
https://blog.csdn.net/liuweiyuxiang/article/details/83687452
string.size()返回的是size_type类型==unsigned int,而-1作为带符号整数,它的二进制码应该为全1,当int类型和unsigned int类型做比较,会被强制转型为unsigned int类型,此时由于二进制全1,是unsigned int类型中最大的数
string类中size()、length()和strlen()的区别:
size()、length()是c++中string的类的方法,只有string类的对象才可以用该方法,而字符串数组不可用,而strlen、strcpy等源于C语言的字符串处理函数库,需要include<string.h>,同时也只有字符串数组才可以用
size()与length()完全等同,遇到空字符不会被截断,可以返回字符串真实长度
strlen(),源于C语言,遇到空字符会截断,从而无法返回字符串真实长度
多线程的栈和堆是否私有
多线程每个线程独自拥有一个栈区(私有),这是由栈和多线程的特性决定的;而在Windows环境下,堆区对于线程而言是公有的(同一进程内每个线程都可以共享)。
线程栈区私有:因为一个栈只有一个栈顶 top,那么我们假设不同线程共用一个栈,那么假设当前线程需要进行出栈操作,那么它就会无法确定当前的栈顶元素是属于哪个线程的,是不是自己的。
所以正因为栈只能对栈顶进行操作,且只有一个栈顶,所以不同的线程需要维护不同的栈(私有);
线程堆区公有:(注意这里的堆不是算法领域的堆,存储领域的堆只是一个连续自由空间)和栈不同,堆区是通过物理地址来访问存储单元的,堆区空间是自由分配的,每次申请堆空间时都会维护一个堆地址,这样,因为是使用地址访问的,所以不同的线程访问堆空间就不会产生冲突,堆空间完全可以共享(公有)。 最后需要强调的是,以上是针对同一个进程内的不同线程而言的。
tcp通信流程 为什么连接的时候是三次握手,断开的时候是四次挥手?
答:因为连接的时候,服务器收到客户端的SYN连接报文后可以直接发送SYN+ACK报文(其中SYN报文是用来同步的,ACK报文是用来应答的);
但是,断开的时候,服务器收到客户端的FIN报文后并不会立即关闭SOCKET,而是先回复一个ACK报文,告诉客户端“我收到你发的FIN报文了”,
直到服务器的所有报文都发送完了,才发送FIN报文,因此不会一起发送FIN+ACK。故需要四步握手。
3.某月的星期四之和是80 维恩图判断没有证书的人数
5.求某字符串最长的数字字符串
点击查看代码
/*
求字符串中连续最长的数组串
*/
#include<stdio.h>
#include<iostream>
using namespace std;
#define MAX 100
int continumax(char* outputstr,char* inputstr)
{
char* p=inputstr;
char* q=NULL;
char* k=NULL;
int length=0;
while(*p!='\0')
{
if(*p>='0'&&*p<'9')
{
q=p;
k=p;
int count=0;
while(*q>='0' && *q<='9')
{
count++;
q++;
}
if(count>=length)
length=count;
p=q;
}
else
p++;
}
int i=0;
while(i<length)
{
*(outputstr+i)=*(k+i);
++i;
}
*(outputstr+i)='\0';
