

XGBoost入门及实战
kaggle比赛必备算法XGBoost入门及实战
xgboost一直在kaggle竞赛江湖里被传为神器,它在对结构化数据的应用占据主导地位,是目前开源的最快最好的工具包,与常见的工具包算法相比速度提高了10倍以上!
XGBoost is an implementation of gradient boosted decision trees (GBDT) designed for speed and performance.
xgboost 是对梯度增强决策树(GBDT)的一种实现,具有更高的性能以及速度,既可以用于分类也可以用于回归问题中。本文将尽量用通俗易懂的方式进行介绍并给出实战案例。
1.什么是XGBoost?
xgboost 是 eXtreme Gradient Boosting的简写。
The name xgboost, though, actually refers to the engineering goal to push the limit of computations resources for boosted tree algorithms. Which is the reason why many people use xgboost.
以上是xgboost作者陈天奇在Quora(类似国内的知乎)上对名字的解释。
xgboost是一个软件包,可以通过各种API接口访问使用:
- Command Line Interface (CLI).命令行
- C++
- Java
- R
- python 和 scikit-learn
- Julia
- Scala
xgboost 的底层实现在我看来还是比较复杂的,想深入理解可以查看陈博士的Paper (XGBoost: A Scalable Tree Boosting System) ,它针对传统GBDT算法做了很多细节改进,包括损失函数、正则化、稀疏感知算法、并行化算法设计等等。
Szilard Pafka 数据科学家做了详细的性能对比,并发表的文章进行解释说明(githup:https://github.com/szilard/benchm-ml) 以下是 XGBoost 与其它 gradient boosting 和 bagged decision trees 实现的效果比较,可以看出它比 R, Python,Spark,H2O 中的基准配置要更快。

2.XGBoost的特性
说到Xgboost,不得不先从GBDT(Gradient Boosting Decision Tree)说起。因为xgboost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted,两者都是boosting方法。
Gradient Boosting 是 boosting 的其中一种方法,所谓 Boosting ,就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法。
那什么是GBDT??我们看一张图:
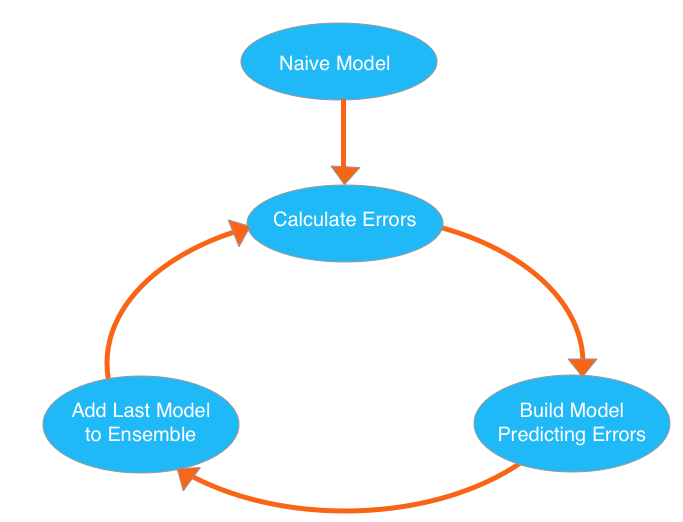
GBDT的原理很简单,我们反复循环构建新的模型并将它们组合成一个集成模型的,从初始Naive模型开始,我们从计算数据集中每个观测的误差,然后下一个树去拟合误差函数对预测值的残差(残差就是预测值与真实值之间的误差),最终这样多个学习器相加在一起用来进行最终预测,准确率就会比单独的一个要高。
之所以称为 Gradient,是因为在添加新模型时使用了梯度下降算法来最小化的损失。
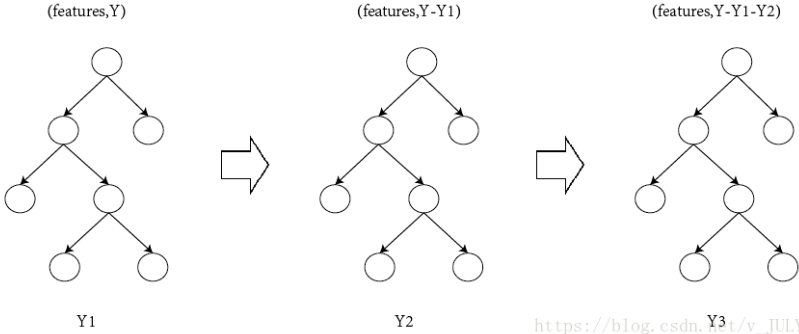
如图所示:Y = Y1 + Y2 + Y3。
Parallelization并行处理
XGBoost工具支持并行处理。Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是 tree 粒度的并行,XGBoost 也是一次迭代完才能进行下一次迭代的。
XGBoost的并行是在特征粒度上的,决策树的学习最耗时的一个步骤就是对特征的值进行排序,XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
正则化
XGBoost 在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的 score 的L2模的平方和。从Bias-variance tradeoff 角度来讲,正则项降低了模型的 variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
缺失值处理
对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
损失函数
传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。
分布式计算
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework. XGBoost provides a parallel tree boosting (also known as GBDT, GBM) that solve many data science problems in a fast and accurate way.
