弱监督学习总结(1)
弱监督学习总结(1)
前言:
目前深度学习可谓是资本宠儿,各路大牛公司均加入深度学习军备竞赛,百度最早成立人工智能研究院,接着腾讯的AI研究所和阿里的达摩院,均是投入血本进行深度研发,不仅是人才的竞争,还有数据/计算能力和应用项目落地的竞争。大公司在竞争,小公司也不甘示弱,每天都能看到新的AI公司在成立,招兵买马大干一场,这也是一场残酷的战争。
在学习过Udacity和吴恩达的deeplearning课程之后,我对深度学习又有了新的一些看法。确实,深度学习在语音/图像和自然语言方面相比传统算法有长足的进步,很多方面的识别率超过人类水平,于是各路媒体大肆渲染深度学习算法的神奇之处,说着说着就将深度学习算法和人工智能混为一谈,认为再过不久,人类很快就被机器所代替。
其实,这些宣传是非常不谨慎的,计算机确实在某些领域能有很高的准确率,但相比人类来说,它们在逻辑推理,组合,分析方面的能力是远远不够智能的,更不用谈它们能创新创造。在我看来,人类巨大的脑容量所连接的海量神经元绝对是自然赐予人类最宝贵的财富,它的复杂程度比世界上运算量最大的计算机还高出好几个指数级,大脑的学习/思考/分析/创造能力是远非机器所能比拟的,我觉得只有更深入的了解物质组成的本质,比如量子理论和量子计算的发展,才能让计算机比拟人类能力,获得更强大的能力。而目前的深度神经网络只是在结构上借鉴了大脑的神经元结构,但真正具体的神经元工作原理以及如何去实现复杂的分析推理工作连人类自己都不得而知,更谈不上让机器人代替人类做出复杂的决策,让机器人去学习难以用逻辑推理去定义的情感。
之所以说这些想法,是因为太多人谈到深度学习就是人工智能,其实这个发展过程是十分漫长的。研究人工智能,这不仅仅是让人类生活的更轻松,而且还能认识到人类的本质,至少是我们对于自身理性逻辑思维方面的深刻认识,但千万不要太迷信深度学习,也不要将深度学习和人工智能混为一谈。
什么是弱监督学习?
一般常常谈到深度学习,就是根据数据特点,选择合适模型(CNN.RNN)等去训练模型,让模型自己寻找数据特征,构造合适损失函数并优化到最小值,得到的模型参数就是我们需要的结果,这个过程一般称为(强)监督学习。而这个过程中有一个问题,在日常生活中会有大量的数据,但给数据都加上标签(label)成本太高,我们得想办法既能降低成本,又能得到更准确的模型,这个时候弱监督学习就闪亮登场了。
弱监督学习是相对于强监督学习和无监督学习来说的,当我们得到的数据集之中只有一部分数据有标签,而另一部分数据没有标签,但我们还是想训练一个不错的模型(穷且傲娇),我们称其为弱监督学习,利用这非常规的数据集来训练模型,到底该咋办呢?
分类
弱监督学习一般可以根据数据类型分为三类:
- 不完整监督学习(incomplete supervised learning):数据中只有一部分由标记
- 不确切监督学习(inexact supervised learning):数据中标记数据粗粒度太大
- 不准确监督学习(inaccurate supervised learning):数据中标签错误
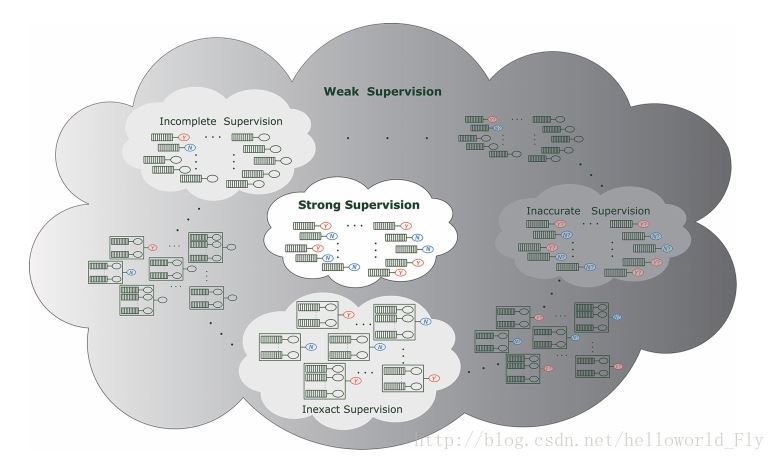
不完整监督学习
数据既然不完整,那我们只能想办法根据这有限的数据来训练模型了,前人学霸们都做了哪些研究呢?我们来瞧一瞧。
主动学习(active learning)
- 思路:提取数据样本中最有价值的样本进行标记,性价比最高!(我没钱就找几个有用的数据打标签,能提高一点是一点)
说白了,就是在成本有限的情况下找出模型预测最容易出错的数据打上标签,将打上标签后的数据继续放入模型训练,直到得到满意的模型。
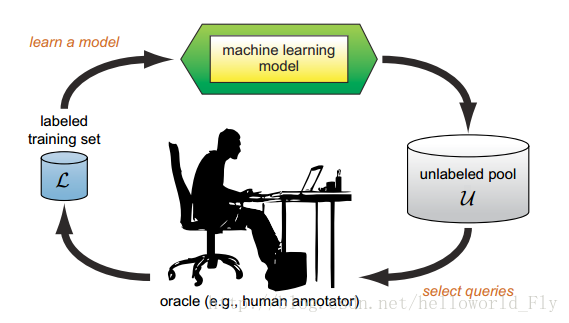
-
核心问题:如何寻找最有价值标签?通过何种方式标记?
-
常用方法:最笨——从头开始;第二笨——按顺序给出;第三种——选出易错点,利用熵值或者多样性评判;(说白了,就像小学生复习考试,那些题老是错才值得多花时间练习,如果从头开始复习,可能没多久就去王者荣耀或者吃鸡了,哪还有那闲工夫慢慢磨机)
-
理论:informativeness (最大程度降低统计分布误差)和representiveness(最大化展现输入数据的模式),前者例如高斯混合模型,但过于依赖模型输入的概率分布方式;后者比如聚类,过于依赖数据的输入模式)
主动学习的思想,是在人类一定的干预之下提高模型的效果,但设计的特征方式均需要人类大量的先验知识,也就是想设计出不错的模型,你可能得是个“砖家”!
这次先记录这么多,其实主动学习属于传统的建模学习方法,相比于深度学习可能没有那么神奇,但将主动学习的思想加入深度学习之中,可能就能有效的解决实际问题,比如CVPR2017会议中这篇论文:https://www.jianshu.com/p/42801f031cfa,很简单的方法但对于实际问题十分有效,更重要的是作者对于问题清晰和准确的定义和分析,不单单是建立一个模型和复杂的损失函数,而是对模型训练中出现的多种情形进行了总结分析,给出了不错的指导意见,十分有效!
下篇接着讲弱监督学习中的半监督学习,这部分涉及方法非常广泛,也非常有趣。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号