return length;
}
int main(void)
{
char inputstr[MAX];
char outputstr[MAX];
scanf("%s",inputstr);
continumax(outputstr,inputstr);
cout<<outputstr<<endl;
return 0;
}
5.循环队列判断队长 判断出栈顺序
(1) 入队时队尾指针前进1:(rear+1)%QueueSize
(2) 出队时队头指针前进1:(front+1)%QueueSize
(3) 队列长度:(rear-front+QueueSize)%QueueSize
如现有一循环队列,其队头指针为front,队尾指针为rear;循环队列长度为N。其队内有效长度为?:(rear-front+N)%N
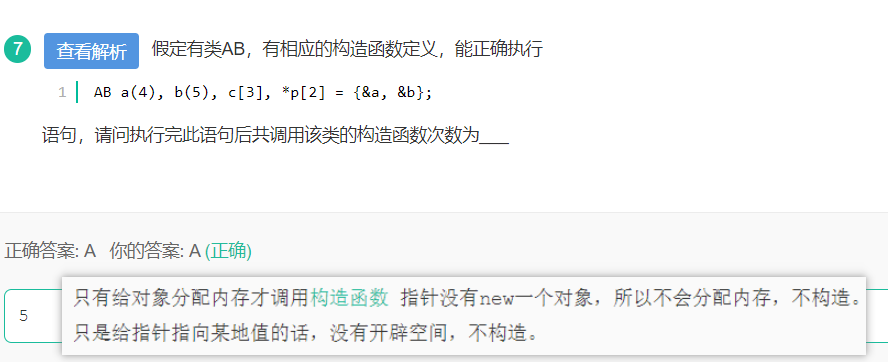
6.以下代码中,A 的构造函数和析构函数分别执行了几次:
A*pa=new A[10];
delete []pa; 答案:10、10
delete pa; 答案:10、1
解释如下:
new 与delete是C++语言中预定的操作符,它们一般需要配套使用。new用于从堆中申请一块空间,一般用于动态申请内存空间,即根据程序需要,申请一定长度的空间,而delete则是将new申请
的内存空间释放。具体而言,在使用new创建对象的时候,会调用这个对象的构造函数。本题中,语句A *pa = new A[10]表示创建了10个A类型的对象,调用了10次构造函数,
数组一旦创建出来,指针pa就指向了数组的首元素,在调用语句delete pa的时候,只调用了A[0]的析构函数,而对后面9个对象没有调用析构函数,而这可能会导致内存泄漏
(内存泄漏指的是分配函数动态开辟的空间在使用完毕后未释放,导致一直占据该内存单元,直到程序结束)。正确的调用方法应该是delete[] pa,此时10个对象的析构函数就都会被调用。
因此,在使用new的时候,必须把new/delete和new[]/delete[]配对使用。

C/C++ 的思考:int a[10] 和 int *a = malloc(10 * sizeof(int)) 的区别:https://copyfuture.com/blogs-details/20201221183225735d0q22nx7rnpghy2
我分不清的堆栈的区别:https://www.cnblogs.com/houjun/p/4909413.html
sizeof(类class)
用sizeof对类名操作,得到的结果是该类的对象在存储器中所占据的字节大小,由于静态成员变量不在对象中存储,因此这个结果等于各非静态数据成员(不包括成员函数)的总和加上编译器额外增加的字节。后者依赖于不同的编译器实现,C++标准对此不做任何保证。
总结:不包括static变量和成员函数
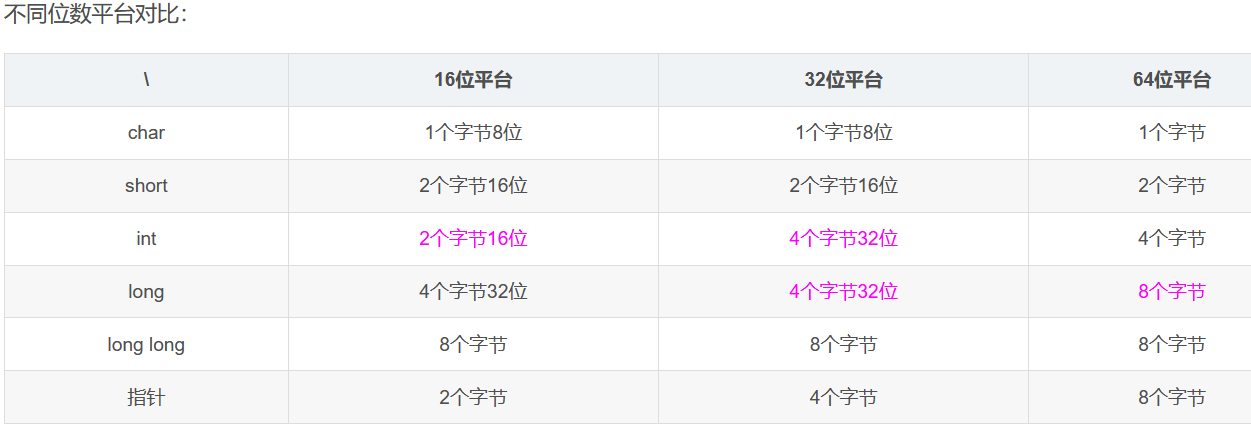
https://www.cnblogs.com/raichen/p/5610679.html
为什么要考虑对齐:
对于嵌入式开发者而言,该问题之所以重要是因为我们经常会在不同系统、不同处理器(32位或64位)之间进行移植,这时候如果双方的默认对齐方式不一致,则可能会导致报错,尤其是使用了sizeof(struct)。需要注意的是,通常32位处理器默认的字节对齐为4字节,64位处理器则是8字节。

https://blog.csdn.net/m0_37829435/article/details/81348532

STL

1.()表示赋值 【】表示数组
2.