3.实战示例
官方指导文档:
https://xgboost.readthedocs.io/en/latest/index.html
github 示例文档:
https://github.com/dmlc/xgboost/tree/master/demo/guide-python
本文将继续使用kaggle竞赛平台上的房价预测的数据,具体数据请移步kaggle实战之房价预测,了解一下?
准备数据
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import Imputer
data = pd.read_csv('../input/train.csv')
data.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = data.SalePrice
X = data.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object'])
train_X, test_X, train_y, test_y = train_test_split(X.as_matrix(), y.as_matrix(), test_size=0.25)
my_imputer = Imputer()
train_X = my_imputer.fit_transform(train_X)
test_X = my_imputer.transform(test_X)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
构建模型
#引入xgboost
from xgboost import XGBRegressor
#xgboost 有封装好的分类器和回归器,可以直接用XGBRegressor建立模型
my_model = XGBRegressor()
# Add silent=True to avoid printing out updates with each cycle
my_model.fit(train_X, train_y, verbose=False)
- 1
- 2
- 3
- 4
- 5
- 6
评估及预测
# make predictions
predictions = my_model.predict(test_X)
from sklearn.metrics import mean_absolute_error
print("Mean Absolute Error : " + str(mean_absolute_error(predictions, test_y)))
- 1
- 2
- 3
- 4
- 5
模型调参
xgboost模型参数有几十种,以上我们只是使用的默认的参数进行训练预测,参数详解请参照:
Parameters (official guide)
XGBoost有几个参数会显著影响模型的准确性和训练速度,你应该需要特别关注,并适当的进行调参:
#1. n_estimators
n_estimators指定通过建模周期的次数,可以理解成迭代次数,值太大会导致过度拟合,这是对训练数据的准确预测,但对新数据的预测偏差很大。一般的范围在100-1000之间。
#2.early_stopping_rounds
这个参数 early_stopping_rounds 提供了一种自动查找理想值的方法,试验证分数停止改进时停止迭代。
我们可以为 n_estimators 设置一个较高值,然后使用 early_stopping_rounds来找到停止迭代的最佳时间。
my_model = XGBRegressor(n_estimators=1000)
#评价模型在测试集上的表现,也可以输出每一步的分数 verbose=True
my_model.fit(train_X, train_y, early_stopping_rounds=5,
eval_set=[(test_X, test_y)], verbose=True)
#[0] validation_0-rmse:181513
#Will train until validation_0-rmse hasn't improved in 5 rounds.
