无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
第一种:UDF (User-Defined-Function)函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF (User-Defined Aggregation Function)聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
第三种:UDTF (User-Defined Table-Generating Functions)函数
一对多的关系,输入一个值输出多个值(一行变为多行)﹔
用户自定义生成函数,有点像flatMap;
1. SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
2. UDF定义支持2种方式,
1:使用SparkSession对象构建.
2:使用functions包中提供的UDF API构建.要注意,方式1可用DSL和SQL风格,方式2仅可用于DSL风格
3. SparkSQL支持窗口函数使用,常用SQL中的窗口函数均支持,如聚合窗口\排序窗口\NTILE分组窗口等
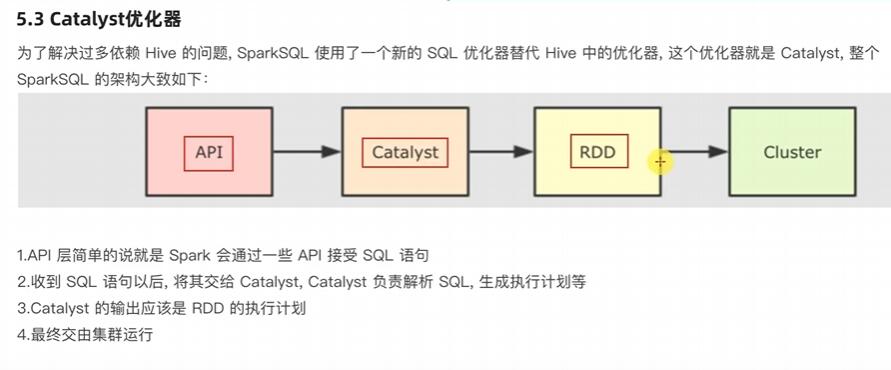
SparkSQL的执行流程:
1.提交SparkSQL代码
2.catalyst优化
a.生成原始AST语法数
b.标记AST元数据
c.进行断言下推和列值裁剪以及其它方面的优化作用在AST上
d.将最终AST得到,生成执行计划
e.将执行计划翻译为RDD代码
3.Driver执行环境入口构建(SparkSession)
4.DAG调度器规划逻辑任务
5.TASK调度区分配逻辑任务到具体Executor上工作并监控管理任务
6. Worker干活.
今日还完成了Spark On hive的配置以及使用了Datagrip来连接spark