3.
4.
虚函数
虚函数(Virtual Function):在基类中声明为 virtual 并在一个或多个派生类中被重新定义的成员函数。
纯虚函数(Pure Virtual Function):基类中没有实现体的虚函数称为纯虚函数(有纯虚函数的基类称为虚基类)。 virtual int virtual_fuc()=0;【不能实例化(就是不能用它来定义对象),只能声明指针或者引用】
C++ “虚函数”的存在是为了实现面向对象中的“多态”,即父类类别的指针(或者引用)指向其子类的实例,然后通过父类的指针(或者引用)调用实际子类的成员函数。通过动态赋值,实现调用不同的子类的成员函数(动态绑定)。正是因为这种机制,把析构函数声明为“虚函数”可以防止在内存泄露.
基类指针指向派生类对象和隐式转换 向上级类型转换是隐式的
const修饰类的成员函数
数组和指针
点击查看代码
char* getmemory(void){
char p[]= " hello world";//运行Test 输出乱码
char *p= " hello world";//运行Test 输出hello world
return p;
}
void test(void){
char *str=NULL;
str=getmemory();
printf(str);
}
//返回“字符串常量的指针”和“返回数组名”的区别在于:
//一个返回静态数据区的地址,一个返回栈内存(动态数据区)的地址。
//”hw”这个字符串本身是存在常量区的 上面的char p[]=”hw”,这里的”hw”在栈上开辟数组P空间之前 预编译的时候就已经在常量区有一份了,
//所以char* p =”hello world”的结果是指针p指到了常量区,
//再给个例子: char p1[]=”hello world”,char p2[]=”hello world”,这里“hello world”在栈上有两份,在常量区有一份。
//char* p =”hello world”p是指向常量区字符串的地址,char p[] =”hello world”是重新拷贝了字符串,放到了p数组中。
5. const的 常量指针(指向常量的指针) 指针常量(指针本身是常量) 所指和本身都是常量的指针 and const引用
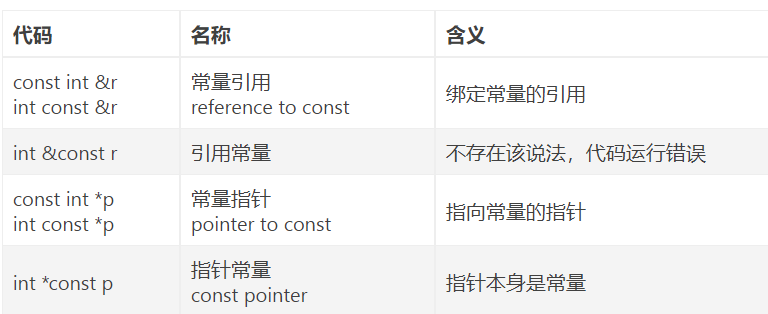
程序一般会将int const转换成const int
指向常量的指针——const int p
本身是常量的指针——int const p
所指和本身都是常量的指针——const int* const p
分不清的话,方法1:
const(号)左边放,我是指针变量指向常量; const(号)右边放,我是指针常量指向变量; const(号)两边放,我是指针常量指向常量;const在的左边,则指针指向的变量的值不可直接通过指针改变(可以通过其他途径改变);在*的右边,则指针的指向不可变。简记为“左定值,右定向”。
方法2:
“从右往左读” 先找到,然后看的两边,右边是对指针p本身的限定,左边是对p所指向的东西的限定。
1.const int *p
的右边没有限定成分,表明p就是我们熟悉的普通指针,p的内容(即值,也就是它指向的东西的地址)是可以改变的;的左边是const int,表明p指向的东西是一个const的int,我们不能通过p来修改这个int,因为它是const的。(关于“不能通过p来修改”,我们后边还会详细解释)
就是所谓的“指向常量的指针”。这里注意,所谓“指向常量”只是这个指针的“一厢情愿”,只是一种效果上的等价。事实上,const int *p=&a;a既可以是常量(const int a=10;)又可以是变量(int a=10;),但p一厢情愿地认为它所指的就是一个常量,所以它不允许通过自己来修改所指,这就造成一种效果上的等价——从p的角度看,它所指的“的确”是常量。所以,对“指向常量的指针”的最佳理解应为:我们不能通过该指针修改它所指向的东西(常量或者变量)。
注意,const int *p=&a;只是说不能通过p来修改a,如果a本身不是const的,通过其它方式修改a自然是可以的(例如直接++a)。
另外一点,由于p本身只是一个普通的指针,所以允许在声明时不初始化。但需要注意的是,我们只是说可以,但并不提倡这样做。在任何时候都不应该让指针无所指,如果在声明一个指针时还不知道让它指向谁,就先将其初始化为nullptr或NULL(nullptr是C++11新特性,用它比用NULL更安全些,这里不详细介绍)。
