

ZooKeeper(一):基础介绍
什么是 ZooKeeper?
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务。ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
ZooKeeper 发展历史
ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协同,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就开发了一个通用的无单点问题的分布式协调框架,这就是 ZooKeeper。ZooKeeper 之后在开源界被大量使用,下面列出了 3 个著名开源项目是如何使用 ZooKeeper:
- Hadoop:使用 ZooKeeper 做 Namenode 的高可用。
- HBase:保证集群中只有一个 master,保存 hbase:meta 表的位置,保存集群中的 RegionServer 列表。
- Kafka:集群成员管理,controller 节点选举。

ZooKeeper 应用场景
很多分布式协调服务都可以用 ZooKeeper 来做,其中典型应用场景如下:
- 配置管理(configuration management):如果我们做普通的 Java 应用,一般配置项就是一个本地的配置文件,如果是微服务系统,各个独立服务都要使用集中化的配置管理,这个时候就需要 ZooKeeper。
- DNS 服务
- 组成员管理(group membership):比如上面讲到的 HBase 其实就是用来做集群的组成员管理。
- 各种分布式锁
ZooKeeper 适用于存储和协同相关的关键数据,不适合用于大数据量存储。如果要存 KV 或者大量的业务数据,还是要用数据库或者其他 NoSql 来做。
为什么 ZooKeeper 不适合大数据量存储呢?主要有以下两个原因:
- 设计方面:ZooKeeper 需要把所有的数据(它的 data tree)加载到内存中。这就决定了ZooKeeper 存储的数据量受内存的限制。这一点 ZooKeeper 和 Redis 比较像。一般的数据库系统例如 MySQL(使用 InnoDB 存储引擎的话)可以存储大于内存的数据,这是因为 InnoDB 是基于 B-Tree 的存储引擎。B-tree 存储引擎和 LSM 存储引擎都可以存储大于内存的数据量。
- 工程方面:ZooKeeper 的设计目标是为协同服务提供数据存储,数据的高可用性和性能是最重要的系统指标,处理大数量不是 ZooKeeper 的首要目标。因此,ZooKeeper 不会对大数量存储做太多工程上的优化。
ZooKeeper 服务的使用
要使用 ZooKeeper 服务,首先我们的应用要引入 ZooKeeper 的客户端库,然后我们客户端库和 ZooKeeper 集群来进行网络通信来使用 ZooKeeper 的服务,本质上是 Client-Server 的架构,我们的应用作为一个客户端来调用 ZooKeeper Server 端的服务。
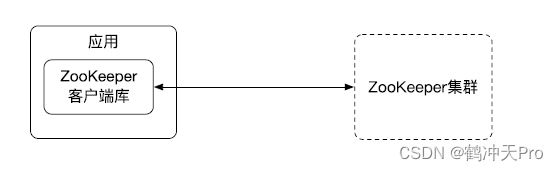
ZooKeeper 数据模型
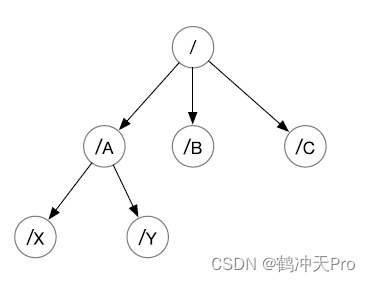
ZooKeeper 的数据模型是层次模型。层次模型常见于文件系统。层次模型和 key-value 模型是两种主流的数据模型。ZooKeeper 使用文件系统模型主要基于以下两点考虑:
- 文件系统的树形结构便于表达数据之间的层次关系。
- 文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace)。
ZooKeeper 的层次模型称作 data tree。Data tree 的每个节点叫做 znode。不同于文件系统,每个节点都可以保存数据。每个节点都有一个版本(version),版本从 0 开始计数。
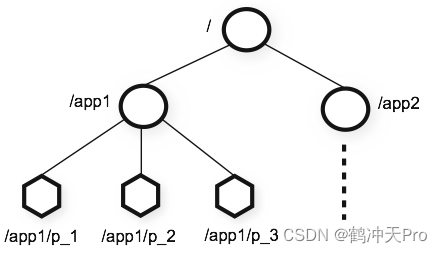
如上图所示的 data tree 中有两个子树,一个用于应用 1(/app1)和另一个用于应用 2(/app2)。
应用 1 的子树实现了一个简单的组成员协议:每个客户端进程 pi 创建一个 znode p_i 在 /app1 下,只要 /app1/p_i 存在就代表进程 pi 在正常运行。
data tree 接口
ZooKeeper 对外提供一个用来访问 data tree的简化文件系统 API:
- 使用 UNIX 风格的路径名来定位 znode,例如 /A/X 表示 znode A 的子节点 X。
- znode 的数据只支持全量写入和读取,没有像通用文件系统那样支持部分写入和读取。
- data tree 的所有 API 都是 wait-free 的,正在执行中的 API 调用不会影响其他 API 的完成。
- data tree 的 API都是对文件系统的 wait-free 操作,不直接提供锁这样的分布式协同机制。但是 data tree 的 API 非常强大,可以用来实现多种分布式协同机制。
znode 分类
一个 znode 可以是持久性的,也可以是临时性的,znode 节点也可以是顺序性的。每一个顺序性的 znode 关联一个唯一的单调递增整数,因此 ZooKeeper 主要有以下 4 种 znode:
- 持久性的 znode (PERSISTENT): ZooKeeper 宕机,或者 client 宕机,这个 znode 一旦创建就不会丢失。
- 临时性的 znode (EPHEMERAL): ZooKeeper 宕机了,或者 client 在指定的 timeout 时间内没有连接 server,都会被认为丢失。
- 持久顺序性的 znode (PERSISTENT_SEQUENTIAL): znode 除了具备持久性 znode 的特点之外,znode 的名字具备顺序性。
- 临时顺序性的 znode (EPHEMERAL_SEQUENTIAL): znode 除了具备临时性 znode 的特点之外,znode 的名字具备顺序性。
总结
这篇文章主要介绍了ZooKeeper 的基本概念、发展历史和应用场景,并详细介绍了ZooKeeper 数据模型,为后面更加深入的学习打好基础。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!