#[1] validation_0-rmse:164369
#[2] validation_0-rmse:149195
#[3] validation_0-rmse:135397
#[4] validation_0-rmse:123108
#[5] validation_0-rmse:111850
#[6] validation_0-rmse:102150
#[7] validation_0-rmse:93362.6
#[8] validation_0-rmse:85537.3
#[9] validation_0-rmse:78620.8
#[10] validation_0-rmse:72306.5
#[11] validation_0-rmse:67021.3
#[12] validation_0-rmse:62228.3
# XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
# colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
# max_depth=3, min_child_weight=1, missing=None, n_estimators=1000,
# n_jobs=1, nthread=None, objective='reg:linear', random_state=0,
# reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
# silent=True, subsample=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
当使用 early_stopping_rounds 参数时,您需要留出一些数据来检查要使用的轮数,从以上实例代码可以看出 n_estimators=1000 为停止迭代次数。
#3.learning_rate
以下是一个小技巧但很重要,可用于训练更好的xgboost模型:
一般来说,一个较小的 learning_rate(和较大的 n_estimators )将产生更精确的xgboost 模型,由于该模型在整个循环中进行了更多的迭代,因此它也需要更长的时间来训练。
我们用 GridSearchCV 来进行调整 learning_rate 的值,以找到最合适的参数:
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
# 设定要调节的 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
my_model= XGBRegressor(n_estimators=1000)
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(my_model, param_grid, n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(train_X, train_y)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
#Best: 0.285843 using {'learning_rate': 0.01}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
#4.n_jobs
在运行时的较大数据集上,可以使用并行性更快地构建模型,通常将参数n_jobs设置为机器上的CPU的数量。对于较小的数据集,这个参数没有任何作用。