2.int* const p
的右边是const,表明p本身是const的,我们不能对p的内容进行修改(例如++p;是不可以的),的左边是int,即p指向的东西是普通的int,我们可以通过p来修改它(例如*p=100;是可以的)。
就是所谓的“本身是常量的指针”。关于“p本身不能修改但可以通过p修改其所指”这一点,我们在讲判断方法时已经说过,这里主要再说一下p的初始化。
由于p本身是const的,所以在编译的时候必须知道p的值(即p所指向的东西的地址),所以在声明p的同时必须初始化p。但要注意,对于 int* const p=&a,我们只要求a的地址是确定的,但a的值可以不确定。
int a; int* const p = &b;
cout << *p << endl;
3.const int* const p
的右边是const,表明指针p本身是const的,的左边是const int,表明p指向的int也是const的。即这种情况下,p本身不能修改,同时也不能通过p修改它所指向的那个int。
实例:
点击查看代码
//-------常量指针-------
const int *p1 = &a;
a = 300; //OK,仍然可以通过原来的声明修改值,
//*p1 = 56; //Error,*p1是const int的,不可修改,即常量指针不可修改其指向地址
p1 = &b; //OK,指针还可以指向别处,因为指针只是个变量,可以随意指向;
//-------指针常量-------//
int* const p2 = &a;
a = 500; //OK,仍然可以通过原来的声明修改值,
*p2 = 400; //OK,指针是常量,指向的地址不可以变化,但是指向的地址所对应的内容可以变化
//p2 = &b; //Error,因为p2是const 指针,因此不能改变p2指向的内容
//-------指向常量的常量指针-------//
const int* const p3 = &a;
//*p3 = 1; //Error
//p3 = &b; //Error
a = 5000; //OK,仍然可以通过原来的声明修改值
说说引用和const引用 初始化常量引用时允许用任意表达式作为初始值
点击查看代码
int i = 42;
const int &r1 = i; //正确:允许将const int & 绑定到一个普通int对象上
const int &r2 = 42; //正确
const int &r3 = r1 * 2; //正确
int &r4 = r1 * 2; //错误
double dval = 3.14;
const int &ri = dval; //正确
//等价于
const int temp = dval; //由双精度浮点数生成一个临时的整数常量
const int &ri = temp;
int i = 42;
int &r1 = i;
const int &r2 = i;
r1 = 0; //正确
r2 = 0; //错误
点击查看代码
int i = 1;
const int &r = i; //r绑定i,其后对r的操作实际上是针对i进行的
r = 2; //错误,不能通过修改r来实现对i的修改
i = 2; //i可修改
//常量引用规定不能通过引用修改其所绑定的对象,但能以其它方式修改这个对象。
点击查看代码
//-------空指针-------//
int *p4 = NULL;
//printf("%d",*p4); //运行Error,使用指针时必须先判断是否空指针
//-------野指针(悬浮、迷途指针)-------//
int *p5 = new int(5);
delete p5;
p5 = NULL; //一定要有这一步
printf("%d",*p5); //隐藏bug,delete掉指针后一定要置0,不然指针指向位置不可控,运行中可导致系统挂掉
//-------指针的内存泄漏-------//
int *p6 = new int(6);
p6 = new int(7); //p6原本指向的那块内存尚未释放,结果p6又指向了别处,原来new的内存无法访问,也无法delete了,造成memory leak
5.关于define 在运行时直接代入计算.
