SparkSQL?
1. SparkSQL用于处理大规模结构化数据的计算引擎
2. SparkSQL在企业中广泛使用,并性能极好,学习它不管是工作还是就业都有很大帮助
3. SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接
4. SparkSQL 2014年正式发布,当下使用最多的2.0版Spark发布于2016年,当下使用的最新3.0办发布于2019年
SparkSQL的数据抽象?
Pandas -DataFrame 二维表数据结构。单机(本地)集合
SparkCore - RDD ·无标准数据结构,存储什么数据均可·分布式集合(分区)
SparkSQL - DataFrame 二维表数据结构。分布式集合(分区)
sparkSQL其实有3类数据抽象对象
SchemaRDD对象(已废弃)
DataSet对象:可用于Java、Scala语言
DataFrame对象:可用于Java、Scala、Python、R
我们以Python开发SparkSQL,主要使用的就是DataFrame对象作为核心数据结构
1. SparkSQL和 Hive同样,都是用于大规模SQL分布式计算的计算框架,均可以运行在YARN之上,在企业中广泛被应用
2. SparkSQL的数据抽象为: SchemaRDD(废弃)、DataFrame (Python、R.Java、Scala) . DataSet (Java、scala)。
3. DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数据结构是以表格形式组织的,方便进行SQL计算
4. DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让Java、Scala语言更好的利用到。
5. SparkSession是2.0后退出的新执行环境入口对象,可以用于RDD、SQL等编程
完成小案例:
# coding:utf8
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("test").master("local[*]").getOrCreate()
sc = spark.sparkContext
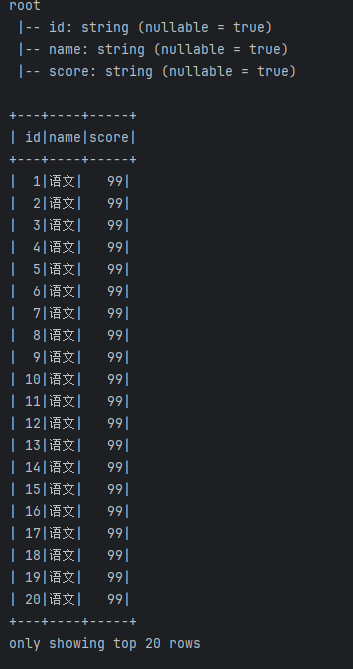
df = spark.read.csv("../data/stu_score.txt",sep=',',header=False)
df2 = df.toDF("id","name","score")
df2.printSchema()
df2.show()
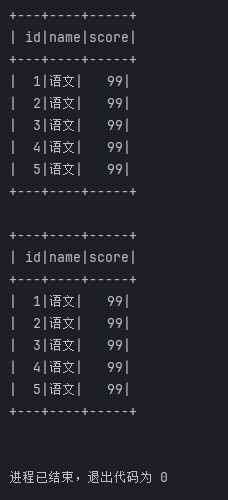
df2.createTempView("score")
spark.sql("""
select * from score where name = '语文' limit 5
""").show()
df2.where("name='语文'").limit(5).show()