可视化XGBoost树
训练完模型后, 一般只是看看特征重要性(feature importance score),但是 XGBoost提供了一个方法plot_tree(),使得模型中每个决策树是可以画出来看看的。
import matplotlib.pyplot as plt
from xgboost import plot_tree
plot_tree(my_model,num_trees=0)
#设置图形的大小
plt.rcParams['figure.figsize'] = [50, 20]
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以得到以下这个的图,plot_tree有些参数可以调整, 比如num_trees=0表示画第一棵树,rankdir='LR’表示图片是从左到右(Left to Right)。
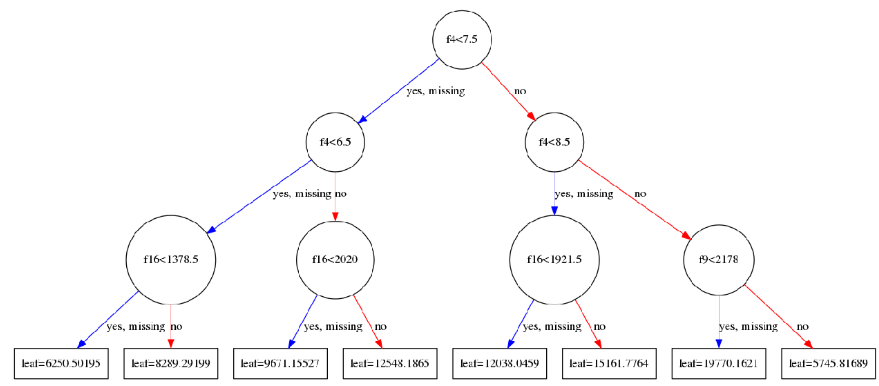
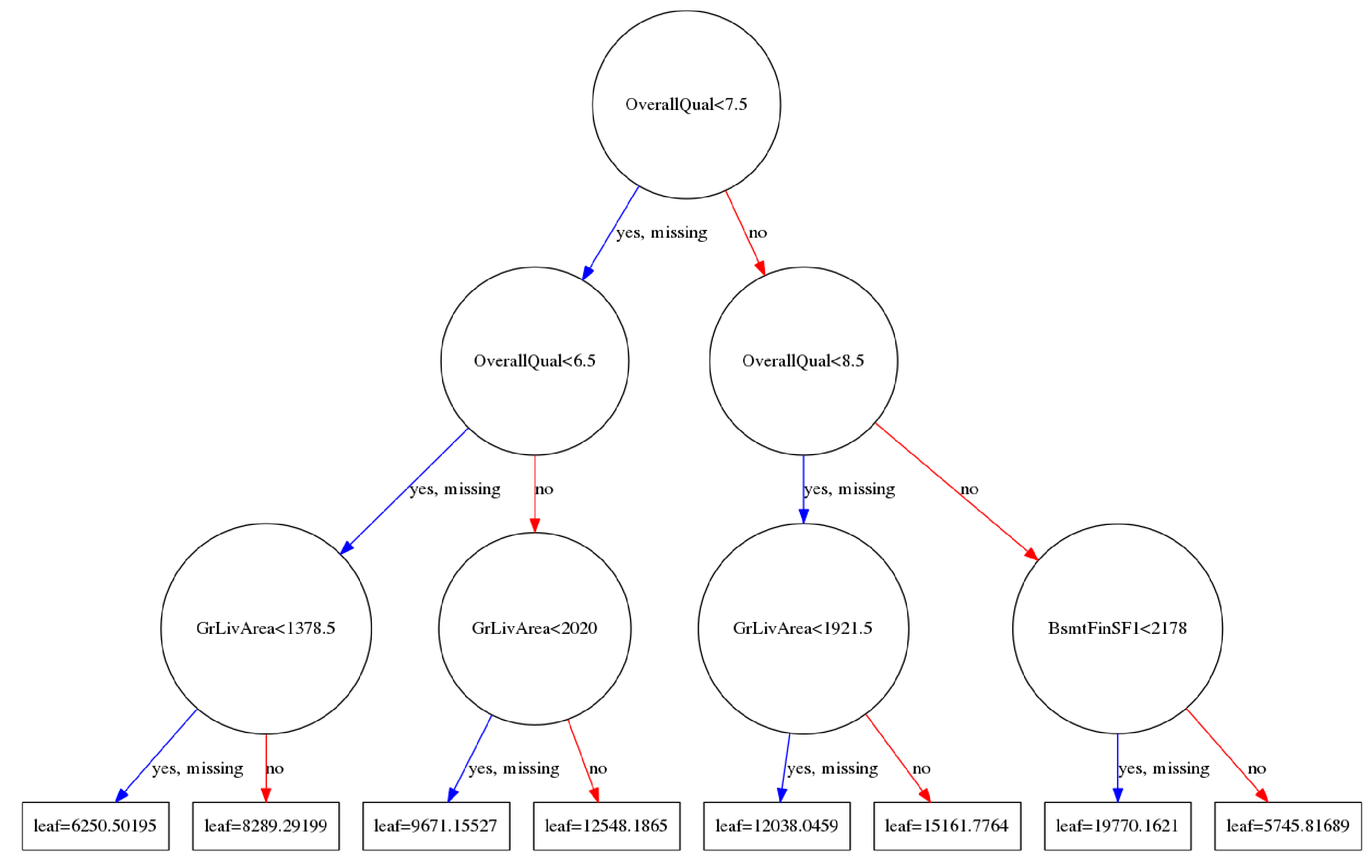
上图中f1,f2是feature ID,需要进行转换成特征属性显示:
#这个函数就是根据给定的特征名字(我直接使用了数据的列名称), 按照特定格式生成一个xgb.fmap文件
def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1
outfile.close()
ceate_feature_map(X.columns)
#在调用plot_tree函数的时候, 直接指定fmap文件即可
plot_tree(my_model,num_trees=0,fmap='xgb.fmap')
plt.rcParams['figure.figsize'] = [50, 20]
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可视化XGBoost模型的另一种方法是显示模型中原始数据集中每个要属性的重要性,XGBoost有一个 plot_importance() 方法,可以展示特征的重要性。
from xgboost import plot_importance
plot_importance(my_model)
plt.rcParams['figure.figsize'] = [10, 10]
plt.show()
- 1
- 2
- 3
- 4
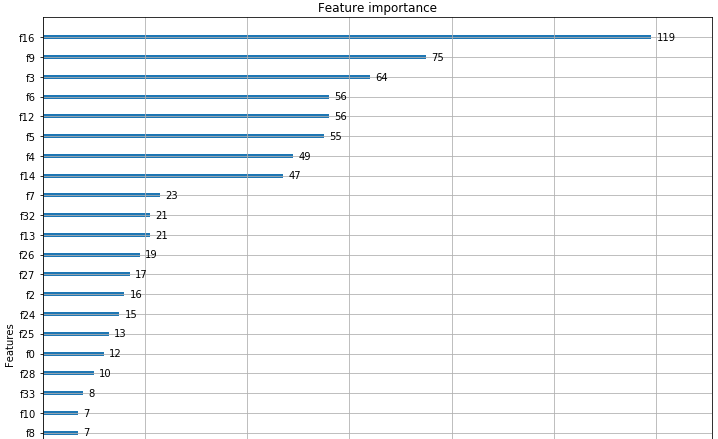
从图中可以看出,特征属性 f16 - GrLivArea得分最高,可以展示特征的重要性。因此,XGBoost还为我们提供了一种进行特征选择的方法!!
4.参考资料
1.xgboost作者讲义PPT:https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
2.xgboost入门与实战(原理篇):https://blog.csdn.net/sb19931201/article/details/52557382
3.史上最详细的XGBoost实战:https://zhuanlan.zhihu.com/p/31182879
4.一文读懂机器学习大杀器XGBOOST原理
5.A Gentle Introduction to XGBoost for Applied Machine Learning

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步