


数据结构第一部分-----线性表
线性表(List)是零个或者多个数据元素的有限序列.
- 首先它是一个序列.里面的元素是有顺序的,如果有多个元素,除开头和结尾以外的元素都有一个前驱和一个后继.而开头元素只有后继,结尾元素只有前驱.
- 其次线性表是有限的,也就是里面的元素个数是有限的。
按存储方式分为 顺序表 和 链表
顺序表
1.1顺序表示(顺序表)
概念:用一组地址连续的存储单元依次存储线性表的数据元素,这种存储结构的线性表称为顺序表。
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
只要确定好了存储线性表的起始位置,线性表中任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的储存结构,因为高级语言中的数组类型也是有随机存取的特性,所以通常我们都使用数组来描述数据结构中的顺序储存结构,用动态分配的一维数组表示线性表。
1.2 代码实现
以最简单的学生信息管理为例:
首先先创建两个数据结构,如下:
#define maxsize 100 //定义学生最大数量
#define OK 1 //正确标志
#define ERROR 0 //失败标志
//学生信息的数据结构
typedef struct
{
int id; //学生id
char name[30]; //学生姓名
}Student;
//顺序表数据结构
typedef struct
{
Student *elem; //储存空间的基地址
int length; //数据结构的长度
}SqList;
////////////or 直接:
1 #define MAXSIZE 20 //存储空间的初始大小 2 typedef int DataType //类型可根据实际情况而定 3 typedef struct 4 { 5 DataType data[MAXSIZE]; //数组来存储数据 6 int length; //实际长度 7 }SqlList;
//定义SqList类型的变量
SqList L;
这是一个十分简单的例子,这样我们就可以通过L.elem[i-1]访问序号为i的学生信息了。其实这里我们用到了指针数组。如果你对指针数组还不熟悉的话,可以去我写过的另一篇文章看看:https://blog.csdn.net/qq_38378384/article/details/79951651
1.初始化
基本算法:
//初始化顺序表基本算法
Status InitList(SqList &L)
{
//构造一个空的顺序表L
L.elem = new ElemType[maxsize]; //分配内存空间
if(!L.elem) exit(-1);
L.length = 0;
return OK;
}
2.取值
基本算法:
//顺序表取值
Status Get(SqList &L,int i,ElemType &e)
{
if(i<1||i>L.length) return ERROR;
e = L.elem[i-1];
return OK;
}
3.查找
基本算法:
//顺序表查找
int Find(SqList L,ElemType e)
{
//查找值为e的数据元素,返回其序号
for(i=0;i<L.length;i++)
{
if(L.elem[i]==e) return i+1;
return ERROR; //查找失败
}
}
4.插入
基本算法:
//顺序表插入
Status ListInsert(SqList &L,int i,ElemType e)
{
if((i<1)||(i>L.length+1)) return ERROR; //i不合法
if(L.length == maxsize) return ERROR; //满了
for(j=L.length-1;j>=i-1;j--)
L.elem[j+1]=L.elem[j]; //将第n个至i个位置的元素后移
L.elem[i-1]=e; //将e放进第i个位置
}
5.删除
//顺序表删除
Status ListDelete(SqList &L,int i)
{
//删除第i个元素,i的值为[1,L.length]
if((i<1)||(i>L.length)) return ERROR;
for(j=i;j<=L.length-1;j++)
L.elem[j-1]=L.elem[j];
--L.length; //长度减一
return OK;
}
算法都十分的简单,眼尖的你可能发现了,为啥有的参数用的是引用,有的不是呢?
