
特征工程和模型融合--机器学习--思维导图和笔记
特征工程和模型融合--机器学习--思维导图和笔记
一、思维导图(点击图方法)
二、补充笔记
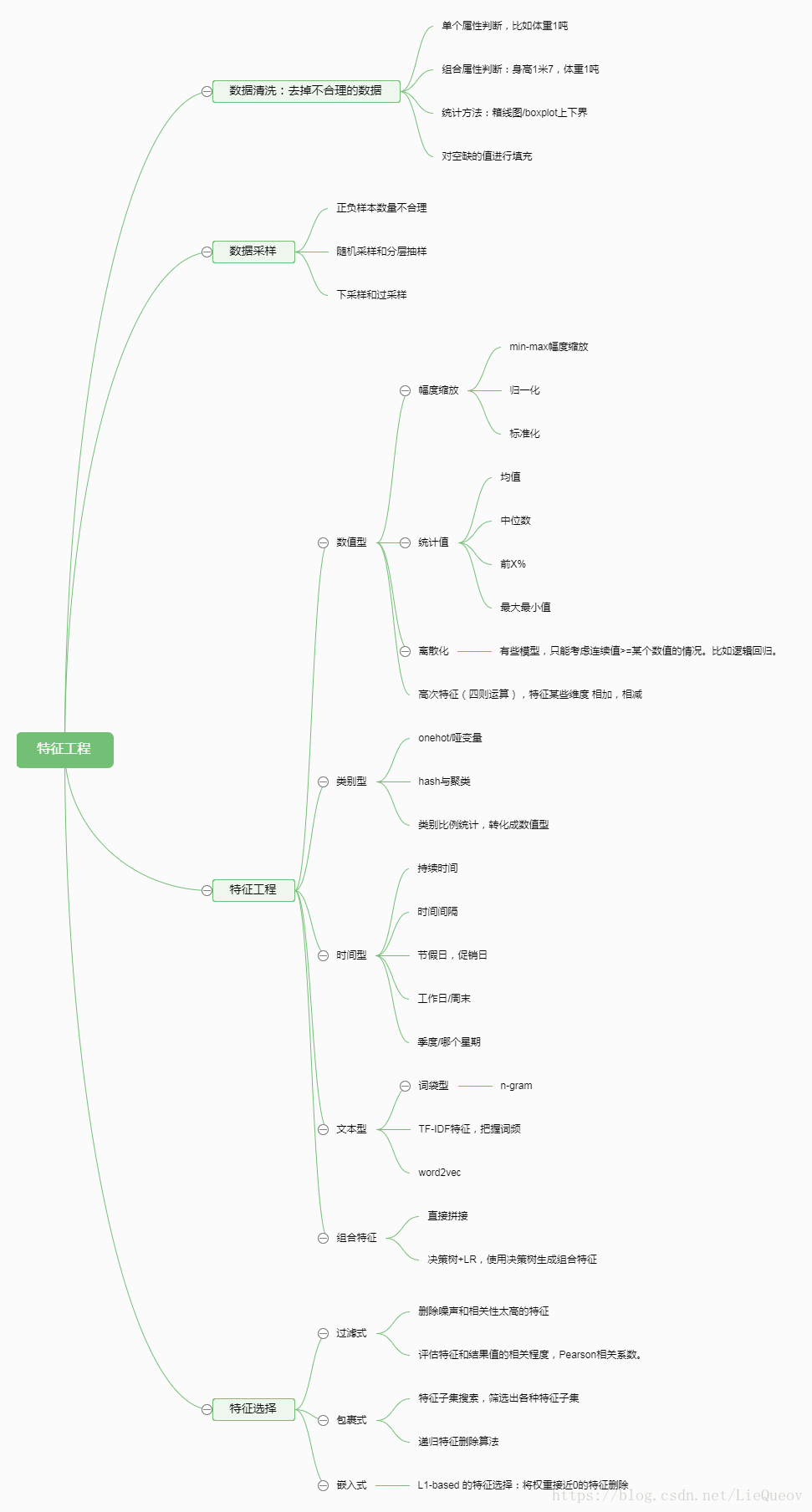
(1)常见的特征工程主要指对各种类型的特征进行处理,包括数值型特征、类别型特征、时间型特征和其他类型特征和组合特征。对于数值型特征,可以进行幅度调整(包括min-max缩放、标准化、归一化)、统计值分析(最大值、最小值、平均值等)、离散化、高次特征、通过特征的四则运算获取新特征、或将数值型特征转换为类别型。对于类别型特征,可以进行one-hot编码(也叫哑变量)、hash技巧、分桶映射等。对于时间型特征,既可以看成连续值,也可看成离散值。当为连续值的时候,可以计算持续时间、间隔时间。看成离散值的时候,可以得到比如这个日期是工作日还是休息日等。对于其他类型,比如文本型特征,可以使用词袋模型、TF-IDF模型、word2vec模型等转换成向量形式。对于组合特征,将两个或者多个特征直接拼接就可,或者采用树模型产生特征组合的路径。
(2)特征选择的方法包括过滤式,包裹式和嵌入式。过滤式的特征选择,通过Pearson相关系数、互信息等指标,将单特征和结果的相关性进行评估,来对特征进行选择。包裹式的特征选择,是将特征选择转化为从所有特征集合中选择出最优的特征子集。一般采用递归特征删除算法,根据模型的预测结果,删除一些特征。嵌入式的特征选择,是进行L1正则化后,会发现有些特征的权重近乎为0,那么认为就认为这些特征对结果没有贡献,可以将这些特征删除。
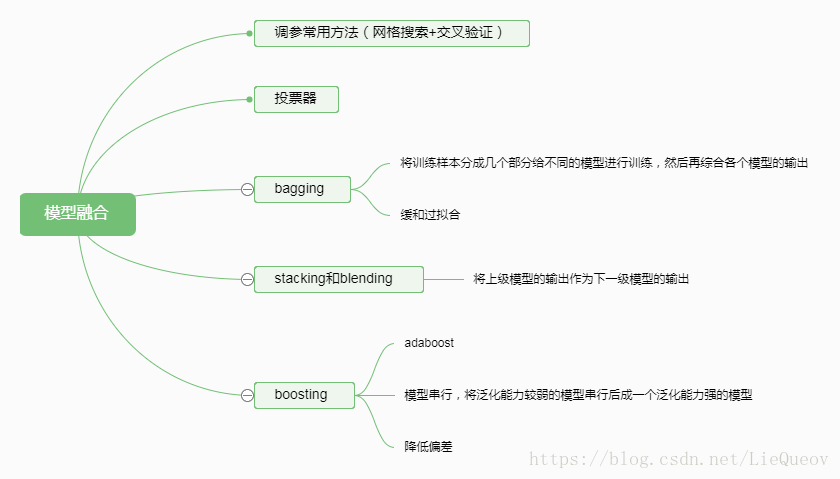
(3)常见的模型融合方法包括,投票器、Bagging、stacking、blending和boosting。投票器是采取少数服从多数的思想,如果是分类问题,将所有模型的输出进行投票,得票高的那一类就为模型的总输出。Bagging是将进行采样后,分成几个部分,每个部分训练一个模型,最后将这些模型的输出集合起来。Stacking使用上层的模型输出作为下一层模型的输入,Blending是弱化版的Stacking,相当于对上层模型的输出进行了线性加权。Boosting是将泛化能力较弱的模型串行集成起来,生成一个泛化模型强的模型。

