
正则表达式
正则表达式:
正则表达式在线测试网址:https://0x9.me/dGRPQ
正则表达式手册:https://0x9.me/wvkrD
正则表达式常用场景:
1.判断某一个字符串是否符合规则 例(注册网页 判断手机号,身份证是否合法)
2.将符合规则的内容从一个庞大的字符串体系当中提取出来。 例(爬虫,日志分析)
什么是正则表达式: 只和字符串打交道
是一种规则,用来约束字符串的规则
字符含义:

# \w \W # print(re.findall("\w","fsjdk1A")) #['f', 's', 'j', 'd', 'k', '1', 'A'] # print(re.findall('\W','hello egon 123')) #[' ', ' '] #\s \S # print(re.findall('\s','hello egon 123')) #\s表示所有的空格换行和tab键 # print(re.findall('\S','hell*o egon 123')) #\S非空格 #\A与^ \Z与$ 一样 # print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^ # print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$ # print(re.findall('^h','hello egon 123')) #['h'] # print(re.findall('3$','hello egon 123')) #['3'] # #\b # l1 = "sing 1studings tuding1 swimming" # ret = re.findall(r"\b[a-zA-Z]*ing[a-zA-Z]*\b",l1) # print(ret) #['sing', 'studings', 'tuding', 'swimming'] #重复匹配 #. 除了换行符之外的任意字符 # print(re.findall("a.b","fsavbfsjajbfa b")) #['avb', 'ajb', 'a#b'] # 9、1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) # 1)从上面算式中匹配出最内层小括号以及小括号内的表达式 # import re # l1 = "1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))" # print(re.findall(r'\([^()]+\)',l1))
量词:

^以什么开头 $以什么结尾
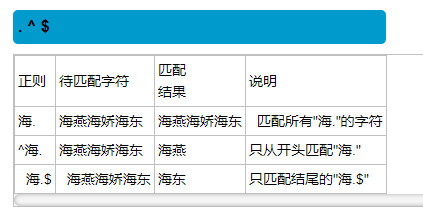
运用
#第一题:1、匹配整数或者小数(包括正数和负数) # import re # def func(str1): # ret = re.findall("-?\d+(?:\.\d+)?",str1) # return ret # print(func("afdkj123.21afkj-23fafs53.324")) #第二题: #2、匹配年月日日期 格式2018-12-06 # import re # ret =re.findall("\d{4}-[1]?\d-[1-3]?\d","2018-05-6") # print(ret) #第三题: #3、匹配qq号 # import re # ret = re.findall("[1-9]\d{4,10}","54654444") # print(ret) #第四题: # 4、11位的电话号码 # import re # ret = re.findall("^[1][3-8]\d{9}$","18323978615") # print(ret) #第五题: # 5、长度为8-10位的用户密码 : 包含数字字母下划线 # import re # ret = re.findall("(?:\d|[a-zA-Z]|_){8,10}","aAk123_5fs") # # ret = re.findall("\w{8,10}","asflj123lk") # print(ret) #第六题: # 6、匹配验证码:4位数字字母组成的 # import re # ret = re.findall("(?:\d|[a-zA-Z]){4}","afhz") # print(ret) #第七题: # 7、匹配邮箱地址 # import re # ret = re.findall("^[a-zA-Z]\w{4,16}(?:\d|[a-zA-Z])@(?:163|126|yeah)\.com$","asf123@163.com") # print(ret) #第八题: # 8、从类似 # <a>wahaha</a> # <b>banana</b> # <h1>qqxing</h1> # 这样的字符串中, # 1)匹配出wahaha,banana,qqxing内容。 # 2)匹配出a,b,h1这样的内容 # import re # ret = re.search("<(\w+)>([a-zA-Z]+)</(\w+)>","<asf>asfkj</asfd>") # #第一问 # l1 = ret.group(2) # print(l1) # #第二问 # l2 = ret.group(1) # print(l2) #第九题 # 9、1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) # 1)从上面算式中匹配出最内层小括号以及小括号内的表达式 # import re # l1 = "1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))" # print(re.findall(r'\([^()]+\)',l1)) # #第十题: # 10、从类似9-2*5/3+7/3*99/4*2998+10*568/14的表达式中匹配出从左到右第一个乘法或除法 import re # str1 = "9-2*5/3+7/3*99/4*2998+10*568/14" # l1 = re.search("\d+(\.\d)?(?:\*|\/)\d+(\.\d)?","9-2*5/3+7/3*99/4*2998+10*568/14") # print(l1.group())
贪婪匹配:正则会尽量的帮我们匹配
默认贪婪,回溯算法
非贪婪匹配:会尽量少为我们匹配
量词? 表示非贪婪,惰性匹配
.*?x 表示匹配任意长度的字符遇到x就停止
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
re 模块下的常用方法
import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(ret)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号