这里我就得讲下使用引用作为形参的作用了,主要有三点:
(1)使用引用作为参数与使用指针作为参数的效果是一样的,形参变化时实参对应也会变化,这个我在上篇文章(我上面给的链接)也有说明,引用只是一个别名。
(2)引用类型作为形参,在内存中并没有产生实参的副本,而使用一般变量作为形参,,形参和实参会分别占用不同给的存储空间,当数据量较大时,使用变量作为形参可能会浪费时间和空间。
(3)虽然使用指针也可以达到引用一样的效果,但是在被调函数中需要重复使用"*指针变量名"来访问,很容易产生错误并且使程序的阅读性变差。
此时你会发现,使用顺序表作为存储时,空间是一次性直接开辟的,所以可能会有空间不足或者浪费空间的情况出现,那么为啥不用一个就分配一个空间呢,再使用一个方式将这些空间串起来不就好了,是时候展现真正的技术了(链表)。
////////////////////////////////////////////////////////////////////////////////////////////////////////顺序表说白了用的是数组 正常的
链表:
单链表的定义:当一个序列中只含有指向它的后继结点的链接时,就称该链表为单链表。
1 typedef struct LNode{ 2 ElemType data; 3 struct LNode *next; 4 }LNode, *LinkList;
单链表都有一个头指针,一般以head来表示,存放的是一个地址。链表中的节点分为两类,头结点和一般节点,头结点是没有数据域的(有的话存放链表的长度或者不存)。链表中每个节点都分为两部分,一个数据域,一个是指针域。
!!!!!!跟以前理解的不一样

 图1
图1以下是头指针与头结点的关系:
- //定义结点的结构体
- typedef struct LNode{
- int data;
- struct LNode *next;
- }LNode,*LinkList;
则定义LinkList L;时,L为链表的头指针。
L=(LinkList) malloc (sizeof(LNode)); //创建一个结点
此处返回给L的是一个指针,并且赋给了头指针。
L->next=null; //这里说明我创建了一个头结点,即同时运用了头指针和头结点。
1 //不带头结点的单链表的初始化 2 void LinkedListInit1(LinkedList L) 3 { 4 L=NULL; 5 } 6 //带头结点的单链表的初始化 7 void LinkedListInit2(LinkedList L) 8 { 9 L=(LNode *)malloc(sizeof(LNode)); 10 if(L==NULL) 11 { 12 printf("申请空间失败!"); 13 exit(0); 14 } 15 L->next=NULL; 16 }
我一直都很混乱这个东西
单链表不带头结点为空的判断条件:L==NULL;
单链表带头结点 为空的判断条件:L->next==NULL;
L就是个指针,指向第一个节点 ,这个指向,不是L->next 而是L=xxx 你想想c++里的指针指向数组xxx不是直接画等号啊 哪来的什么next->
再说了L就只是个指针,他没有next这个成员啊
所以 说白了就是 混为一体了/////or依附于////就是一体
L是个指针,(没有头结点的时候)链表内容为空,就哪也不指呗,就=null;
(有头结点了)头指针是肯定指向头结点的 ,L就依附到头结点上了,链表为空,头结点的next指针哪也不指,l->next==NULL呗;
你再想想
ANNNNNNNNNNNNNNNNNNNNNNNNNNNNNNND:
为什么链表初始化和销毁链表的时候 传的是二级指针:
1 InitList(LinkList *L){ 2 3 *L=(LinkList)malloc(sizeof(Node)); 4 (*L)->next=NULL; 5 }
简单来说,修改头指针则必须传递头指针的地址,否则传递头指针值即可(即头指针本身)。
//后面代码部分转自 大神https://www.cnblogs.com/leaver/p/6718421.html 我害怕你无措

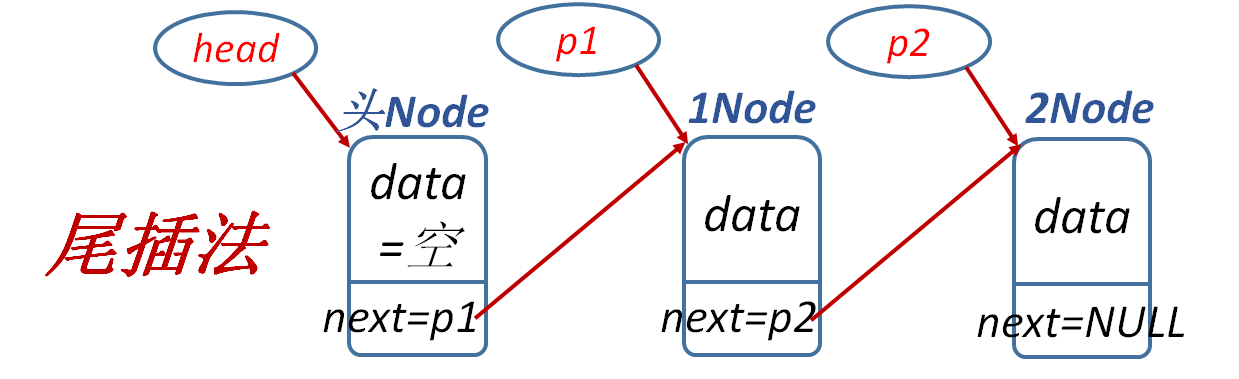
int createListTail(linkList *L, int n) {
linkList p, temp;
temp = (*L);
int i;
srand((int)time(0));
for (i = 0; i < n;i++) {
p = (linkList)malloc(sizeof(Node));
p->data = rand() % 100;
printf("testing:Node[%d]=%d\n", i + 1, p->data);
p->next = NULL;
temp->next = p;
temp = p;
}
printf("链表(尾插法)创建成功\n");
return 1;
}
(四)获取链表的长度
1 int getlength(linkList *L) {
2 linkList p;
3 int length=0;
4 p = (*L)->next;//p指向第一个节点;
5 while (p) {
6 length++;
7 p = p->next;
8 }
9 return length;
10 }
(五)打印整个链表
1 int printList(linkList *L) {
2 linkList p;
3 int i = 0;
4 p = (*L)->next;//p指向第一个节点;
5 printf("-----------打印整个链表-----------\n");
6 if (p==NULL) {
7 printf("这是一个空链表.\n");
8 }
9 while (p) {
10 i++;
11 printf("第%d个节点的数据data为=%d\n",i,p->data);