点击查看代码
int a=13,b=94;
cout<<MOD(b,a+4)<<endl;
//(94%13)+4
点击查看代码
char buf[4]={0};
memcpy(buf,"hello",strlen("hel"));
cout<<buf<<endl;
//:void *memcpy(void *destin, void *source, unsigned n); 即从源source中拷贝n个字节到目标destin中
理想汽车一面
- 数组[-2,3,4]啥的 挑出三数之和=0
n^3:三个for循环 固定第一个第二个
n^2:两个for 固定first second和third一个从头到尾一个从尾到头
快排:sort() qsort()
malloc,new - int a=1; int *p=&a; int **p1=&p;
int *p2=0x0000【等价于NULL】;可以吗
5.多线程
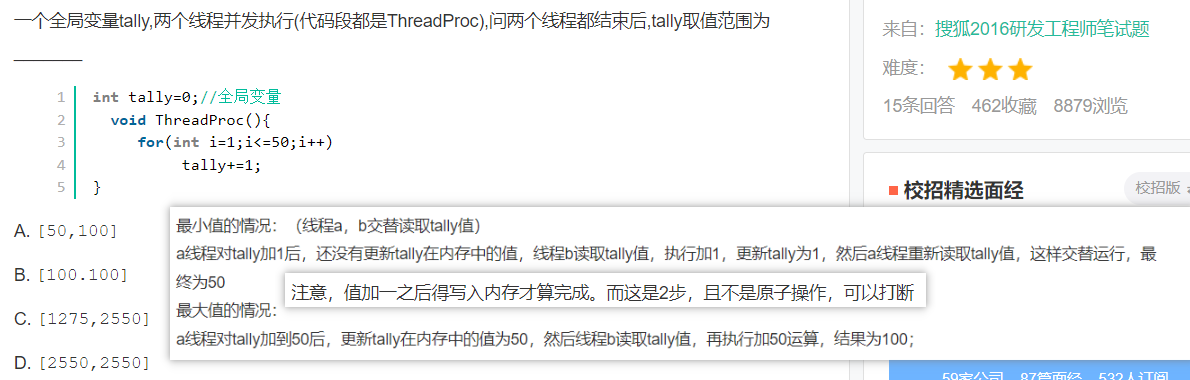
没有使用volatile的全局变量会让线程直接在局部变量缓存中计算和。结果取决于两个进程读写共享内存的时间(在方法结束时)。
最小发生在B启动后于A启动前,先于A结束后。最大发生在B启动后于A结束后
5.关于i++和++i
#include<bits/stdc++.h>
using namespace std;
//i++返回的是i的值,而++i返回的是i+1的值。也就是++i是一个确定的值,是一个可修改的左值,
//int i=3; printf("%d",i++);//3 输出结果为3,但是运行后i的值为4.
//int i = 1;cout << ++ ++i << endl;//3 这样的写法没错
int main()
{
//int i=1;
//cout<<++i<<" "<<i++<<" "<<++i<<" "<<i++; //5 3 5 1
//前置++(++i)返回值为引用,后置++返回的是值; 从后往前计算,保存在栈里;
//重点是输出时,从右到左计算,等计算都!!!完成后,再入栈 再按照先入后出的顺序输出~
//为啥从右向左的第一个++i输出的会是5:因为是这四个式子计算完了再依此压栈再依此输出 前置++要输出最新的i 后置++单单输出他那个式子最先的i
//int i = 1; printf("%d,%d", i += 2, i *= 3);
//在输出i之前先进行了i*=3和i+=2;最终i=5;所以结果是5,5;
// int i = 8; printf("%d,%d,%d,%d\n", ++i, --i, i++, i--);//8,8,7,8 所以前置的i值一样
// int i = 1;
// printf("%d,%d\n", ++i, ++i); //3,3
// printf("%d,%d\n", ++i, i++); //5,3
// printf("%d,%d\n", i++, i++); //6,5
// printf("%d,%d\n", i++, ++i); //8,9
// system("pause"); //总之++i输出的是最新的i(计算完了再压栈) i++输出的是刚拿到的i
/*首先是函数的入栈顺序从右向左入栈的,计算顺序也是从右往左计算的,不过都是计算完以后在进行的压栈操作:
1.首先执行++i,返回值是i,这时i的值是2,再次执行++i,返回值是i,得到i=3,计算完成,将i压入栈中,此时i为3,也就是压入3,3;
2.下一行,首先执行i++,返回值是原来的i,也就是3,再执行++i,返回值是i,依次将3,5压入栈中得到输出结果
3.下一行,首先执行i++,返回值是5,再执行i++返回值是6,依次将5,6压入栈中得到输出结果
4.下一行,首先执行++i,返回i,此时i为8,再执行i++,返回值是8,此时i为9,依次将i,8也就是9,8压入栈中,得到输出结果。
*/
return 0;
}
