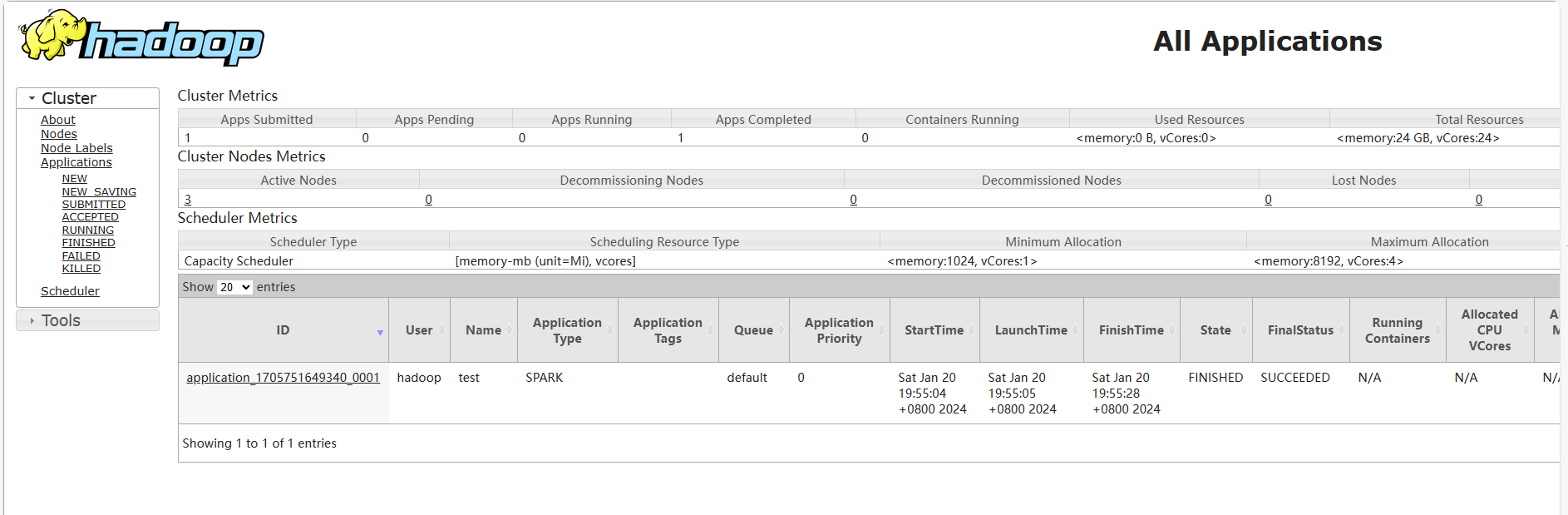
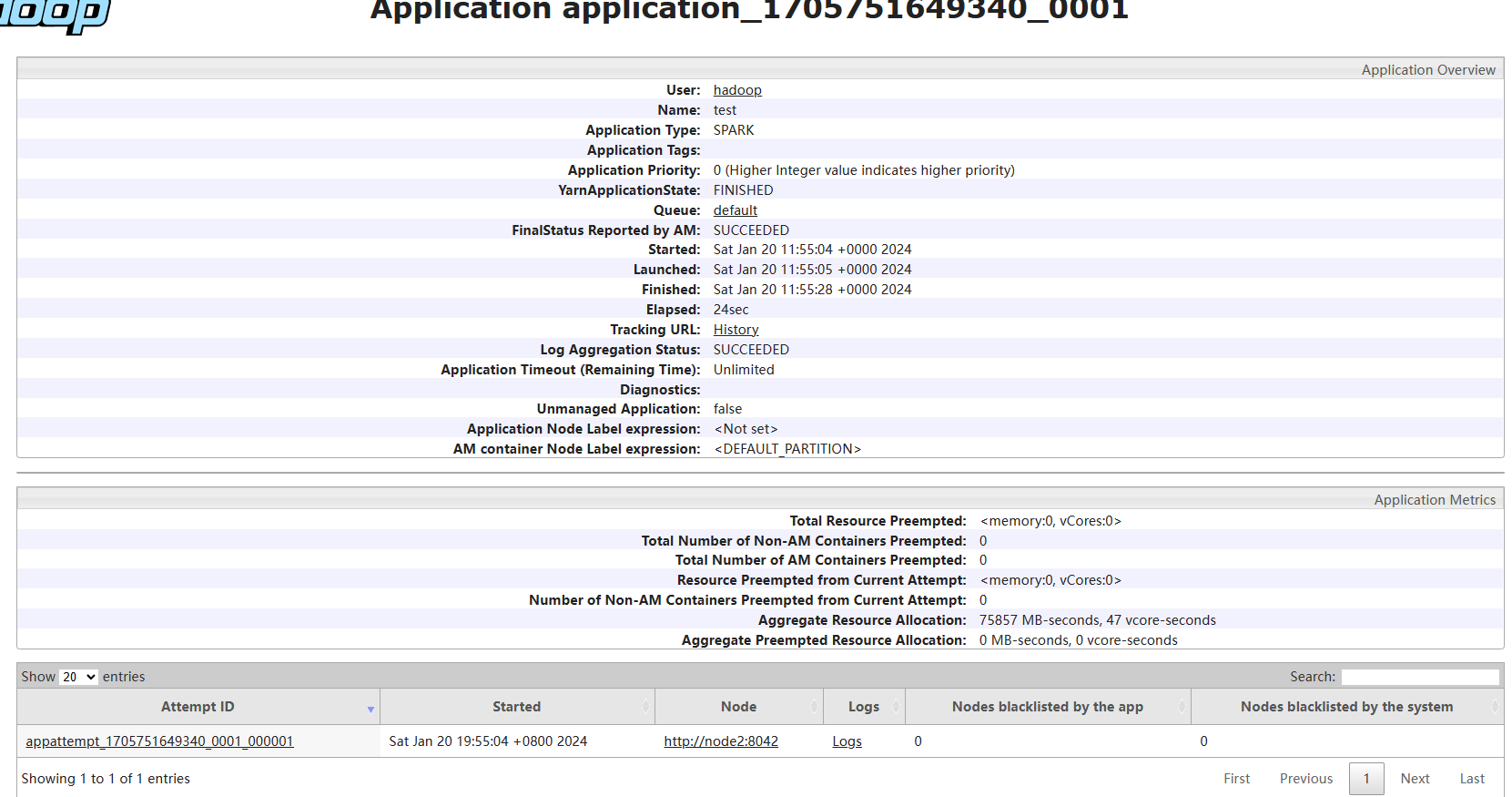
完成了搜索引擎日志分析小案例
数据由两万条一下六列相同格式的单个数据组成 分别对应:搜索时间 用户ID 搜索内容 URL返回排名 用户点击顺序 用户点击的URL
使用到了python的jieba插件进行热词的分析
TODO: 需求1: 用户搜索关键‘词’分析
需求1结果: [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)]
0号元素为搜索热词,1号元素为搜索次数,上述为搜索前五的数据
TODO: 需求2: 用户和关键词组合分析1
需求2结果: [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('7044693659960919_数据', 1120), ('7044693659960919_仓库', 1120)]
0号元素为用户ID_搜索热词,1号元素为搜索次数
TODO: 需求3: 热门搜索时间段分析
需求3结果: [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365), ('10', 973), ('11', 875), ('05', 798), ('02', 756), ('19', 735), ('12', 644), ('14', 637), ('00', 504), ('16', 497), ('08', 476), ('04', 476), ('03', 385), ('09', 371), ('15', 350), ('06', 294), ('13', 217), ('18', 112), ('17', 77), ('07', 70)]
0号元素为小时,1号元素为搜索次数
原码(jieba_demo.py):
# coding:utf8
import json
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from operator import add
import defs
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("test")
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("../data/SogouQ.txt")
split_rdd = file_rdd.map(lambda line: line.split("\t"))
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO: 需求1: 用户搜索关键‘词’分析
# 主要分析热点词
# 将所有搜索内容取出
# print(split_rdd.takeSample(True,3)) 抽样取出检查
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索内容进行分词分析
word_rdd = context_rdd.flatMap(defs.context_jieba)
# print(word_rdd.collect()) 院校帮 博学谷 传智播客
filtered_rdd = word_rdd.filter(defs.filter_words)