12 p = p->next;
13 }
14 return 1;
15 }
(六)获取指定位置处的节点元素;
1 int getElem(linkList *L, int i, ElemType *getdata) {
2 linkList p;
3 p = (*L)->next;
4 if (p == NULL)
5 {
6 printf("链表为空,请创建一个链表\n");
7 *getdata = -1;
8 return 0;
9 }
10 if (i < 1)
11 {
12 printf("您所查询的节点%d,应该大于0,请重新输入查询\n",i);
13 *getdata = -1;
14 return 0;
15 }
16 int j = 1;
17 while (p&&j<i) {
18 j++;
19 p = p->next;
20 }
21 if (p == NULL)
22 {
23 printf("您所查询的节点%d,已经超出了数组的长度\n",i);
24 *getdata = -1;
25 return 0;
26 }
27 *getdata = p->data;
28 printf("查询成功!\n", i);
29 return 1;
30 }
(七)插入节点;
插入节点分为两种,一种是在链表的长度范围内插入节点,第二种是在链表的尾部追加一个节点;
假设链表的长度为10,第一种可以在1-10位置处插入节点,比如在第10个位置插入一个节点,则原先的第10节点变为了11节点,但是第二种是所有节点位置都不变,在第11个位置追加一个新的节点;
1 int insertList(linkList *L, int i, ElemType data)
2 {
3 linkList p;
4 linkList insNode;
5 p = (*L);
6 int j=0;
7 // 链表为空,在第1个位置插入一个新的节点;
8 if (p ->next == NULL) {
9 printf("链表为空,默认在第一个位置插入一个节点.\n");
10 insNode = (linkList)malloc(sizeof(Node));
11 insNode->data = data;
12 insNode->next = p->next;
13 p->next = insNode;
14 printf("节点插入成功.\n");
15 return 1;
16 }
17 // 链表非空的情况下,可以在i=1~length的位置插入节点,如果超过了链表的长度,就会提示错误;
18 // 其实如果在length+1的位置处插入一个新节点,就相当于在尾部追加一个节点,在本函数中会报错,可以单独实现一个函数;
19 while(p && j<i-1)
20 {
21 j++;
22 p = p->next;
23 //printf("j=%d\tp->data=%d\n", j, p->data);
24 }
25 if (p->next==NULL) {
26 printf("您要插入的位置,超过了链表的长度 %d,请重新操作!\n",j);
27 return 0;
28 }
29 insNode = (linkList)malloc(sizeof(Node));
30 insNode->data = data;
31 insNode->next = p->next;
32 p->next = insNode;
33
34 printf("节点插入成功\n");
35 return 1;
36 }
追加节点;
1 int insertListTail(linkList *L, ElemType data)
2 {
3 linkList temp;
4 linkList p=(*L);
5 while(p) {
6 temp = p;
7 p = p->next;
8 }
9 p = (linkList)malloc(sizeof(Node));
10 p->data = data;
11 p->next = NULL;
12 temp->next = p;
13 printf("节点插入成功\n");
14 return 1;
15 }
(八)删除节点;
1 int deleteList(linkList *L, int i, ElemType *data)
2 {
3 linkList p,pnext;
4 int j = 0;
5 p = (*L);
6 if (p->next == NULL) {
7 printf("链表为空,无法删除指定节点.\n");
8 *data = -1;
9 return 0;
10 }
11 while (p->next && j<i-1) {
12 j++;
13 p = p->next;
14 //printf("j=%d\t p->data=%d\n",j,p->data);
15 }//条件最多定位到最后一个节点;
16 if ( p->next == NULL) {
17 printf("您要删除的节点,超过了链表的长度 %d,请重新操作!\n", j);
18 *data = -1;
19 return 0;
20 }
21 pnext = p->next;
22 p->next = pnext->next;
23 *data = pnext->data;
24 free(pnext);
25 printf("节点删除成功\n");
26 return 1;
27 }
(九)删除这个链表;
1 int clearList(linkList *L) {
2 linkList p, temp;
3 p = (*L)->next;//p指向第一个节点
4 while (p) {
5 temp = p;
6 p = p->next;
7 free(temp);
8 }
9 (*L)->next = NULL;
10 printf("整个链表已经clear.\n");
11 return 1;
12 }