final_word_rdd = filtered_rdd.map(defs.append_word)
result1 = final_word_rdd.reduceByKey(lambda a, b: a + b).sortBy(lambda x:x[1],ascending=False,numPartitions=1).take(5)
print("需求1结果:", result1)
# TODO: 需求2: 用户和关键词组合分析1
# 1 我喜欢清华大学
# 1+我 1+喜欢 1+清华大学
user_context_rdd = split_rdd.map(lambda x:(x[1], x[2]))
user_word_with_one_rdd = user_context_rdd.flatMap(defs.extrect_usr_and_word)
result2 = user_word_with_one_rdd.reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False,numPartitions=1).take(5)
print("需求2结果:", result2)
# TODO: 需求3: 热门搜索时间段分析
time_rdd = split_rdd.map(lambda x:x[0])
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(":")[0], 1))
result3 = hour_with_one_rdd.reduceByKey(add).sortBy(lambda x: x[1],ascending=False,numPartitions=1).collect()
print("需求3结果:", result3)
函数附件(defs.py):
# coding:utf8
import jieba
def context_jieba(data):
"""通过jieba分词工具 进行分词操作"""
seg = jieba.cut_for_search(data)
l = list()
for i in seg:
l.append(i)
return l
def filter_words(data):
return data not in ['谷','帮','客']
def append_word(data):
if data == '博学': data = '博学谷'
if data == '传智播': data = '传智播客'
if data == '院校': data = '院校帮'
return (data,1)
def extrect_usr_and_word(data):
user_id = data[0]
content = data[1]
words = context_jieba(content)
return_list = []
for word in words:
if filter_words(word):
return_list.append((user_id + '_' +append_word(word)[0],1))
return return_list
除此之外完成了将该代码提交到yarn集群中运行:
1.删除代码中setMaster部分
2.将文件上传路径修改为HDFS储存路径